
Команда исследователей из NVIDIA, MIT и других институтов представила LongLive — фреймворк для генерации длинных видео в реальном времени, которые позволяет управлять сюжетом по ходу создания ролика. В отличие от традиционных моделей, требующих один детальный промпт на всё видео сразу, LongLive позволяет последовательно вводить новые текстовые инструкции, меняя направление повествования, добавляя новые объекты или корректируя визуальный стиль прямо во время генерации. В экспериментах исследователи использовали переключения промптов каждые 10 секунд, хотя технически модель поддерживает частоту смену инструкций каждые 5 секунд.

Модель построена на покадровой авторегрессивной архитектуре и достигает 20.7 FPS на одном GPU NVIDIA H100, поддерживая генерацию видео длительностью до 240 секунд. Дообучение модели с 1.3 миллиарда параметров для генерации минутных видео заняло 32 GPU-дня. Исследователи применили механизм повторного кэширования ключей и значений (KV-recache) для плавного переключения между промптами без резких визуальных скачков, потоковое обучение на длинных последовательностях (streaming long tuning) и внимание с коротким окном в сочетании с якорными кадрами (frame-level attention sink) для ускорения инференса. Код для обучения и инференса, веса модели и демо-страница с примерамим опубликованы в открытом доступе на GitHub
А LongLive построен на базе модели Wan2.1-T2V-1.3B. Исследователи применили к ней дообучение с использованием собственных методов: повторного кэширования ключей и значений, потокового обучения на длинных последовательностях и внимания с коротким окном в сочетании с якорными кадрами. Для обучения требуются значительные вычислительные ресурсы — 64 GPU H100 на 12 часов (32 GPU-дня), в то время как для инференса достаточно одного H100 GPU.
Архитектура и ключевые компоненты
LongLive построен на базе модели Wan2.1-T2V-1.3B, которая генерирует 5-секундные клипы с частотой 16 FPS и разрешением 832×480. Авторы адаптировали предобученную модель в frame-level авторегрессивную архитектуру с каузальным вниманием, что позволяет использовать KV-кэширование для эффективного инференса.
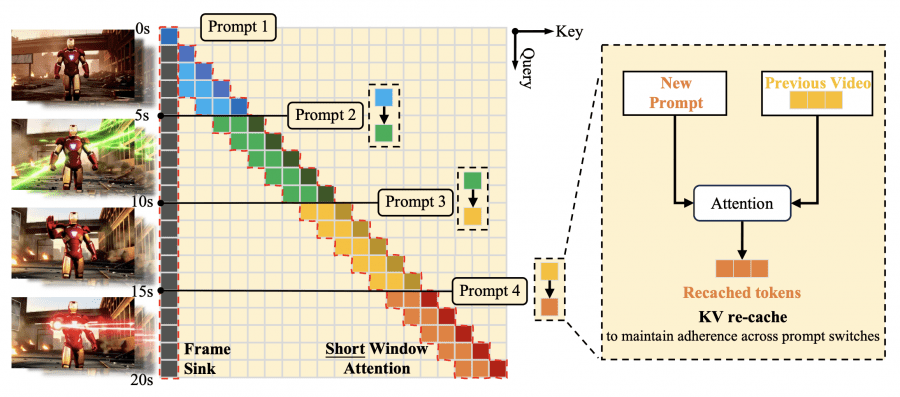
KV-recache механизм
При переключении промптов модель пересчитывает кэш ключей и значений, комбинируя уже сгенерированные кадры с новыми промпт-эмбеддингами через слои перекрестного внимания. Это устраняет остаточную семантику предыдущего промпта, сохраняя визуальную непрерывность движений. Эксперименты подтверждают, что полная очистка кэша приводит к резким визуальным разрывам: Background Consistency 92.75, Subject Consistency 89.59, сохранение старого кэша вызывает задержку в следовании новому промпту: CLIP Score 25.92, а KV-recache достигает оптимального баланса: Background Consistency 94.81, Subject Consistency 94.04, CLIP Score 27.87.

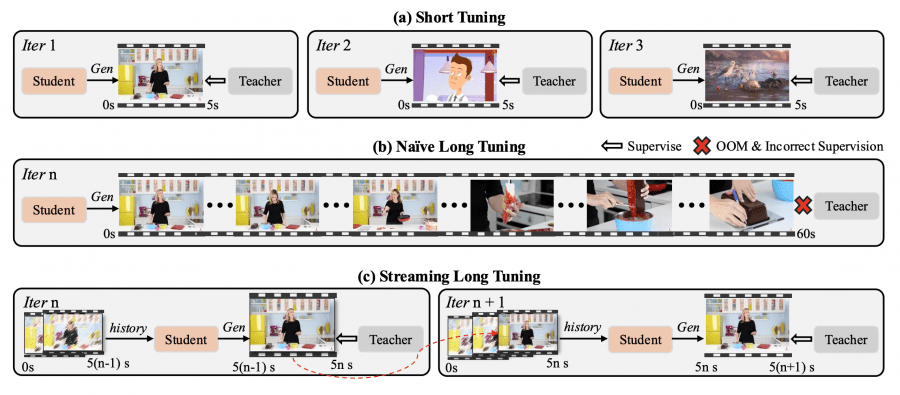
Streaming long tuning — стратегия обучения, устраняющая несоответствие между train-short–test-long режимами. На каждой итерации модель генерирует следующий 5-секундный клип, используя сохранённый KV-кэш из предыдущей итерации, и применяет DMD (Distribution Matching Distillation) только к новому клипу. Процесс повторяется до достижения максимальной длины (60 или 240 секунд). Учительская модель Wan2.1-T2V-14B предоставляет надёжный supervision для текущего клипа, уже созданные кадры исключаются из вычислений, что предотвращает переполнение памяти.
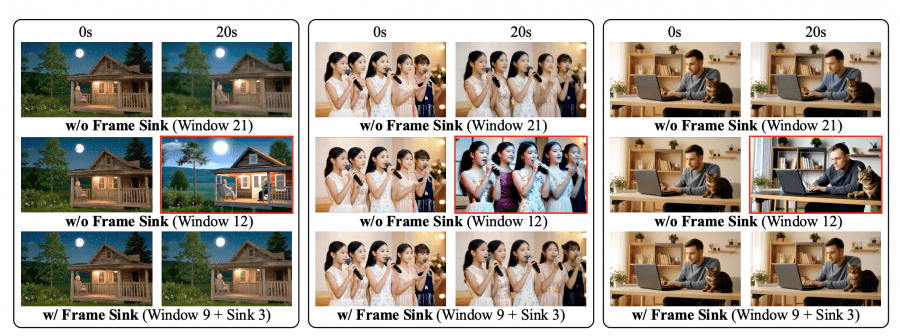
Короткое окно внимания и frame sink радикально сокращают вычислительные затраты. Локальное окно внимания ограничено 9 латентными кадрами вместо стандартных 21, при этом первый чанк из 3 латентных кадров закрепляется как frame sink — глобальные токены, постоянно доступные для внимания во всех слоях. Аблация на 20-секундных видео показывает, что short window без frame sink снижает Consistency Score до 90.6 при окне в 12 кадров, тогда как добавление frame sink восстанавливает показатель до 94.1 при эффективном окне всего в 12 кадров (9 локальных + 3 sink). Это даёт 28% ускорение времени инференса и 17% снижение пиков потребления памяти на одном H100 GPU.
Результаты
Короткие видео (VBench). LongLive демонстрирует качество на уровне лучших базовых моделей при максимальной скорости генерации — 20.7 FPS, что в 26 раз быстрее диффузной модели Wan2.1 и в 42 раза быстрее SkyReels-V2.
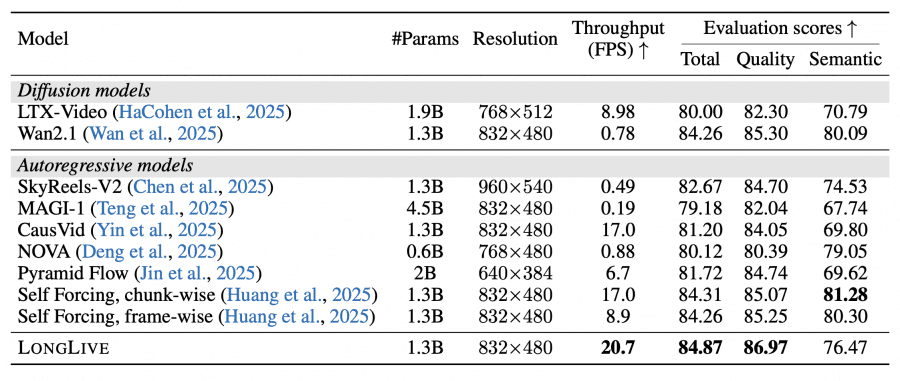
Длинные видео 30 секунд (VBench-Long). LongLive лидирует по общему качеству, сохраняя высокую скорость генерации (таблица 3, страница 8).
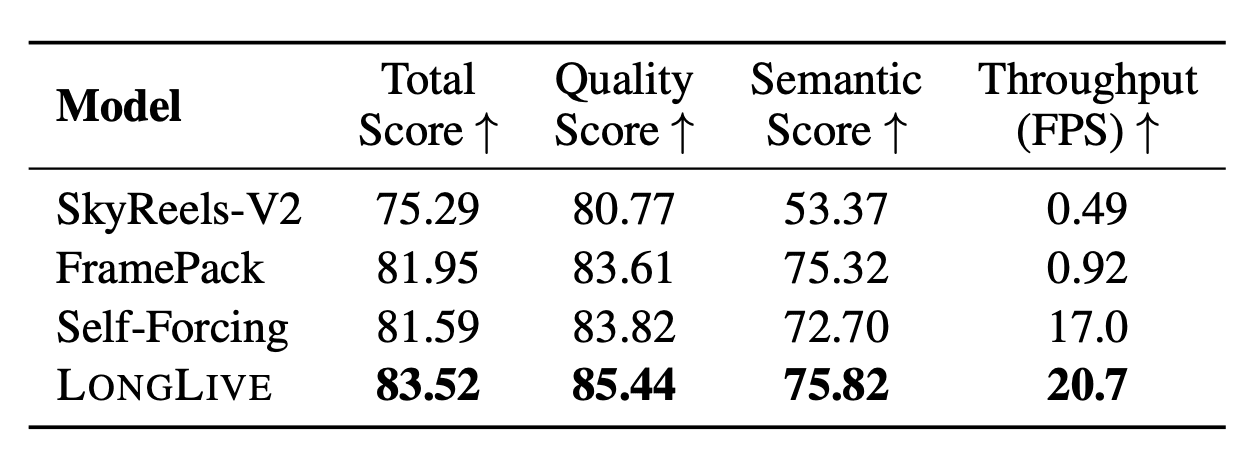
Интерактивная генерация 60 секунд. Для оценки интерактивного режима исследователи создали датасет из 160 видео с шестью последовательными переключениями промптов. LongLive показывает стабильное следование инструкциям на протяжении всего ролика, тогда как у конкурентов наблюдается более значительная деградация. Пользовательское исследование с 26 участниками по четырём критериям (общее качество, качество движения, следование инструкциям, визуальное качество) подтверждает преимущество LongLive.

Эффективность обучения
Дообучение модели с 1.3 миллиарда параметров для генерации 60-секундных видео занимает 12 часов на 64 H100 GPU (32 GPU-дня). Применение LoRA с ранком 256 делает обучаемыми только 27% параметров (350 миллионов из 1.3 миллиарда), снижая требования к памяти на 73% по сравнению с полным дообучением.
Квантизация. INT8-квантизация сжимает модель с 2.7 ГБ до 1.4 ГБ и ускоряет инференс с 12.6 до 16.4 FPS на NVIDIA 5090 GPU с минимальным падением качества.
LongLive масштабируется до 240-секундных видео на одном H100 GPU, сохраняя высокую визуальную точность и темпоральную когерентность.








