
Нет сомнений в том, что разработка алгоритмов реалистичного ретуширования лица является растущей темой для исследований в сообществах компьютерного зрения и машинного обучения. Некоторые примеры включают устранение эффекта «красных глаз», удаление дефектов, где использовались смеси распределений Пуассона для создания правдоподобных результатов. Однако люди очень чувствительны даже к небольшим ошибкам в структуре лица, особенно если это их или хорошо известные лица. Кроме того, так называемая «Зловещая долина» является существенным препятствием.
За последнее время глубокие свёрточные сети (DNN) показали качественные результаты при восстановлении картин с пейзажами. Для конкретной проблемы лицевых деформаций они учатся не только сохранять такие свойства, как глобальное освещение и тон кожи, но также могут кодировать некоторое представление семантического правдоподобия.
Недавнее исследование FAIR фокусируется на проблеме реконструкции глаз. Хотя DNN могут производить семантически правдоподобные реалистичные результаты, даже самые глубокие модели не учитывают личность человека на фотографии. Например, DNN может научиться открывать пару закрытых глаз, но нет гарантий, заложенных в самой модели, что новые глаза будут соответствовать конкретной окулярной структуре индивидуального человека. Вместо этого DNN вставляют пару глаз, которая соответствует похожим лицам в тренировочном наборе, что приводит к нежелательным и предвзятым результатам. Если у человека есть отличительная особенность (например, необычная форма глаз), это не будет отражено в сгенерированной части.
Генерирующие состязательные сети (GAN) — это особый тип глубоких сетей, которые содержат обучаемую функцию потерь, представленную сетью дискриминатора. GAN успешно используется для создания лиц с нуля или для восстановления недостающих областей лица. Они особенно хорошо подходят для общих задач, связанных с манипуляциями с лицом, поскольку дискриминатор использует образы реальных лиц, чтобы направлять генератор на создание выборок, которые возникают из данного истинного распределения.
Архитектура ExGan
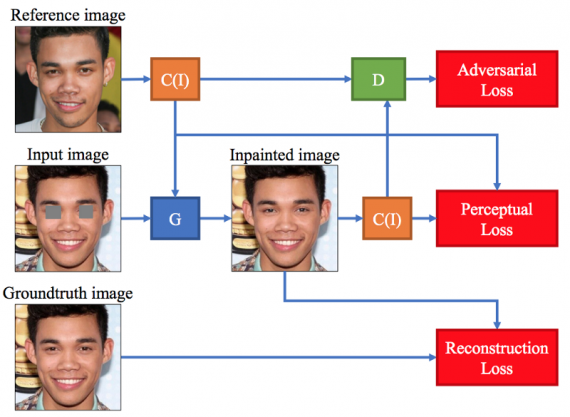
Вместо того, чтобы полагаться на сеть для генерации изображений, основанной только на данных из обучающего набора, ExGAN используют второй источник информации, чтобы направлять генератор по мере создания изображения. По мере создания большего количества наборов данных и получения большего количества изображений в интернете, разумно предположить, что существует второе изображение определенного объекта. Например, при восстановлении лица, дополнительной информацией может быть второе изображение того же человека, полученное в другое время или в другой позе. Однако вместо того, чтобы непосредственно использовать дополнительную информацию для создания изображения (например, используя соседние пиксели для синтеза текстуры или путем копирования пикселей непосредственно со второй фотографии), сеть узнаёт, как включить эту информацию в качестве семантического руководства для создания правдоподобных результатов. Следовательно, GAN учится использовать вспомогательные данные, сохраняя при этом все характеристики исходной фотографии.
Исследователи FAIR представили два отдельных подхода к ExGAN восстановлению. Первый основан на восстановлении с использованием дополнительного изображения ri, которое используется в генераторе в качестве руководства, или в дискриминаторе в качестве дополнительной информации (при определении является реальным или подделкой сгенерированное изображение). Второй подход основан на использовании (перцептивного) кода при восстановлении, где для субъекта, представляющего интерес, создается код восприятия ci. Для восстановления глаз этот код хранит сжатую версию глаза человека в векторе ci ∈ RN, который также может использоваться в нескольких разных местах в сетях генератора и дискриминатора.
Восстановление с использованием дополнительного изображения. Предположим, что для каждого изображения в обучающем наборе xi существует соответствующее ему дополнительное изображение ri. Таким образом, обучающий набор X определяется как набор пар X = {(x1, r1), … , (xn, rn)}. В задаче восстановления глаз ri — ещё одно изображение человека из xi, но потенциально полученное в другой позе. Фрагменты изображения удаляются из xi для создания zi, а функция потерь определяется как:
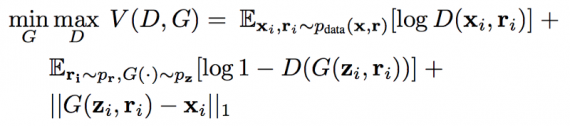
Для лучшего обобщения также может быть использован набор опорных изображений Ri, соответствующий заданному xi. Он расширяет обучающий набор до набора кортежей, и состоит из декартова произведения между каждым изображением подлежащим восстановлению и его дополнительным набором изображений X = {x1 × R1, … , xn × Rn}.
Использование кода при восстановлении. Пусть количество пикселей в каждом изображении равно |I|. Предположим, что существует сжимающее отображение C(r): R^|I| → R^N, где N<<|I|(по сути просто encoder). Затем для каждого изображения zi, которое должно быть восстановлено, и соответствующего ему дополнительного изображение ri генерируется код ci = C(ri). Учитывая закодированную информацию, мы определяем состязательную функцию потерь как:
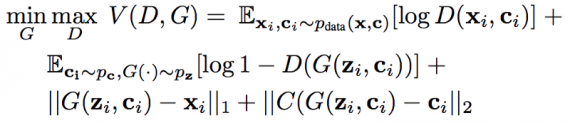
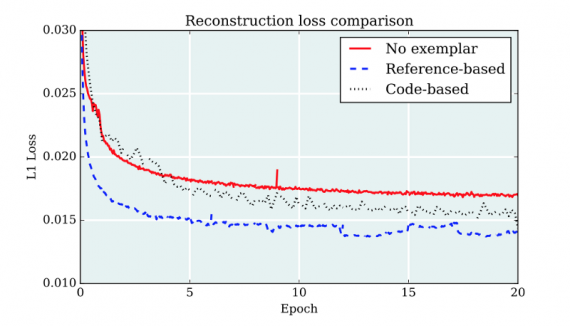
В приведенной ниже таблице показаны количественные результаты для 3 лучших моделей GAN. Для всех метрик, кроме inception score, чем меньше, тем лучше.
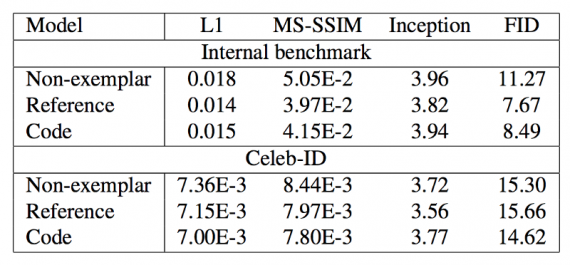
GAN представляют собой хорошее решение для генерации или восстановления изображений, когда область этого изображения имеет некоторые идентификационные признаки (некоторые отличительные черты). Они обеспечивают превосходные результаты восприятия, поскольку включают идентифицирующую информацию, хранящуюся в эталонных изображениях или перцептивных кодах. Яркий пример их возможностей продемонстрирован в задаче восстановления глаз. Поскольку Exemplar GAN представляют собой общую структуру, они могут быть распространены на другие задачи в области компьютерного зрения и даже на другие виды информации.
Результаты
На картинках приведено сравнение между (а) реальным фото, (b) результатами, полученными без примеров, и (c, d) результатами, использующими дополнительные изображения. ExGAN, который использует опорное изображение в генераторе и дискриминаторе, показан в колонке (с). ExGAN, который использует код, показан в колонке (d):



Результаты открытия глаз, восстановленные Exemplar GAN с использованием дополнительного изображения. В левом столбце показаны дополнительные изображения, а в правом результаты открытия глаз людей из центрального столбца, сгенерированные с помощью Exemplar GAN:


Перевод — Александр Сахнов, оригинал — Muneeb Ul Hassan.






