Gretel, a startup specializing in generating high-quality synthetic data, has announced the creation of the largest open text-to-SQL dataset aimed at accelerating the development of no-code analytics tools.
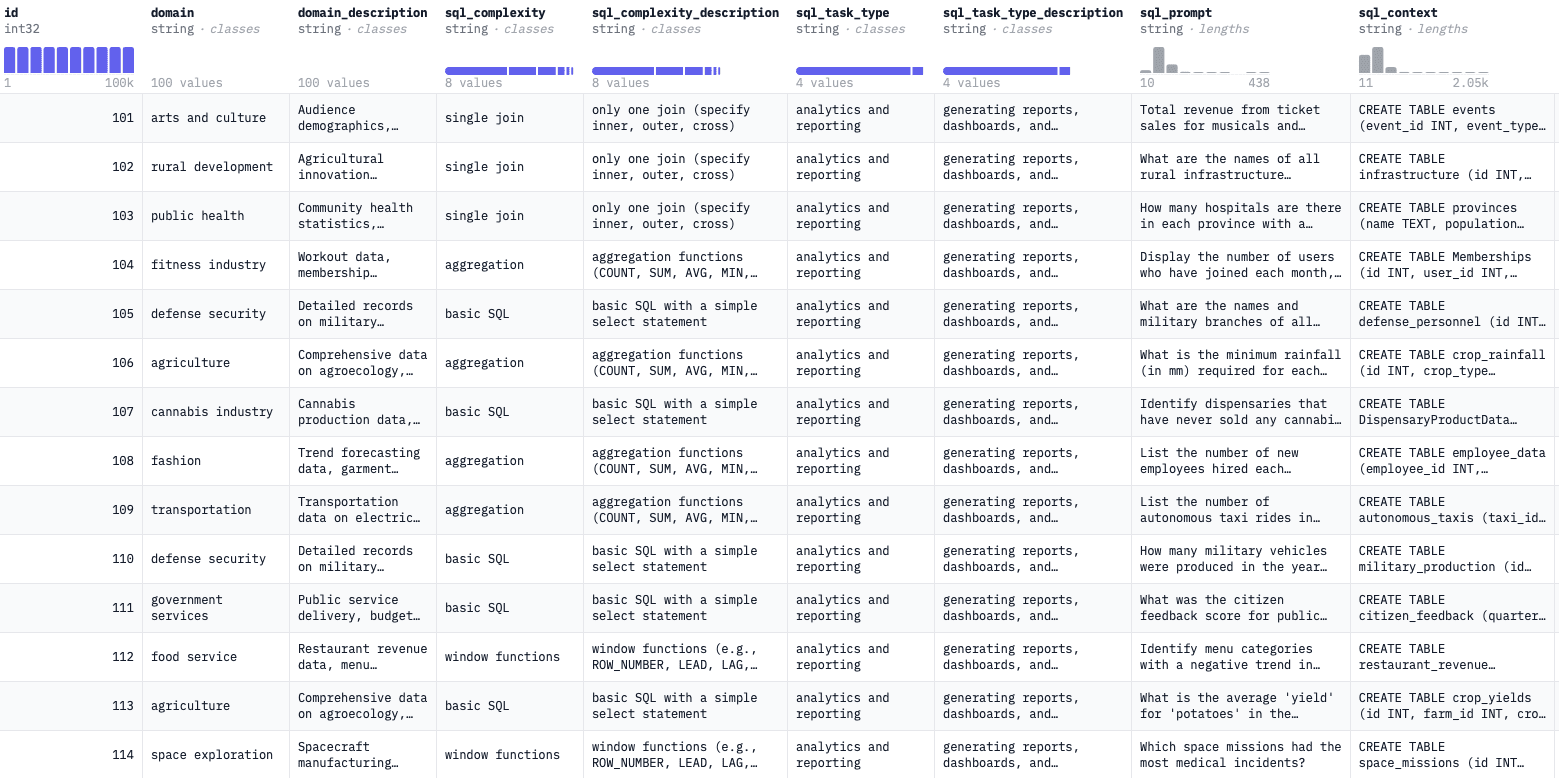
The dataset contains over 100,000 valid synthetic samples of text-to-SQL conversion, covering typical queries across 100 business and industrial domains.
Created using Gretel Navigator, an open artificial intelligence system, the dataset combines a set of code-executing agents, several proprietary models including a custom tabular language model, and privacy-enhancing technologies to generate high-quality synthetic data from scratch on demand.
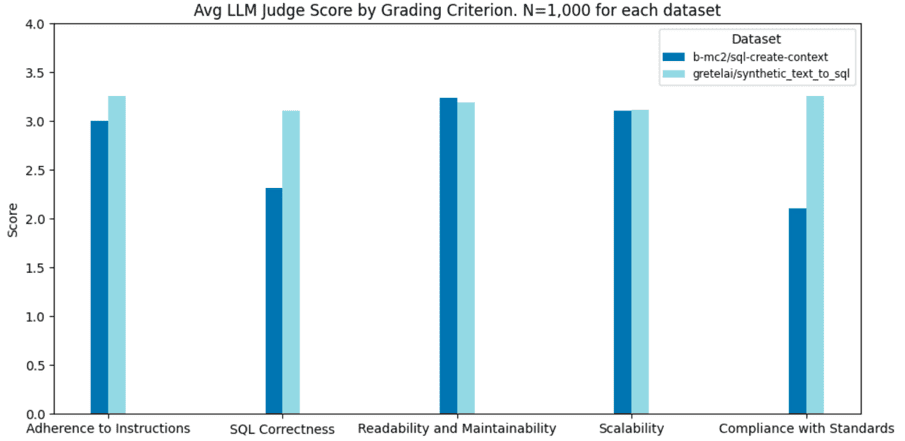
In an independent manual evaluation, Gretel surpassed the b-mc2/sql-create-context dataset in assessment criteria such as SQL standard compliance (+54.6%), SQL query correctness (+34.5%), and text query alignment (+8.5%).
In addition to text-to-SQL query pairs, the dataset includes explanations in plain English describing the SQL code, facilitating end-user understanding and extraction of insights, along with additional attributes of complexity and query type.
Gretel encompasses all SQL constructs, including subqueries, joins, aggregation, window functions, and the set operator.
The dataset is available on Hugging Face under the Apache 2.0 license.











