
Метод MapReduce представляет собой технику, которая используется для обработки огромного количества данных (до нескольких петабайт). Существует много реализаций MapReduce, в том числе известный Apache Hadoop. Здесь я не буду говорить о реализациях MapReduce. Я попытаюсь представить концепцию как можно более интуитивно понятным способом, приведу реальные примеры.
Перевод статьи A Beginners Introduction into MapReduce, автор — Igor Shulga. Ссылка на оригинал — в подвале статьи.
Проблема
Часто в Data Science мы имеем дело с таким с огромным количеством данных, что многие методы их обработки не работают или невозможны в реализации. Огромное количество данных — это хорошо, это очень хорошо, и мы хотим использовать как можно больше.
Давайте начнем с простой задачи. Вам дан список строк, и вам нужно вернуть самую длинную строку. Это довольно легко сделать в Python:
def find_longest_string(list_of_strings):
longest_string = None
longest_string_len = 0
for s in list_of_strings:
if len(s) > longest_string_len:
longest_string_len = len(s)
longest_string = s
return longest_string
Мы перебираем строки по очереди, вычисляем длину и сохраняем самую длинную строку, пока не закончим.
Для небольших списков это работает довольно быстро:
list_of_strings = ['abc', 'python', 'dima'] %time max_length = print(find_longest_string(list_of_strings)) OUTPUT: python CPU times: user 0 ns, sys: 0 ns, total: 0 ns Wall time: 75.8 µs
Даже для списков с более чем 3 элементами это работает довольно хорошо, здесь мы попробуем с 3000 элементами:
large_list_of_strings = list_of_strings*1000 %time print(find_longest_string(large_list_of_strings)) OUTPUT: python CPU times: user 0 ns, sys: 0 ns, total: 0 ns Wall time: 307 µs
Но что если мы попробуем 300 миллионов элементов?
large_list_of_strings = list_of_strings*100000000 %time max_length = max(large_list_of_strings, key=len) OUTPUT: python CPU times: user 21.8 s, sys: 0 ns, total: 21.8 s Wall time: 21.8 s
Это уже проблема. В большинстве приложений время ответа в 20 секунд не приемлемо. Один из способов сократить время вычислений — купить гораздо более быстрый процессор. Масштабирование вашей системы путем внедрения более качественного и быстрого оборудования называется «Вертикальное масштабирование». Это, конечно, не будет работать вечно. Во-первых, не так просто найти процессор, который работает в 10 раз быстрее. Во-вторых, наши данные, вероятно, будут увеличиваться, и мы не хотим менять наш процессор каждый раз, когда ощущаем что наш код недостаточно быстрый. Такое решение не масштабируемое. Вместо этого мы можем выполнить «Горизонтальное масштабирование»: мы разработаем наш код так, чтобы он мог работать параллельно, и он станет намного быстрее, когда мы добавим больше процессоров.
Разбиение кода
Нам нужно разбить наш код на более мелкие компоненты и решить, как мы можем распараллелить вычисления. Идея такова: 1) разбить наши данные на множество блоков, 2) выполнить функцию find_longest_string для каждого блока параллельно и 3) найти самую длинную строку среди выходных данных всех блоков.
Наш код функции имеет очень узкое применение, поэтому вместо использования функции find_longest_string мы разработаем более общую структуру, которая поможет нам выполнять различные параллельные вычисления для больших данных.
В нашем коде мы делаем две основные вещи: вычисляем len строки и сравниваем ее с самой длинной до сих пор строкой. Мы разбиваем наш код на два этапа: 1) вычисляем len всех строк и 2) выбираем значение max.
%%time
# step 1:
list_of_string_lens = [len(s) for s in list_of_strings]
list_of_string_lens = zip(list_of_strings, list_of_string_lens)
#step 2:
max_len = max(list_of_string_lens, key=lambda t: t[1])
print(max_len)
OUTPUT:
('python', 6)
CPU times: user 51.6 s, sys: 804 ms, total: 52.4 s
Wall time: 52.4 s
(Рассчитываем длину строк, а затем сворачиваем их вместе функцией zip. Это намного быстрее, чем делать это в одной строке и дублировать список строк)
В этом состоянии код работает на самом деле медленнее, чем раньше, потому что вместо того, чтобы выполнить один проход для всех наших строк, мы делаем это 2 раза, сначала для вычисления len, а затем для поиска max значения. Почему это хорошо для нас? потому что теперь наш «шаг 2» получает в качестве входных данных не исходный список строк, а некоторые предварительно обработанные данные. Это позволяет нам выполнить второй шаг, используя выходные данные другого «второго шага»! Мы лучше поймем это немного позже, сначала давайте дадим имя этим шагам. Мы будем называть первый шаг «mapper», потому что он отображает какое-то одно значение в какое-то другое значение, а второй шаг мы будем называть «reductor», потому что он получает список значений и выдает одно (в большинстве случаев) значение. Вот две вспомогательные функции для mapper и reductor:
mapper = len
def reducer(p, c):
if p[1] > c[1]:
return p
return c
mapper — это просто функция len. Он получает строку и возвращает ее длину. reducer получает два кортежа в качестве входных данных и возвращает один с наибольшей длиной.
Давайте перепишем наш код, используя map и reduce, в Python даже есть встроенные функции для этого (в Python 3 мы должны импортировать его из functools):
%%time
#step 1
mapped = map(mapper, list_of_strings)
mapped = zip(list_of_strings, mapped)
#step 2:
reduced = reduce(reducer, mapped)
print(reduced)
OUTPUT:
('python', 6)
CPU times: user 57.9 s, sys: 0 ns, total: 57.9 s
Wall time: 57.9 s
Код делает то же самое, но выглядит немного изящнее, а главное — он более универсален и поможет нам распараллелить вычисления. Давайте посмотрим на это более внимательно:
Шаг 1 отображает наш список строк в список кортежей с помощью функции mapper (здесь я снова использую zip, чтобы избежать дублирования строк).
Шаг 2 использует функцию reducer, переходит по кортежам с первого шага и применяет их один за другим. Результатом является кортеж с максимальной длиной.
Теперь давайте разберем наш ввод по частям и поймем, как он работает, прежде чем проводить какое-либо распараллеливание (мы будем использовать chunkify, который разбивает большой список на куски одинакового размера):
data_chunks = chunkify(list_of_strings, number_of_chunks=30)
#step 1:
reduced_all = []
for chunk in data_chunks:
mapped_chunk = map(mapper, chunk)
mapped_chunk = zip(chunk, mapped_chunk)
reduced_chunk = reduce(reducer, mapped_chunk)
reduced_all.append(reduced_chunk)
#step 2:
reduced = reduce(reducer, reduced_all)
print(reduced)
OUTPUT:
('python', 6)
На первом шаге мы просматриваем фрагменты и находим самую длинную строку в этом фрагменте, используя mapper, и уменьшаем. На втором шаге мы берем выходные данные первого шага, которые представляют собой список уменьшенных значений, и выполняем окончательное уменьшение, чтобы получить самую длинную строку. Мы используем number_of_chuncks=36, потому что это количество CPU на моей машине.
Распараллеливание кода
Мы почти готовы запустить наш код параллельно. Единственное, что мы можем сделать лучше, это добавить первый шаг reduce в mapper. Мы делаем это потому, что хотим разбить наш код на два простых шага, а первый reduce работает на одном фрагменте, и мы хотим его распараллелить. Вот как это выглядит:
def chunks_mapper(chunk):
mapped_chunk = map(mapper, chunk)
mapped_chunk = zip(chunk, mapped_chunk)
return reduce(reducer, mapped_chunk)
%%time
data_chunks = chunkify(list_of_strings, number_of_chunks=30)
#step 1:
mapped = map(chunks_mapper, data_chunks)
#step 2:
reduced = reduce(reducer, mapped)
print(reduced)
OUTPUT:
('python', 6)
CPU times: user 58.5 s, sys: 968 ms, total: 59.5 s
Wall time: 59.5 s
Теперь у нас есть красивый двухшаговый код. Если мы выполним это как есть, мы получим то же время вычисления, но теперь мы можем распараллелить шаг 1, используя модуль multiprocessing, просто используя функцию pool.map вместо обычной функции map.
from multiprocessing import Pool
pool = Pool(8)
data_chunks = chunkify(large_list_of_strings, number_of_chunks=8)
#step 1:
mapped = pool.map(mapper, data_chunks)
#step 2:
reduced = reduce(reducer, mapped)
print(reduced)
OUTPUT:
('python', 6)
CPU times: user 7.74 s, sys: 1.46 s, total: 9.2 s
Wall time: 10.8 s
Мы видим, что он работает в 2 раза быстрее! Это не слишком значительное улучшение, но зато мы теперь знаем, что можем улучшить его, увеличив число процессов! Мы можем даже сделать это на более чем одной машине, если наши данные очень большие, мы можем использовать десятки или даже тысячи машин, чтобы сделать наше время вычислений настолько коротким (почти), насколько мы хотим.
Архитектура MapReduce
Наша архитектура построена с использованием двух функций: map и reduce. Каждый вычислительный блок отображает входные данные и выполняет начальное уменьшение. Наконец, некоторое централизованное устройство выполняет окончательное уменьшение и возвращает вывод. Это выглядит так:
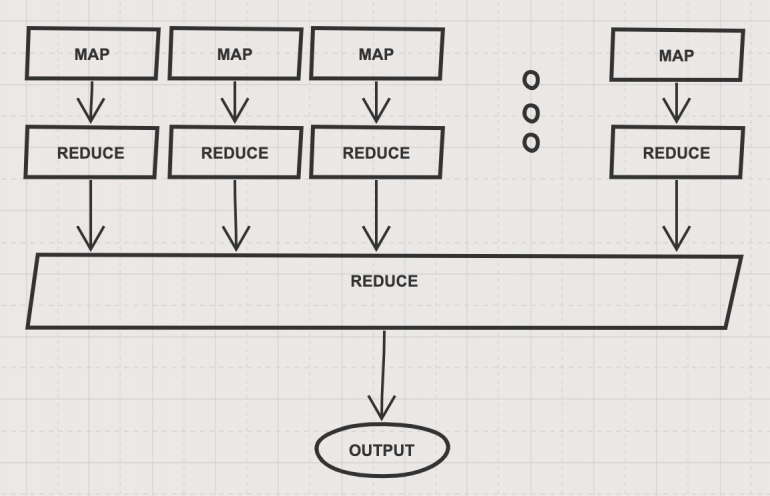
Эта архитектура имеет два важных преимущества:
-
- Она масштабируема: если у нас есть больше данных, единственное, что нам нужно сделать, это добавить больше единиц обработки. Изменение кода не требуется!
- Она универсальна: эта архитектура поддерживает широкий спектр задач, мы можем изменить функционал наших map и reduce так, как захотим.
Важно отметить, что в большинстве случаев наши данные будут очень большими и статичными. Это означает, что разбиение на фрагменты каждый раз неэффективно и фактически излишне. Таким образом, в большинстве приложений в реальной жизни мы будем хранить наши данные в виде кусков (или фрагментов) с самого начала. Затем мы сможем выполнять различные вычисления, используя технику MapReduce.
Пример с подсчетом слов
Теперь давайте посмотрим на более интересный пример: Подсчет слов!
Скажем, у нас очень большой набор новостных статей, и мы хотим найти топ-10 используемых слов, не включая стоп-слова. Как бы мы это сделали? Во-первых, давайте получим данные:
from sklearn.datasets import fetch_20newsgroups data = news.data*10
Для этого поста я увеличил данные в 10 раз, чтобы мы могли увидеть разницу.
Для каждого текста в наборе данных мы хотим: токенизировать его, очистить, удалить стоп-слова и, наконец, посчитать слова:
def clean_word(word):
return re.sub(r'[^ws]','',word).lower()
def word_not_in_stopwords(word):
return word not in ENGLISH_STOP_WORDS and word and word.isalpha()
def find_top_words(data):
cnt = Counter()
for text in data:
tokens_in_text = text.split()
tokens_in_text = map(clean_word, tokens_in_text)
tokens_in_text = filter(word_not_in_stopwords, tokens_in_text)
cnt.update(tokens_in_text)
return cnt.most_common(10)
Давайте посмотрим, сколько времени это займет без MapReduce:
%time find_top_words(data)
OUTPUT:
[('subject', 122520),
('lines', 118240),
('organization', 111850),
('writes', 78360),
('article', 67540),
('people', 58320),
('dont', 58130),
('like', 57570),
('just', 55790),
('university', 55440)]
CPU times: user 51.7 s, sys: 0 ns, total: 51.7 s
Wall time: 51.7 s
Теперь давайте напишем наш mapper, reducer и chunk_mapper:
def mapper(text):
tokens_in_text = text.split()
tokens_in_text = map(clean_word, tokens_in_text)
tokens_in_text = filter(word_not_in_stopwords, tokens_in_text)
return Counter(tokens_in_text)
def reducer(cnt1, cnt2):
cnt1.update(cnt2)
return cnt1
def chunk_mapper(chunk):
mapped = map(mapper, chunk)
reduced = reduce(reducer, mapped)
return reduced
mapper получает текст, разбивает его на лексемы, очищает их и фильтрует стоп-слова и слова, не несущие смысла. В конце концов, он подсчитывает слова внутри этого единого текста документа. Функция reducer получает 2 счетчика и объединяет их. chunk_mapper получает кусок и делает на нем MapReduce. Теперь давайте запустим фреймворк, который мы создали, и посмотрим:
%%time
data_chunks = chunkify(data, number_of_chunks=36)
#step 1:
mapped = pool.map(chunk_mapper, data_chunks)
#step 2:
reduced = reduce(reducer, mapped)
print(reduced.most_common(10))
OUTPUT:
[('subject', 122520),
('lines', 118240),
('organization', 111850),
('writes', 78360),
('article', 67540),
('people', 58320),
('dont', 58130),
('like', 57570),
('just', 55790),
('university', 55440)]
CPU times: user 1.52 s, sys: 256 ms, total: 1.77 s
Wall time: 4.67 s
Это в 10 раз быстрее! Здесь мы смогли ощутимо использовать наши вычислительные возможности, потому что задача намного сложнее и требует большего.
Подводя итог, можно сказать, что MapReduce — это интересный и важный метод для обработки больших данных. Он может справиться с огромным количеством задач, включая подсчет, поиск, supervised и unsupervised обучение и многое другое. Сегодня существует множество реализаций и инструментов, которые могут сделать нашу жизнь более комфортной, но я думаю, что очень важно понимать основы.



