Группа исследователей из Google Research предложила нейросетевой метод для генерации изображений из текстов. По результатам экспериментов, модель обходит state-of-the-art подходы.
На чем обучали модель
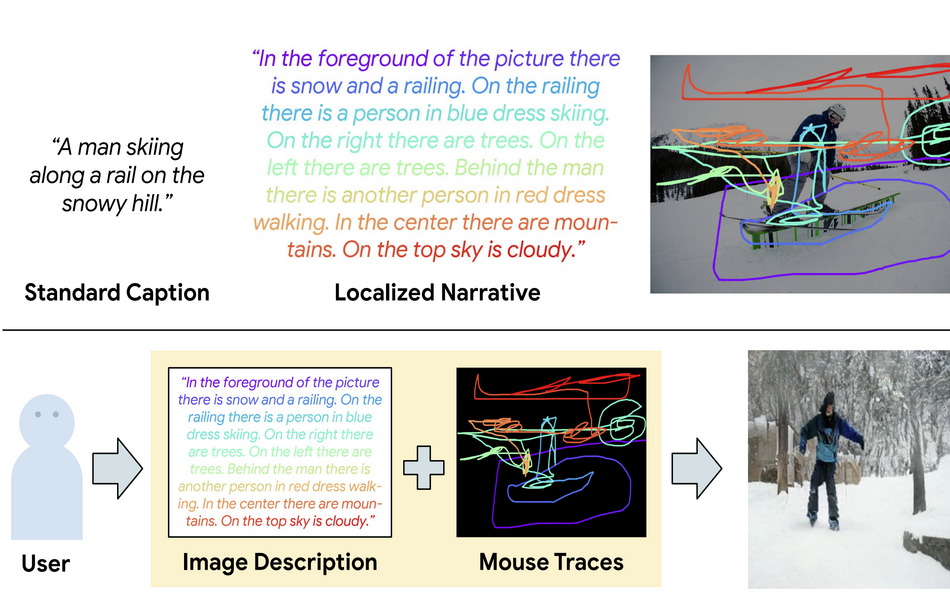
Исследователи разработали последовательную нейронную сеть, которую обучали на датасете Lozalized Narratives. Датасет является мультимодальным и содержит пары изображение и текстовое описание содержания изображения. Кроме того, в данных есть разметка положения курсора на изображении, которое соответствует текстовому описанию. Например, если на изображении и в текстовом описании есть яблоко, часть изображения с яблоком будет помечена.
Использование датасета позволило модели выучиться предсказывать появление отдельных объектов в частях изображения. Это упрощает задачу распознавания объектов и их локализации на изображении, что также упрощает соотнесение распознанных объектов с описанием.
Подробнее про модель
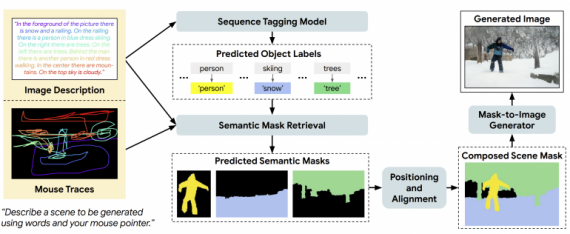
Предложенная TReCS использует данные для оценки предсказанных семантических маск объектов, последующего соотнесения и генерации итогового изображения.
Пайплайн работы модели состоит из следующих этапов:
- Разметка последовательности (Sequence Tagging), где отдельная модель извлекает сущности из входного описания и предсказывает классы объектов;
- На втором этапе разметка курсора мыши и текстовое описание подаются на вход Semantic Mask Retrieval модели, которая предсказывает маску сегментации для каждого распознанного на прошлом этапе объекта;
- На итоговом этапе семантические маски соотносятся в пространстве и модель Mask-to-Image генерирует итоговое изображение
Оценка работы модели
Исследователи тестировали модель качественно и количественно на датасете LC-COCO и сравнивали с state-of-the-art. В качестве качественной оценки использовали опрос добровольцев. Добровольцев просили проранжировать по достоверности результаты конкурирующих подходов. Для количественной оценки использовали метрики FID (Frechet Inception Distance) и Inception Score (IS). По результатам экспериментов, модель обходит прошлые нейросетевые архитектуры по качеству генерируемых изображений.
