Перенос стиля (style transfer) — одно из наиболее креативных приложений сверточных нейронных сетей. Взяв контент с одного изображения и стиль от второго, нейронная сеть объединяет их в одно художественное произведение.
Перевод статьи Introduction to Neural Style Transfer with TensorFlow, автор — Marco Peixeiro, ссылка на оригинал — в подвале статьи.
Эти алгоритмы чрезвычайно гибкие, бесконечные комбинации контента и стиля привели к очень креативным и уникальным результатам.

Компания-разработчик мобильного приложения Prisma оптимизировала алгоритм, использующий перенос стиля на фото с вашего мобильного телефона, и упаковала в приложение.
В этом туториале мы воссоздадим алгоритм, предложенный для достижения результатов, аналогичных примерам выше. Обратите внимание, что я работаю на ноутбуке, и поэтому результаты могут немного отличаться, если вы работаете на ПК с лучшим процессором.
Не стесняйтесь сверяться с тетрадкой с реализацией, если вы застрянете на каком-нибудь шаге.
Что ж, давайте сделаем это!

Шаг 1. Загрузка VGG-19
Создание алгоритма с нуля потребовало бы много времени и вычислительных ресурсов, что не всегда доступно для всех.
Вместо этого мы будем загружать веса существующей сети для реализации переноса стиля.
Процесс использования уже обученной ранее нейронной сети для других целей называется transfer learning.
Давайте загрузим модель:
model = load_vgg_model(«pretrained-model / imagenet-vgg-verydeep-19.mat»)
Какая же она большая! Теперь я буду использовать изображение Лувра в качестве изображения контента. Вы можете загрузить любое изображение, которое хотите, но убедитесь, что оно не слишком большое:
content_image = scipy.misc.imread («images / louvre.jpg») imshow (content_image)
В моем случае это выглядит так:

Шаг 2. Определение функции потерь для контента
Чтобы наш алгоритм генерировал красивые изображения, мы должны убедиться, что содержимое сгенерированного изображения будет соответствовать содержимому входного изображения.
Другими словами, генерируемое изображение также должно иметь пирамиду, окружающие здания, облака, солнце и т. Д.
Поэтому мы хотим, чтобы активация слоя сгенерированного изображения и изображения контента была одинаковой. Следовательно, функция потерь для контента может быть определена как:
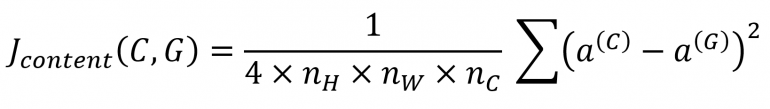
Из приведенного выше уравнения n_H и n_W — это высота и ширина изображения соответственно, где n_c — количество каналов в скрытом слое.
Чтобы вычислить значение функции потерь, эффективнее будет развернуть трехмерные тензоры в двумерные матрицы, поскольку это ускорит вычисления.
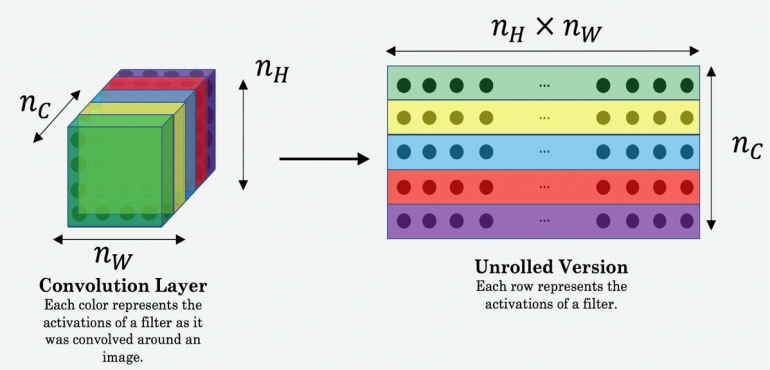
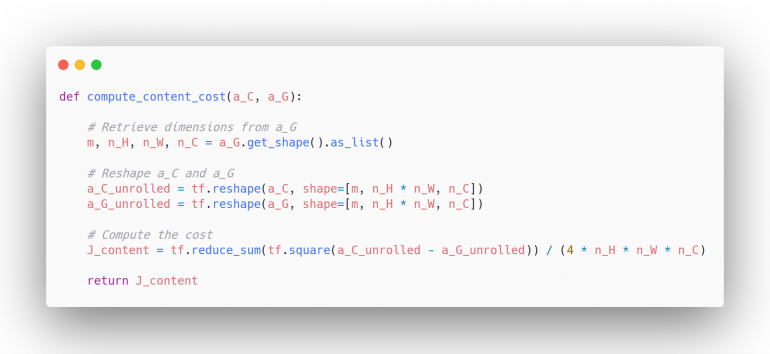
Теперь мы кодируем эту логику:
Шаг 3. Определение функции потерь для стиля
Теперь нам нужен стиль изображения. В моем случае я буду использовать работу импрессиониста Клода Моне, но не стесняйтесь использовать любой другой вид искусства:

Определение функции потерь для стиля — несколько более сложный процесс, чем для контента. Давайте разобьем его на части.
Шаг 3.1. Определить матрицу Грама
Матрица стилей также называется матрицей Грама и представляет собой скалярное произведение точек набора векторов.
Это отражает сходство между каждым вектором, поскольку, если два вектора похожи друг на друга, то скалярное произведение их точек будет большим, и, следовательно, матрица Грама будет иметь большие значения.
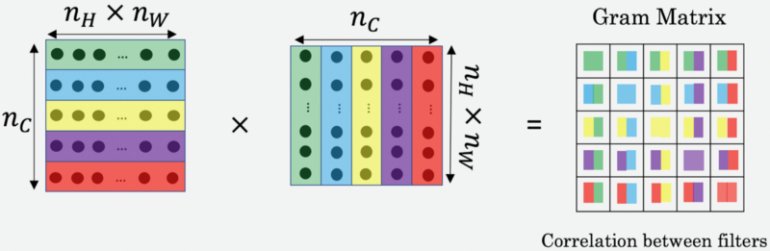
Вот так матрица Грама может эффективно измерять стиль изображения.
Реализуем это в коде:
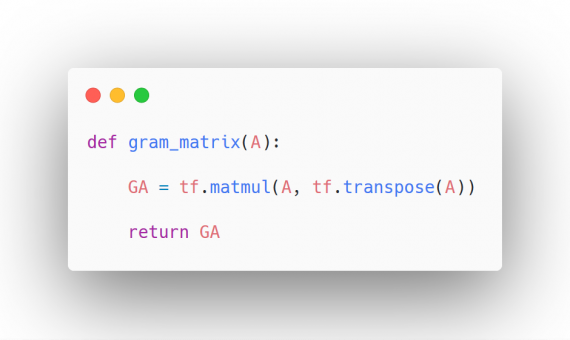
Шаг 3.2. Определение функции потерь для стиля
Теперь мы хотим убедиться, что стили сгенерированного изображения и изображения стиля похожи.
Другими словами, мы хотим минимизировать расстояние между двумя матрицами Грама. Это выражается как:
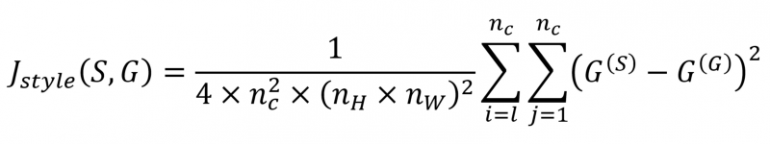
Кодирование логики:
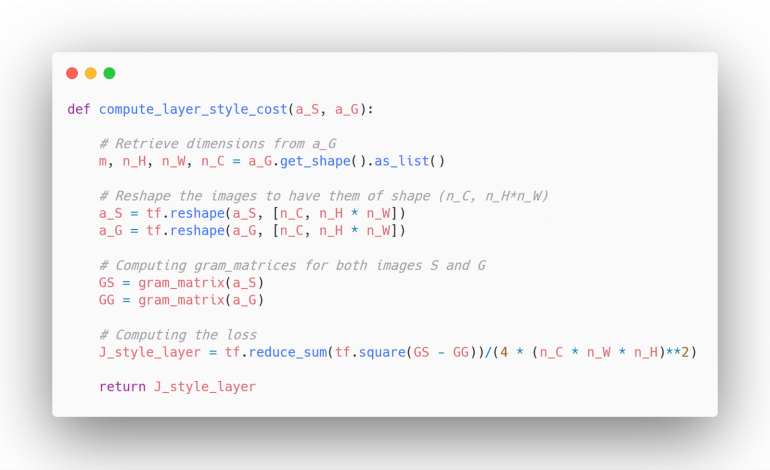
Шаг 3.3. Назначение весов разным слоям стиля
На предыдущем шаге мы фиксировали только значение функции потерь стиля для одного слоя. Было бы полезно объединить значения функции потерь стиля всех слоев, чтобы создать лучшее изображение.
Тогда математически функция потерь стиля становится:
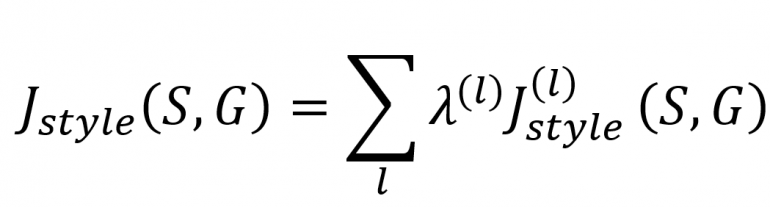
где λ — вес для каждого слоя.
Таким образом, мы добавляем эту ячейку кода:

Шаг 3.4. Объединение всего
Теперь мы просто объединяем все в единую функцию потерь для стиля:
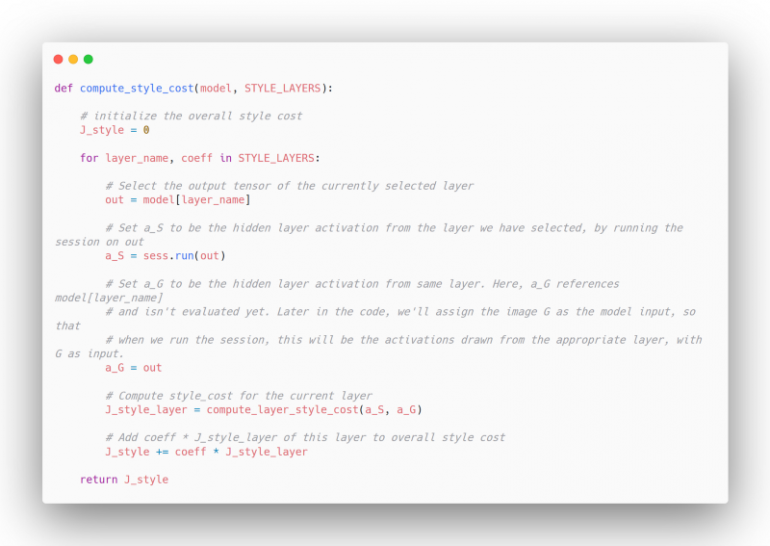
Шаг 4. Определение общей функции потерь
Теперь, когда у нас есть функция потерь для контента и стиля, мы можем объединить обе функции, чтобы получить общую функцию потерь, которая далее будет оптимизирована:
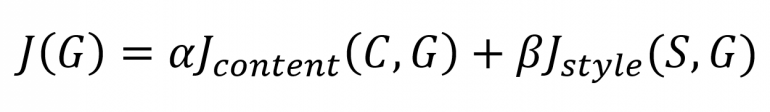
где α и β — произвольные веса.
Шаг 5. Решение задачи оптимизации и создание изображения
А теперь лучшая часть! Со всем на месте, мы можем решить задачу оптимизации и создать художественный образ!
# Reset the graph
tf.reset_default_graph()
# Start interactive session
sess = tf.InteractiveSession()
content_image = scipy.misc.imread("images/louvre_small.jpg")
content_image = reshape_and_normalize_image(content_image)
style_image = scipy.misc.imread("images/monet.jpg")
style_image = reshape_and_normalize_image(style_image)
model = load_vgg_model("weights/imagenet-vgg-verydeep-19.mat")
# Assign the content image to be the input of the VGG model.
sess.run(model['input'].assign(content_image))
# Select the output tensor of layer conv4_2
out = model['conv4_2']
# Set a_C to be the hidden layer activation from the layer we have selected
a_C = sess.run(out)
# Set a_G to be the hidden layer activation from same layer. Here, a_G references model['conv4_2']
# and isn't evaluated yet. Later in the code, we'll assign the image G as the model input, so that
# when we run the session, this will be the activations drawn from the appropriate layer, with G as input.
a_G = out
# Compute the content cost
J_content = compute_content_cost(a_C, a_G)
# Assign the input of the model to be the "style" image
sess.run(model['input'].assign(style_image))
# Compute the style cost
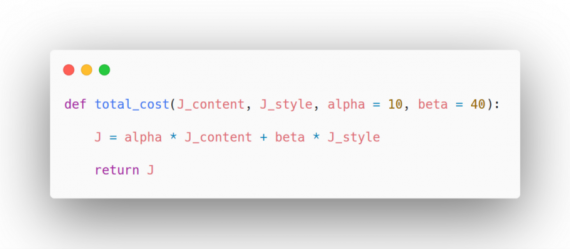
J_style = compute_style_cost(model, STYLE_LAYERS)
J = total_cost(J_content,J_style,alpha=10,beta=40)
# define optimizer
optimizer = tf.train.AdamOptimizer(2.0)
# define train_step
train_step = optimizer.minimize(J)
def model_nn(sess, input_image, num_iterations = 200):
# Initialize global variables (you need to run the session on the initializer)
sess.run(tf.global_variables_initializer())
# Run the noisy input image (initial generated image) through the model. Use assign().
sess.run(model["input"].assign(input_image))
for i in range(num_iterations):
# Run the session on the train_step to minimize the total cost
sess.run(train_step)
# Compute the generated image by running the session on the current model['input']
generated_image = sess.run(model['input'])
# Print every 20 iteration.
if i % 20 == 0:
Jt, Jc, Js = sess.run([J, J_content, J_style])
print("Iteration " + str(i) + " :")
print("total cost = " + str(Jt))
print("content cost = " + str(Jc))
print("style cost = " + str(Js))
# save current generated image in the "/output" directory
save_image("output/" + str(i) + ".png", generated_image)
# save last generated image
save_image('output/generated_image.jpg', generated_image)
return generated_image
model_nn(sess, generated_image)
В моем случае я получаю следующий результат:

Конечно, вы можете получить гораздо более хорошие результаты, если будете тренировать сеть дольше и с меньшей скоростью обучения.
Поздравляю! Вы только что выполнили перенос стиля изображений в TensorFlow! Смело меняйте изображения контента и стиля, а также поиграйтесь с количеством эпох и скоростью обучения (learning rate)