
A group of researchers from SenseTime Research, NLPR, and Nanyang Technological University has proposed a novel method that generates a video of a person talking, given audio signal and a portrait image.
In their new paper, named “Everybody’s Talkin’: Let Me Talk as You Want”, the group proposes an interesting approach towards video synthesis that achieves superior results compared to existing methods. The proposed method learns to factorize each frame of the video to per-frame parameter spaces such as facial expression, geometry, pose, etc.
A recurrent neural network is then used to translate input audio to a sequence of expression parameters. These parameters are then used for the synthesis of photo-realistic videos of a person speaking. The architecture of the method can be seen in the image below.
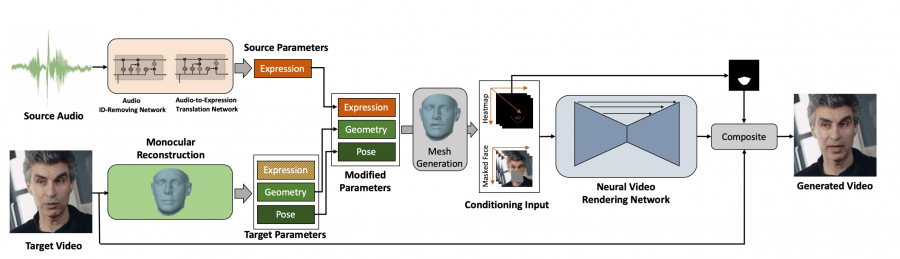
Researchers evaluated the proposed method both quantitatively and qualitatively on the talking face benchmark dataset GRID as well as on a novel dataset that was collected for this purpose. They used image quality metrics to evaluate the quality of the generated video in terms of its frames. Also, an ablation study was performed to further evaluate the method.
Results showed that the method outperforms existing methods for realistic video generation given audio input. Sample outputs from the method can be found on the project’s website. More in detail about the models and the evaluations can be read in the paper published on arxiv.


