Facebook AI Research (FAIR) has announced that it is open-sourcing a new inference framework for online speech recognition called wav2letter@anywhere.
The framework was built with the purpose of having real-time transcription systems that are comparable with state-of-the-art methods for speech recognition in terms of accuracy and performance. As researchers from FAIR mention, there are a number of applications which besides good accuracy require low latency or computational efficiency, for example, video captioning or on-device transcription. Wav2letter@anywhere was designed to address this issue and researchers and engineers from Facebook have put efforts into modifying algorithms and implementation to meet this goal.

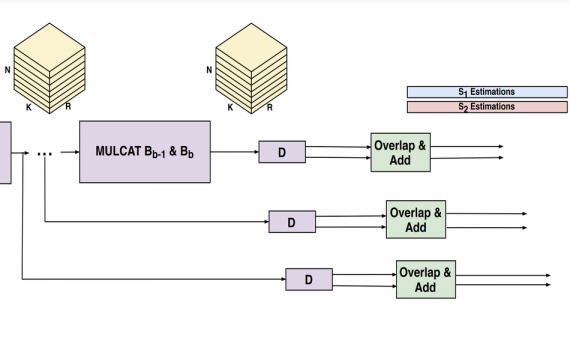
The framework contains a streaming API that is efficient and modular enough to support various speech, recognition models. This API is flexible and portable, meaning it can be easily used on different platforms. Besides the API, the novel framework contains a number of optimizations. For example concurrent streams, optimized low-latency acoustic models, improved model architectures, etc. Wav2letter@anywhere is written in C++ and it can run as a stand-alone application.
Researchers reported that the fully convolutional acoustic model which is embedded into the framework achieves 3x improvement in terms of throughput on certain models and it achieves state-of-the-art performance on the LibriSpeech benchmark.
More about the framework Wav2letter@anywhere can be read in the paper or in the project’s wiki page.