
Команда исследователей из StepFun, Southern University of Science and Technology и Китайской академии наук опубликовала RealRestorer — открытую модель улучшения качества фотографий, которая умеет убирать размытость, шум, дождь, засветку от объектива, дымку, артефакты сжатия, муаровые паттерны и блики. На бенчмарке FoundIR с реальными парными снимками RealRestorer обогнал Nano Banana Pro по метрике PSNR — 21,45 дБ против 20,37 дБ. PSNR (Peak Signal-to-Noise Ratio, пиковое отношение сигнала к шуму) — метрика качества изображения, которая измеряет, насколько восстановленное изображение похоже на эталонное чистое. На практике разница в 1 дБ уже заметна на глаз — как разница между неплохим и отличным JPEG-сжатием. На бенчмарке RealIR-Bench модель занимает первое место среди открытых решений и вплотную подходит к закрытым аналогам — отставание от Nano Banana Pro всего 0,007 балла.
Проект частично открытый: код доступен под лицензией Apache 2.0, но веса модели и датасет RealIR-Bench доступны только для некоммерческих академических исследований. Веса, бенчмарк и код опубликованы на GitHub и Hugging Face.
В чём проблема существующих подходов
Большинство предыдущих моделей восстановления обучались на синтетических парах «деградированное изображение → чистое изображение». Синтетику делать легко — берем чистую фотографию, искусственно ухудшаем ее, например, добавляем искусственный шум с помощью алгоритма, и пара готова. Но реальный шум с телефона или реальная размытость от движения выглядят иначе, чем та, что алгоритм сгенерировал по формуле. Модель учится на одном распределении данных, тестируется на другом, поэтому результат получается неудовлетворительным.
Закрытые модели — GPT-Image-1.5 или Nano Banana Pro — обошли эту проблему, обучившись на огромных датасетах с реальными деградированными изображениями. Но их веса и данные закрыты — воспроизвести их нельзя, и исследователи не могут использовать их как основу для своей работы. RealRestorer решает эту проблему: авторы построили масштабный открытый датасет и дообучили на нём открытую базовую модель.
Откуда взялись данные для обучения
Это самая интересная техническая часть. Авторы собрали датасет из 1,65 миллиона пар изображений для девяти типов деградации, используя два принципиально разных подхода.
RealRestorer тоже использует синтетические данные — причём в очень большом объёме: 1,57 миллиона синтетических пар против 87 тысяч реальных, то есть примерно 95% датасета — это синтетика.
Разница не в том, используется ли синтетика вообще, а в том, насколько качественно она сделана. Авторы вложили много усилий в то, чтобы синтетические деградации были ближе к реальным: сегмент-зависимый шум вместо равномерного, усреднение по видеокадрам для размытости вместо простого гауссовского фильтра, смешивание реальных паттернов хейза и муара с синтетическими. Плюс на втором этапе обучения добавляются реальные пары, которые «калибруют» модель под реальное распределение.
Предыдущие модели обучались только на синтетике с упрощёнными моделями деградации, а RealRestorer использует более реалистичную синтетику и дополняет её реальными парами на втором этапе. Это принципиально другой рецепт, но синтетика остаётся ключевым ингредиентом в обоих случаях.
Два подхода к сбору данных
Первый подход — синтетическая генерация деградаций (Synthetic Degradation Data). Берётся чистое изображение, и к нему применяется алгоритм деградации. Например, для симуляции размытости использовалось усреднение по кадрам видеоклипов, чтобы симулировать реалистичные траектории движения. Для шума авторы добавили сегмент-зависимый шум (segment-aware noise) — шум добавляется по-разному для разных семантических областей изображения, что даёт более реалистичный результат. Для тумана синтез строился на классической модели атмосферного рассеяния с оценкой глубины через MiDaS. Это масштабируемо — чистых фотографий в интернете достаточно, но всё равно не позволяет воспроизвести всю сложность реальных деградаций.
Второй — реальные деградированные изображения (Real-World Degradation Data). Авторы собирали в интернете реально испорченные фотографии, затем с помощью мощных генеративных моделей создавали для них чистые референсы. Чтобы отфильтровать плохие примеры, использовали CLIP для семантической фильтрации по деградации и Qwen3-VL-8B-Instruct для оценки степени деградации. Такие пары ближе к реальному распределению, но сложнее в сборке.
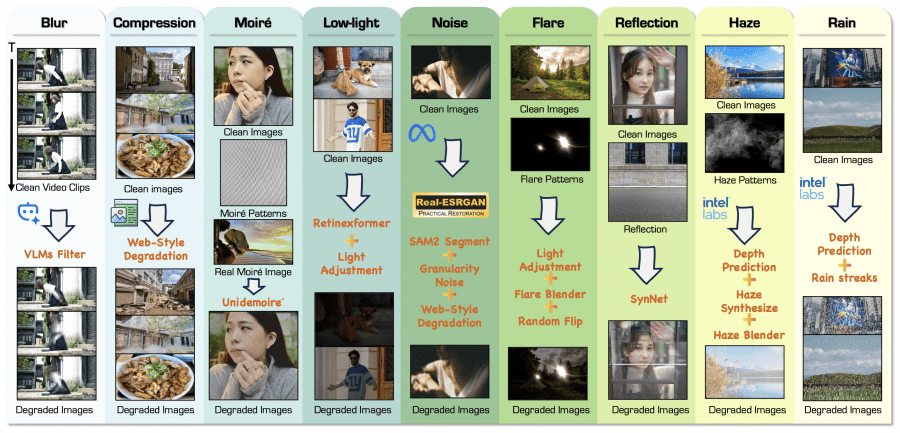
В итоге датасет выглядит так: 1,57 миллиона синтетических пар и 87 тысяч реальных, причём для некоторых типов деградации реальных данных нет вовсе — например, муар и компрессионные артефакты представлены только синтетикой.
Как устроена сама модель
RealRestorer — это не архитектура с нуля, а дообученная открытая модель Step1X-Edit, которая построена на архитектуре DiT (Diffusion Transformer). Внутри используется двухпоточная архитектура: одновременно обрабатывается семантическая информация через языковой энкодер QwenVL и сам зашумлённый сигнал вместе с условным входным изображением. Кодирование в латентное пространство выполняет Flux-VAE.
Обучение проходило в два этапа. На первом этапе (Transfer Training) модель обучалась только на синтетических данных — это позволило перенести знания из задачи редактирования изображений в задачу восстановления. Скорость обучения держалась постоянной на уровне 1e⁻⁵, разрешение — 1024×1024. На втором этапе — контролируемое дообучение — к синтетике добавлялись реальные деградированные пары, а скорость обучения убывала по косинусному расписанию (cosine annealing). Плавное убывание по косинусу позволяет модели мягко сдвинуться к новому распределению данных, не делая резких скачков. Авторы также использовали стратегию Progressively-Mixed Training: небольшую долю синтетических данных оставляли и во втором этапе, чтобы модель не переобучилась на реальных паттернах и сохранила обобщающую способность.
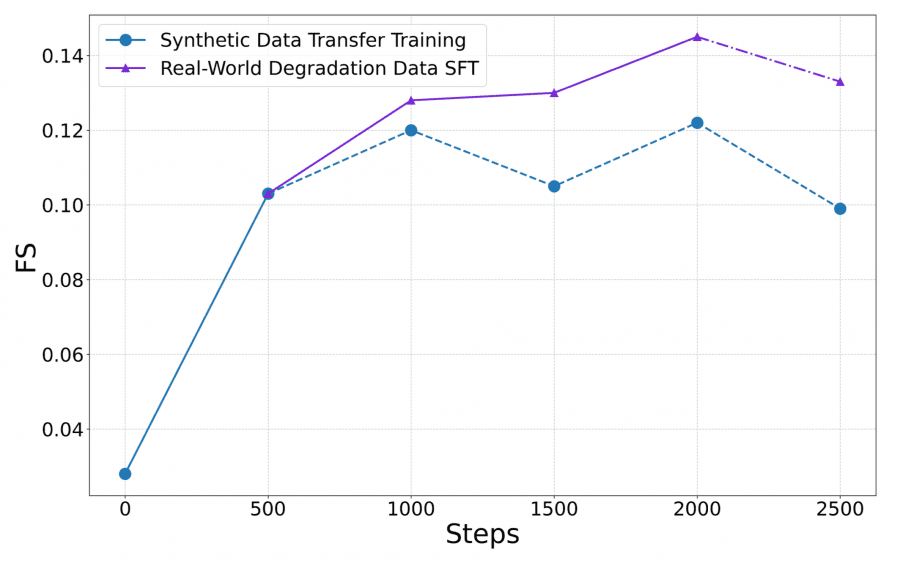
Вот что происходит с качеством при разных стратегиях обучения: модель, обученная только на синтетике, достигает пика Final Score 0,122 и потом деградирует — синтетических данных не хватает для разнообразия. Модель, обученная только на реальных парах, начинает убирать нормальные источники света как «засветку» и теряет структурную согласованность. Двухэтапный подход даёт баланс.
Новый бенчмарк RealIR-Bench и метрики
Стандартные метрики качества — PSNR и SSIM — требуют эталонного чистого изображения для сравнения. Но если тест строится на реально деградированных фотографиях из интернета, таких эталонов нет. Поэтому авторы создали RealIR-Bench — 464 реально деградированных изображения по девяти категориям и придумали безреференсные метрики.
Restoration Score (RS) измеряет, насколько сильно модель убрала деградацию. Для этого языковая VLM-модель Qwen3-VL-8B-Instruct оценивает степень деградации до и после восстановления по шкале от 0 до 5 — RS равен разности этих оценок. LPIPS (Learned Perceptual Image Patch Similarity) измеряет перцептивное сходство восстановленного изображения с исходным деградированным — то есть насколько модель сохранила содержание кадра. Итоговый Final Score объединяет обе метрики: FS = 0,2 × (1 − LPIPS) × RS. Если модель хорошо убирает деградацию, но ломает содержание изображения — итоговый балл всё равно будет низким.
Результаты сравнения
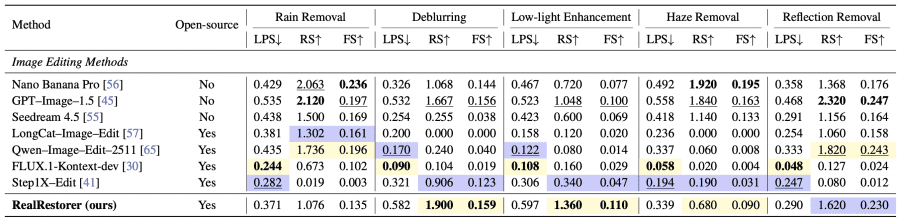
Авторы сравнили RealRestorer с семью моделями: с закрытыми Nano Banana Pro, GPT-Image-1.5, Seedream 4.5 и открытыми LongCat-Image-Edit, Qwen-Image-Edit-2511, FLUX.1-Kontext-dev, Step1X-Edit.
По среднему Final Score на RealIR-Bench RealRestorer занял третье место среди всех моделей с результатом 0,146 — уступив Nano Banana Pro (0,153) и GPT-Image-1.5 (0,150), но при этом превзойдя все открытые решения. Среди открытых моделей ближайший конкурент — Qwen-Image-Edit-2511 с результатом 0,127. По отдельным задачам среди всех протестированных моделей — включая закрытые коммерческие — RealRestorer лучше всех справился с устранением размытости и улучшением изображений при слабом освещении.

Подробное сравнение по всем девяти задачам
Для каждой задачи указаны три метрики: LPS (LPIPS, чем меньше — тем лучше), RS — Restoration Score (чем больше — тем лучше) и FS — Final Score (чем больше — тем лучше). Жёлтым в оригинале выделен лучший результат среди открытых моделей, синим — второй лучший.
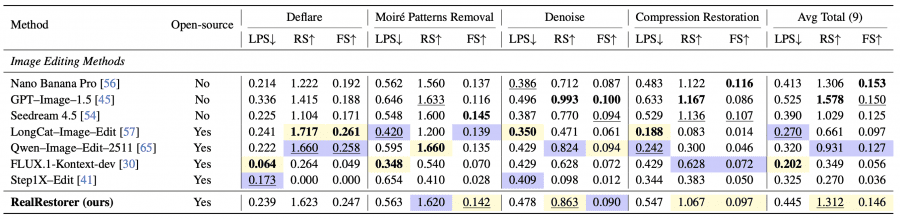
На бенчмарке FoundIR, где есть эталонные чистые изображения, RealRestorer показал лучший результат на 5 из 7 деградаций со средним значением PSNR 21,45 дБ против 20,37 дБ у Nano Banana Pro.

Дополнительно авторы проверили zero-shot generalization — способность работать с типами деградации, на которых модель не обучалась. RealRestorer показал обнадёживающие результаты на удалении снега и восстановлении старых фотографий, хотя таких данных в обучении не было.
Пользовательское исследование
32 участника оценили 3200 групп изображений от пяти лучших моделей по двум критериям: качество восстановления и сохранение содержания. Nano Banana Pro получила наивысший рейтинг у 32% участников, GPT-Image-1.5 — у 23,8%, RealRestorer — у 21,5%. Это согласуется с численными результатами по Final Score. Статистический анализ показал умеренное соответствие между предложенными метриками и оценками людей (p < 0,01 по критериям Kendall τb, SRCC и PLCC).
Ограничения
Авторы честно перечисляют три проблемы. Вычислительная стоимость инференса выше, чем у небольших специализированных сетей — базовая модель использует 28 шагов денойзинга в диффузионном процессе. При сильной семантической неоднозначности — например, на фото с отражением в зеркале — модель иногда не может отличить реальную сцену от отражения. И при очень сильных деградациях, где большая часть пикселей утрачена, модель может не восстановить физически корректные структуры вроде отражений на воде.
Запустить RealRestorer локально непросто: нужна видеокарта с не менее чем 34 ГБ видеопамяти — это уровень A100 или H100, недостижимый для большинства потребительских GPU вроде RTX 4090 с её 24 ГБ. Квантованных версий пока нет. Для установки требуется Python 3.12 и патченная версия библиотеки Diffusers из репозитория проекта — стандартная установка через pip не подойдёт. Инференс запускается через RealRestorerPipeline с рекомендуемыми параметрами: 28 шагов, guidance scale 3.0, torch dtype bfloat16. Размер модели в параметрах авторы не публикуют, но Step1X-Edit, на которой она основана, сопоставима по масштабу с FLUX.1 — это порядка нескольких миллиардов параметров. Именно этим объясняются высокие требования к памяти.
RealRestorer закрывает разрыв между открытыми и закрытыми моделями улучшения качества изображений до почти незаметного уровня, при этом публикуя веса, данные и пайплайн для некоммерческого использования. Это даёт исследовательскому сообществу сильную открытую базу для дальнейшей работы.






