Исследователи из ByteDance и Университета Гонконга представили Mini-o3 — мультимодальную модель, которая выполняет глубокие многошаговые рассуждения для решения сложных задач визуального поиска. Mini-o3 достигает SOTA результатов на сложных бенчмарках, превосходя все существующие открытие модели и проприетарную GPT-4o, генерируя последовательности рассуждений длиной в десятки шагов с постепенным улучшением точности. Код моделей опубликован на Github и Huggingface, также исследователи выложили в открытый доступ датасеты обучения.
Существующие open-source VLM демонстрируют слабые результаты на задачах, требующих обучения методом проб и ошибок: лидер DeepEyes достигает только 35.1% точности на VisualProbe-Hard. В отличие от OpenAI o3, эти модели не способны генерировать разнообразные стратегии рассуждений (depth-first search, trial-and-error exploration, self-reflection) и глубокие последовательности рассуждений.
Архитектура и подход
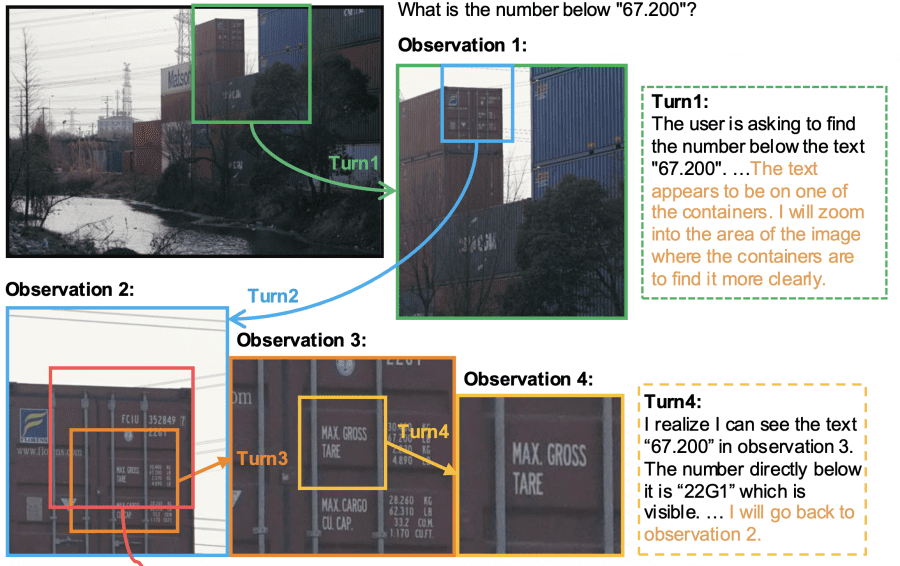
Mini-o3 построена на базе модели Qwen2.5-VL-7B-Instruct. Mini-o3 работает по итеративному принципу: модель политики (policy model) на каждом шаге генерирует два элемента — рассуждение (thought Ti) и действие (action Ai). Действие представляет собой команду для инструментов обработки изображений — например, увеличить определенную область изображения. После выполнения действия модель получает новый визуальный результат (observation Oi) — обработанный фрагмент изображения, который становится входными данными для следующего шага. Эта информация добавляется к накопленному контексту, и модель переходит к следующей итерации анализа. Процесс продолжается циклически (рассуждение → действие → визуальный результат) до тех пор, пока модель не найдет ответ на поставленный вопрос или не достигнет технических ограничений по длине контекста.
Компоненты архитектуры включают:
- Thought Ti: внутренний процесс рассуждения для выбора следующего действия на основе истории взаимодействия
- Action Ai: пространство действий включает две опции — локализация области (задается нормализованными координатами ограничивающей рамки в диапазоне [0,1]² для указания региона увеличения) и выдача финального ответа
- Observation Oi: изображение, полученное после выполнения Ai — обрезанный патч из оригинального изображения или предыдущего визуальный результат

Cбор данных и обучение модели
Процедура обучения состоит из двух фаз. Контролируемое дообучение (Supervised Fine-Tuning, SFT) обучает модель на тысячах многошаговых последовательностей с использованием инструментов обработки изображений для генерации корректных путей решения с разнообразными паттернами рассуждений. Обучение с подкреплением (Reinforcement Learning with Verifiable Rewards, RLVR) применяет алгоритм GRPO для оптимизации стратегии модели, где правильность ответов оценивается не простым сравнением строк, а с учетом семантического соответствия — для этого используется внешняя большая языковая модель в качестве арбитра.

Для сбора начальных данных исследователи создали датасет Visual Probe — 4,000 пар вопрос-ответ для обучения и 500 для тестирования с тремя уровнями сложности. Датасет отличается особой сложностью: искомые объекты занимают малую часть изображения, присутствует множество похожих элементов, которые могут ввести в заблуждение, а большой размер изображений требует тщательного многоэтапного анализа для поиска нужной информации. Для генерации данных исследователи использовали существующую визуально-языковую модель, которая способна обучаться на примерах прямо в процессе работы. Они подготовили небольшой набор эталонных примеров, демонстрирующих нужное поведение, и затем модель имитировала этот подход на новых задачах, последовательно генерируя рассуждения и действия для каждого шага решения.
Используя всего 6 эталонных примеров, исследователи смогли сгенерировать около 6,000 обучающих последовательностей, где каждая демонстрирует полный путь решения задачи визуального поиска.
Процесс работал так: они взяли 6 вручную созданных эталонных примеров, где показали, как модель должна пошагово решать задачи визуального поиска (с рассуждениями, действиями по увеличению областей изображения и т.д.). Затем использовали эти 6 примеров для few-shot промптинга существующей VLM модели. Модель, следуя этим образцам, генерировала аналогичные пошаговые решения для других пар изображение-вопрос из датасета. Из всех попыток отбирались только те последовательности решений, которые привели к правильному ответу — так получилось около 6,000 успешных обучающих последовательностей.
Over-turn Masking стратегия
Ключевая инновация Mini-o3 — техника маскирования незавершенных последовательностей (over-turn masking) для предотвращения штрафования ответов, которые превысили лимит шагов во время обучения. В стандартном алгоритме GRPO ответы, достигающие максимального количества шагов или превышающие лимит контекста, получают нулевую награду и после нормализации приобретают отрицательные преимущества (advantages).
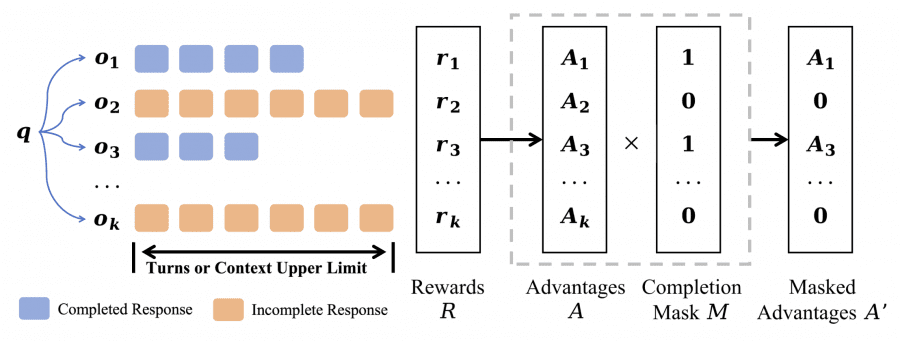
Исследователи разработали механизм, который различает два типа ответов модели: завершенные (когда модель успела найти решение в отведенное количество шагов) и незавершенные (когда лимит шагов исчерпан, но ответ не получен). В стандартном подходе незавершенные попытки автоматически считаются неудачными и штрафуются при обучении, что заставляет модель стремиться отвечать быстрее, даже если задача требует больше времени на анализ.
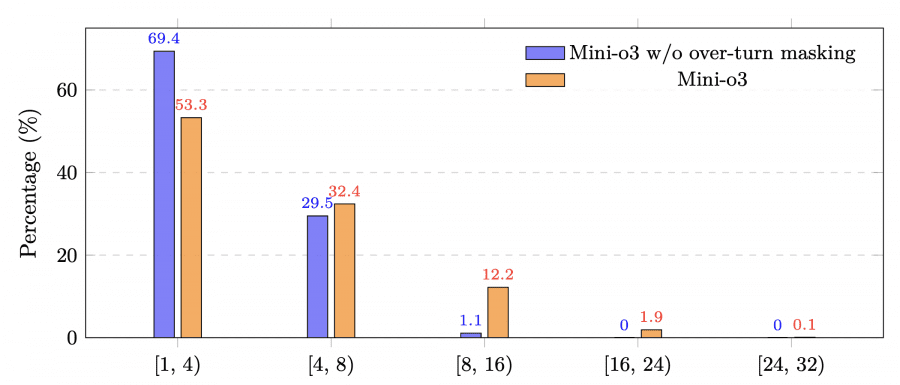
Новый подход работает иначе: незавершенные последовательности просто исключаются из процесса обучения — они не считаются ни правильными, ни неправильными. Модель учится только на тех примерах, где удалось дойти до конца и проверить правильность ответа. При вычислении градиентов учитываются только успешно завершенные попытки, что позволяет модели не бояться делать длинные цепочки рассуждений и не спешить с преждевременными выводами.
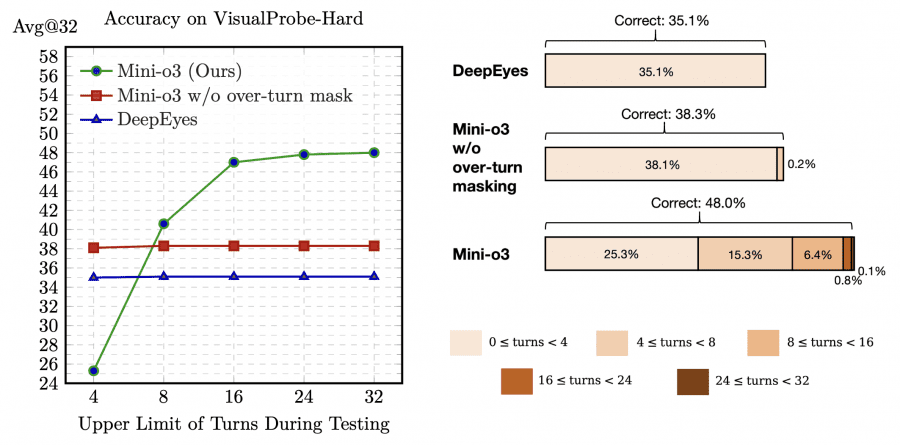
Эта техника критически важна для масштабирования количества шагов во время вывода: точность растет при увеличении длины последовательностей рассуждений до десятков итераций, хотя модель обучалась с ограничением всего в 6 шагов. Сокращение бюджета шагов при обучении с 16 до 6 уменьшает время тренировки с 10 дней примерно до 3 дней, практически не влияя на финальную точность при тестировании.
Результаты и производительность
Mini-o3 достигает state-of-the-art производительности на всех протестированных бенчмарах визуального поиска. На бенчмарке VisualProbe-Hard модель показывает 48.0% точности против 35.1% у DeepEyes и 28.8% у Pixel Reasoner. На V* Bench Mini-o3 достигает 88.2% (Avg@32), превосходя Chain-of-Focus с 88.0% (Avg@1). Результаты на HR-Bench-4K — 77.5%, а на MME-Realworld — 65.5%.
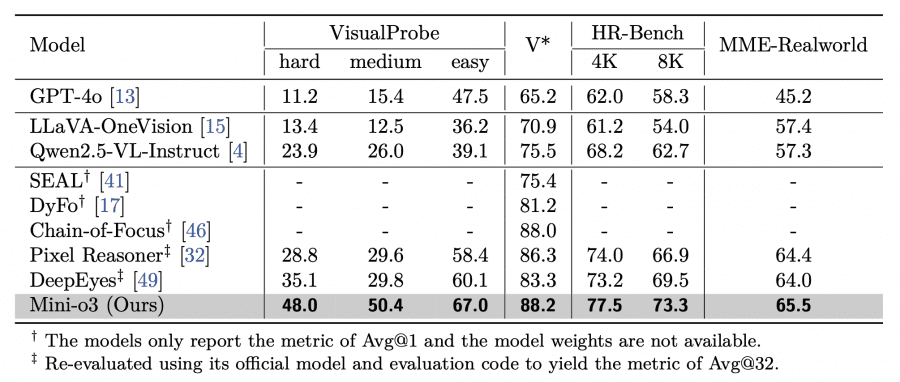
Важно отметить, что все перечисленные конкурирующие модели также имеют размер 7B параметров, что делает сравнение корректным. Превосходство Mini-o3 достигается не за счет увеличения размера модели, а благодаря инновационным подходам к обучению и архитектуре.
Технические детали реализации
Исследования с поэтапным отключением компонентов подтверждают важность каждого элемента архитектуры. Исключение сложных данных для обучения с подкреплением снижает производительность примерно на 8.6 процентных пунктов на датасете VisualProbe-Hard. Начальная донастройка абсолютно необходима — без нее модель вообще не способна решать задачи. Маскирование незавершенных последовательностей повышает стабильность обучения и позволяет модели адаптивно увеличивать количество шагов при решении особо сложных задач во время тестирования.
Оптимальное разрешение изображений составляет 2 миллиона пикселей — это дает 48.0% точности на VisualProbe-Hard против 36.1% при 12 миллионах пикселей. При слишком высоком разрешении модель останавливается преждевременно (в среднем делает только 1 шаг при 12M против 5.6 шагов при 2M), а при слишком низком — начинает «видеть» несуществующие детали.
Для начальной донастройки используется Qwen2.5-VL-7B-Instruct с максимальным разрешением 2M пикселей. Обучение проводится на примерно 6,000 сгенерированных примерах в течение 3 эпох со скоростью обучения 1×10⁻⁵. Для обучения с подкреплением применяется алгоритм GRPO с размером группы 16, коэффициентами отсечения 0.30/0.20 и постоянной скоростью обучения 1×10⁻⁶ без регуляризации KL-дивергенции или энтропии. Дополнительно к данным Visual Probe используется 8,000 примеров из DeepEyes-Datasets-47k для сохранения производительности на более простых задачах.
Mini-o3 показывает, что можно создать мультимодальные агенты с глубокими цепочками рассуждений, комбинируя сложные обучающие данные, эффективную генерацию начальных примеров и инновационную стратегию маскирования незавершенных последовательностей. При тестировании модель естественным образом масштабируется до десятков шагов анализа, открывая новые возможности для решения сложных визуальных задач, требующих итеративного исследования и подхода проб и ошибок.





