Facebook AI has announced that they have developed a new approach to object detection called DETR which relies on Transformers to provide end-to-end object detection which matches the performance of state-of-the-art methods.
In the past decade, object detection has risen from a very challenging and difficult task to an easy problem solved by deep convolutional neural networks. During this transition, many different neural network architectures have been proposed, increasing object detectors’ performance year by year. However, these models often include feature extractor part, proposals component for generating candidate regions of interest, and they are often followed by a procedure called non-maximum suppression for filtering those regions.
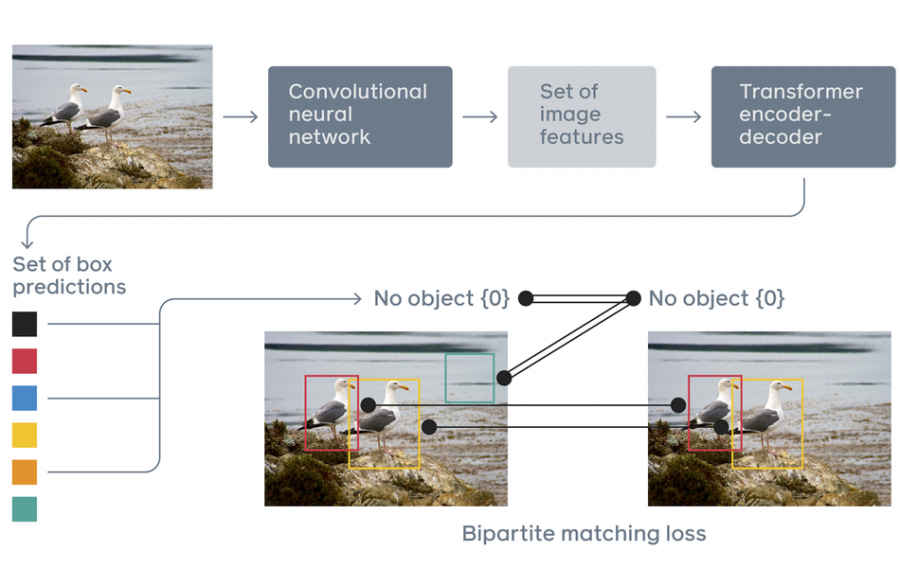
End-to-end object detection models were inferior to these architectures up till now. Facebook’s DETR in fact represents the first end-to-end object detection model that compares in terms of performance to the more classical neural network architectures for detection. The new model proposed by researchers at Facebook AI integrates the popular Transformer as the central building block of the new end-to-end architecture. This changes the traditional object detection scheme in a way that bounding boxes and classes are directly inferred from the CNN features by using the transformer encoder-decoder which is said to be able to capture relations between objects and other objects as well as objects and the image.
“Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. Previous attempts to use architectures such as recurrent neural networks for object detection were much slower and less effective because they made predictions sequentially rather than in parallel.”
According to researchers, Transformer’s goal within this framework is to learn an image-to-set mapping which actually corresponds to the re-framed task of object detection: predict a list of objects with their classes and locations in a given image.
DETR was evaluated on the popular COCO benchmark and it was compared to the well-known Faster R-CNN model. The results showed that DETR performs on-par with Faster R-CNN and researchers showed how the method can generalize to other tasks such as segmentation.
The implementation of the method was open-sourced and it is available on Github. More details about DETR can be found in the paper or in the official blog post.