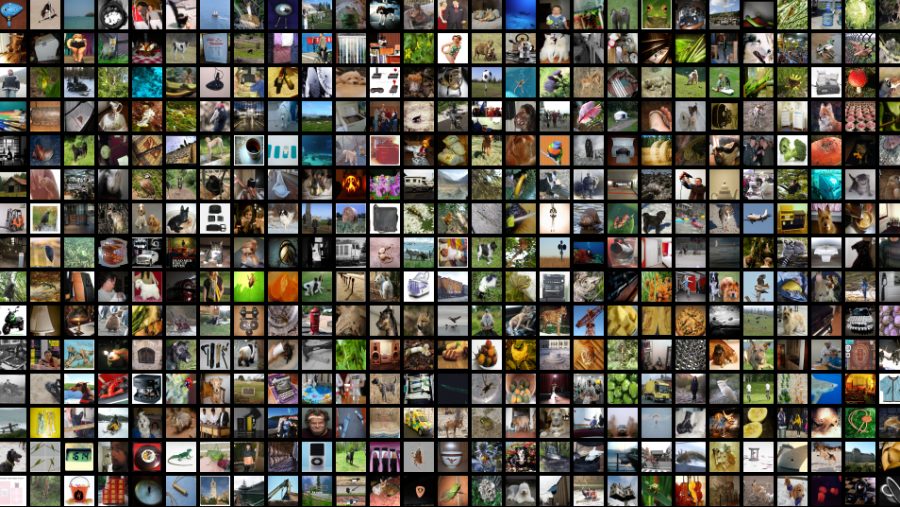
Tencent AI has now released the largest open-source, multi-label image dataset – Tencent ML Images. It contains nearly 18 million images, multi-labeled with up to 11,166 categories.
While big corporations like Google and FAIR have built even more massive, labeled datasets, they still keep them as proprietary and internal. The largest available dataset up to now was Google’s Open Images, containing around 9 million labeled images.
Now, Tencent’s ML Images has taken the lead as the biggest annotated image dataset with 17,609,752 training and 88,739 validation image URLs. It was built to serve the research communities as well as SMEs who can only afford to use open-source datasets.
ML Images was built collecting images from existing image datasets, i.e., Open Images and ImageNet. Both class vocabularies of these datasets were merged into one unified vocabulary and organized in a semantic hierarchy using WordNet. Redundant classes were removed, and the dataset was finally left with something more than 11 thousand categories.
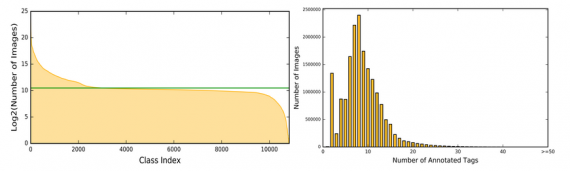
To verify the quality of the merged image dataset, Tencent conducted representation learning experiments with a popular deep neural network model – ResNet 101. The researchers showed that ResNet-101 could be efficiently trained with the novel dataset. To achieve this goal, they additionally contributed to a new loss function that takes care of the large class imbalance in the dataset.
This represents an important contribution to the machine learning community, and it is expected to foster the development of new and improved methods in computer vision. Tencent has released the new Tencent ML Images database along with trained Resnet-101 checkpoints, as well as the complete code for data preparation, pre-training, fine-tuning and feature extraction. The Github repository contains the procedure for downloading the dataset, the models and all the code.
More about the creation of the largest multi-label image dataset – Tencent ML Images and the experiments on ResNet-101 can be read in the published paper.





[…] the better. Ideally, you want thousands of labeled images. The largest publicly available set is ML Images from Tencent, with 18 million images in 11,000+ categories. The second-largest is… Read more »
[…] and bigger than 20,000 categories. It used to be essentially based in 2012, and simplest last yr, Tencent released a database that’s bigger and extra […]
[…] different images and more than 20,000 categories. It was founded in 2012, and only last year, Tencent released a database that is larger and more […]
[…] feeble to be based fully in 2012, and extremely most sensible final three hundred and sixty 5 days, Tencent released a database that is increased and extra […]
[…] any case, the shortage of manageable new datasets, the excessive value of image-set improvement, the reliance on ‘previous […]
[…] any case, the scarcity of manageable new datasets, the high cost of image-set development, the reliance on ‘old favorites’, and the […]
[…] any case, the shortage of manageable new datasets, the excessive value of image-set growth, the reliance on ‘outdated favorites’, […]
[…] any case, the shortage of manageable new datasets, the excessive value of image-set growth, the reliance on ‘previous favorites’, […]
[…] any case, the shortage of manageable new datasets, the excessive price of image-set improvement, the reliance on ‘outdated […]
[…] any case, the scarcity of manageable new datasets, the high cost of image-set development, the reliance on ‘old favorites’, […]
[…] any case, the scarcity of manageable new datasets, the high cost of image-set development, the reliance on ‘old favorites’, and the […]