Исследователи из FAIR опубликовали имплементацию state-of-the-art голосовой модели, которая способна разделять до 5 голосов на аудиозаписи разговора.
Прошлые методы разделения голосов на аудиозаписи были ограничены максимум двумя спикерами. Предложенная модель обходит state-of-the-art в качестве разделения и в количестве спикеров, чьи голоса может выделить.
Подробнее про модель
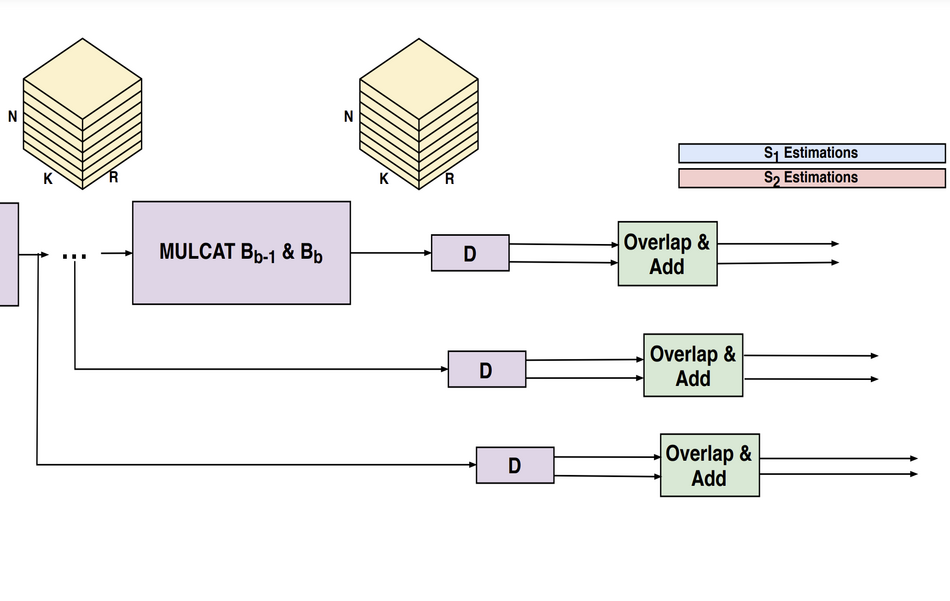
Ключевая идея подхода — обучать разную модель для каждого возможного количества спикеров и выбирать ту, что выступает лучше всего среди остальных. Базовая архитектура модели — это gated сверточная нейросеть, которая принимает на вход аудиоволну. Аудиоволна свертывается на этапе кодирования с помощью 1D сверток и делится на части по времени. Каждая пара частей идет на вход рекуррентной нейросети (RNN). Итоговый результат получают с помощью применения другой свертки и изменения порядков чанков (частей аудиозаписи).
Тестирование подхода
Исследователи оценивали работу модели на двух датасетах: WSJ0-2mix и WSJ0-3mix. Кроме того, датасет WSJ-mix расширили и добавили аудио с разговором 4 и 5 людей. Так получились датасеты WSJ0-4mix и WSJ0-5mix. По результатам экспериментов, модель обходит альтернативные подходы на задаче разделения голосов 2-5 спикеров.
В открытом доступе есть Pytorch имплементация метода.
