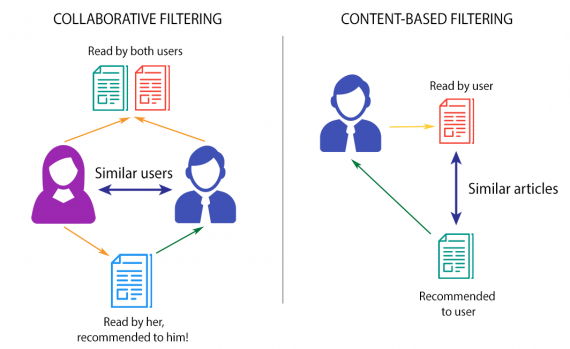
Метод коллаборативной фильтрации в рекомендательных системах предсказывает оценку или предпочтение, которое пользователь будет отдавать объекту на основе его прежних оценок или предпочтений. Системы рекомендаций используются практически каждой крупной компанией для повышения качества предложения своих услуг.
Перевод статьи «Collaborative filtering with FastAI», автор — Gilbert Tanner, ссылка на оригинал — в подвале статьи.
В одной из моих первых статей я создал систему рекомендаций для книг, используя Keras. В этой статье я покажу вам, как создать ту же систему рекомендаций с использованием библиотеки FastAI, а также как построить модель на основе нейронной сети, чтобы получить еще лучшие результаты.
Для наших данных мы будем использовать датасет goodbooks-10k, который содержит десять тысяч различных книг и около миллиона оценок. Он имеет три признака: book_id, user_id и рейтинг. Если вы хотите, вы можете получить все файлы данных и полный код к этой статье из моего репозитория Github.
Если вы предпочитаете наглядное руководство, вы можете посмотреть мои видео по FastAI на канале YouTube.
Получение данных
После загрузки датасета из Kaggle нам нужно загрузить модуль коллаборативной фильтрации FastAI, указать путь к датасету и загрузить CSV, содержащий рейтинги, и CSV, содержащий информацию о книге.
from fastai.collab import *
# specify path
path = Path('')
print(path.ls())
# load in ratings data
ratings = pd.read_csv(path/'ratings.csv')
print(ratings.head())
# load in book information data
books = pd.read_csv(path/'books.csv')
print(books.head())
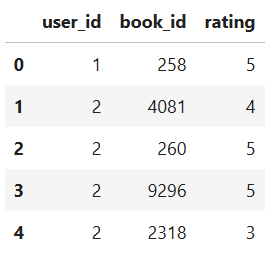
Dataframe с рекомендациями
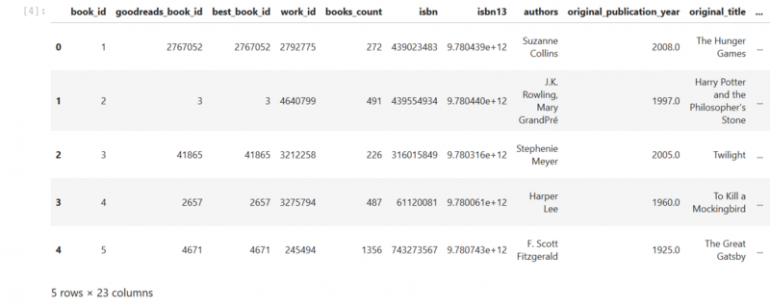
Dataframe с информацией о книгах
Загрузив наши данные, мы можем создать CollabDataBunch, который представляет собой датасет, специально созданный для задач коллаборативной фильтрации. Мы передадим ему наши данные о рейтинге, случайное начальное число, а также размер нашей тестовой выборки, который определяется аргументом valid_pct.
data = CollabDataBunch.from_df(ratings, seed=42, valid_pct=0.1, user_name='user_id', item_name='book_id', rating_name='rating')
Мы можем отобразить батч наших данных, используя метод show_batch.
data.show_batch()
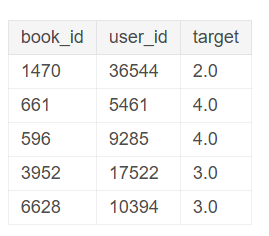
Случайный батч данных
Последнее, что нам нужно сделать перед созданием и обучением нашей модели — получить максимальное и минимальное значения наших рейтингов. Затем мы передадим эти значения в нашу модель, чтобы она могла затем сжать окончательные результаты между этими двумя значениями.
ratings.rating.min(), ratings.rating.max()
Вывод: (1, 5)
Модель EmbeddingDotBias
FastAI предоставляет два разных типа моделей коллаборативной фиьтрации. Первая — простая модель под названием EmbeddingDotBias, которая использовалась почти для всех рекомендательных систем несколько лет назад. Она создает векторные представления как для пользователей, так и для книг, а затем берет их скалярное произведение. Вторая — это модель на основе нейронной сети, которая использует векторные представления и полносвязные слои.
Векторное представление (embedding) — это перевод из дискретных объектов, таких как слова или идентификаторы книг и, в нашем случае, пользователей, в вектор вещественных значений. Это можно использовать для нахождения сходства между дискретными объектами, которое не было бы очевидным для модели, если бы в ней не использовались слои векторных представлений.
Эти векторные представления являются низкоразмерными и обновляются во время обучения сети.
Обе модели могут быть созданы с использованием класса collab_learner. По умолчанию аргумент use_nn имеет значение false, то есть мы создаем модель EmbeddingDotBias.
В качестве следующих аргументов мы можем передать в collab_learner аргумент n_factors, который представляет размер векторных представлений, а также аргумент y_range, который указывает диапазон значений рейтинга, которые мы нашли ранее.
learn = collab_learner(data, n_factors=40, y_range=(1, 5), wd=1e-1)
Теперь мы можем найти learning rate, обучить нашу модель с помощью метода fit_one_cycle и сохранить модель. Если вы еще не знакомы с этим процессом, я бы порекомендовал вам прочитать мою первую статью о классификации изображений с помощью библиотеки FastAI.
learn.lr_find() # find learning rate learn.recorder.plot() # plot learning rate graph
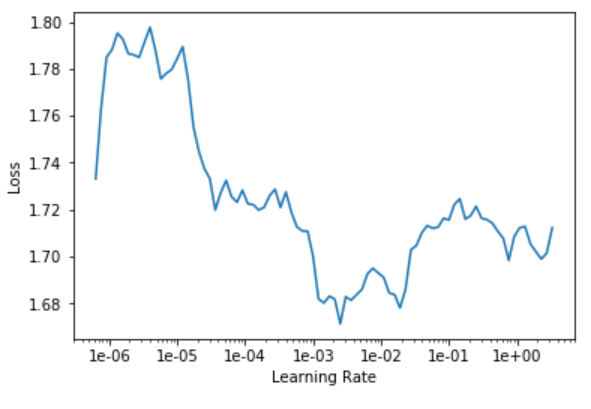
learn.fit_one_cycle(5, 3e-4)
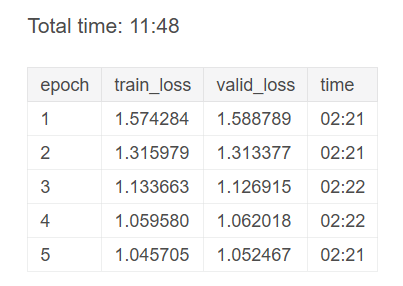
Результаты обучения
learn.save('goodbooks-dot-1')
Модель EmbeddingNN
Второй тип модели коллаборативной фильтрации, предоставляемой FastAI, называется EmbeddingNN. Она дает нам возможность создавать векторные представления разных размеров и передавать их в нейронную сеть.
FastAI также предоставляет нам возможность настроить количество слоев и их нейронов.
learn = collab_learner(data, use_nn=True, emb_szs={'user_id': 40, 'book_id':40}, layers=[256, 128], y_range=(1, 5))
Как всегда, следующие шаги — найти learning rate и обучить модель.
learn.lr_find() # find learning rate learn.recorder.plot() # plot learning rate graph
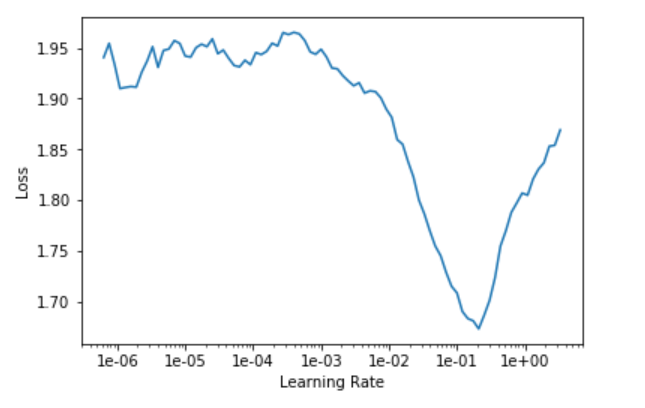
learn.fit_one_cycle(5, 1e-2)
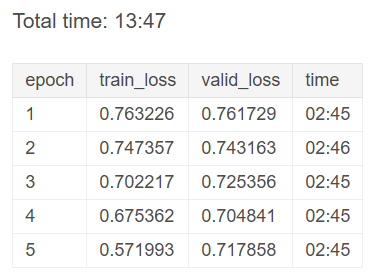
Результаты обучения
Мы видим, что нейронная сеть работает намного лучше, чем наша модель точечного продукта.
Интерпретация
Поскольку обученные векторные представления должны наилучшим образом отражать стиль и вид книг и пользователей, они могут содержать интересные функции, которые мы можем извлечь и визуализировать для получения важной информации.
Для этого FastAI позволяет легко получать доступ к векторным представлениям пользователей и книг, а также к их склонностям.
В этой статье мы извлечем склонности к книгам и их веса, чтобы получить представление о том, какие книги должны быть ранжированы ниже или выше, с учетом векторного представления склонностей, а также того, насколько похожи некоторые из самых популярных книг с использованием весов слоя векторного представления.
Для начала мы загрузим нашу модель EmbeddingDotBias и получим 1000 самых популярных книг по количеству отзывов.
# load in EmbeddingDotBias model
learn = collab_learner(data, n_factors=40, y_range=(1, 5), wd=1e-1, model_dir="/tmp/model/", path="/tmp/")
learn.load('goodbooks-dot-1');
# get top books
g = ratings.groupby('book_id')['rating'].count()
top_books = g.sort_values(ascending=False).index.values[:1000]
top_books = top_books.astype(str)
# create array containing the names of the top books
top_books_with_name = []
for book in top_books:
top_books_with_name.append(books[(books['id']==int(book))]['title'].iloc[0])
top_books_with_name = np.array(top_books_with_name)
Теперь мы можем извлечь склонности к лучшим книгам, а также средний рейтинг лучших книг и вывести результат. Благодаря этому мы можем получать информацию о книгах, которые обычно оцениваются как низкие или высокие, независимо от того, какой пользователь их оценивает.
# get biases for top books
book_bias = learn.bias(top_books, is_item=True)
# get mean ratings
mean_ratings = ratings.groupby('book_id')['rating'].mean()
book_ratings = [(b, top_books_with_name[i], mean_ratings.loc[int(tb)]) for i, (tb, b) in enumerate(zip(top_books, book_bias))]
# print book bias information
item0 = lambda o:o[0]
print(sorted(book_ratings, key=item0)[:15])
print(sorted(book_ratings, key=item0, reverse=True)[:15])
# get weights
book_w = learn.weight(top_books, is_item=True)
# transform weights to 3 dimensions
book_pca = book_w.pca(3)
# get prinicipal components
fac0,fac1,fac2 = book_pca.t()
book_comp = [(f, i) for f,i in zip(fac0, top_books_with_name)]
# print fac0 information
print(sorted(book_comp, key=itemgetter(0), reverse=True)[:10])
print(sorted(book_comp, key=itemgetter(0))[:10])
# print fac1 information
book_comp = [(f, i) for f,i in zip(fac1, top_books_with_name)]
print(sorted(book_comp, key=itemgetter(0), reverse=True)[:10])
print(sorted(book_comp, key=itemgetter(0))[:10])
Output: Top idx: array(['5000', '3315', '3313', '3312', '3311', '3309', '3308', '3307', '3306', '3304'], dtype='<U21') Top names: array(['Passion Unleashed (Demonica #3)', 'My Story', 'The Gargoyle', 'Pretty Baby', ..., 'Top Secret Twenty-One (Stephanie Plum, #21)', 'The Warrior Heir (The Heir Chronicles, #1)', 'Stone Soup', 'The Sixth Man (Sean King & Michelle Maxwell, #5)'], dtype='<U144') Most negative bias: [(tensor(-0.1021), 'The Almost Moon', 2.49), (tensor(-0.0341), 'Skinny Bitch', 2.9), (tensor(-0.0325), 'Bergdorf Blondes', 3.0), (tensor(-0.0316), 'The Particular Sadness of Lemon Cake', 2.93), (tensor(-0.0148), 'The Weird Sisters', 3.08)] ...
Мы также можем визуализировать две основных компоненты, используя графическую библиотеку, например, Matplotlib.
idxs = np.random.choice(len(top_books_with_name), 50, replace=False) idxs = list(range(50)) X = fac0[idxs] Y = fac2[idxs] plt.figure(figsize=(15,15)) plt.scatter(X, Y) for i, x, y in zip(top_books_with_name[idxs], X, Y): plt.text(x,y,i, color=np.random.rand(3)*0.7, fontsize=11) plt.show()
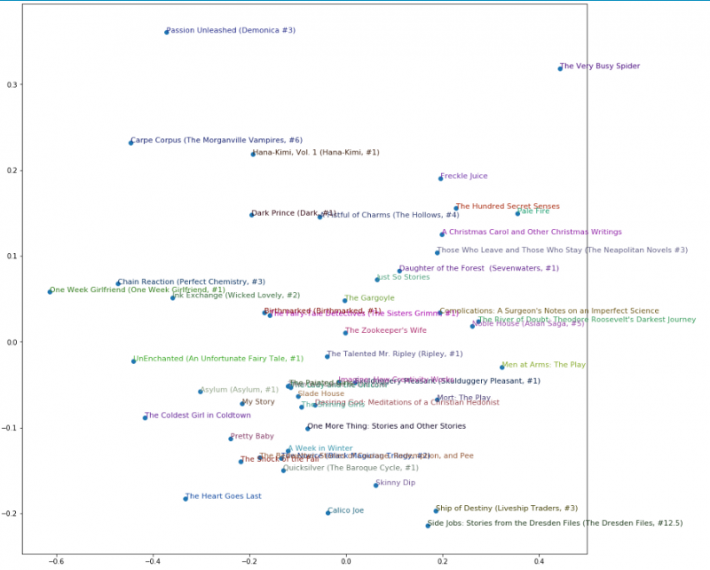
Визуализация весов слоя векторного представления
Заключение
Рекомендательные системы стремятся предсказать рейтинг или предпочтение, которое пользователь будет отдавать элементу, учитывая его старые оценки или предпочтения.
Библиотека глубокого обучения FastAI предоставляет нам функциональные возможности, позволяющие легко загружать наши данные и создавать модели коллаборативной фильтрации.