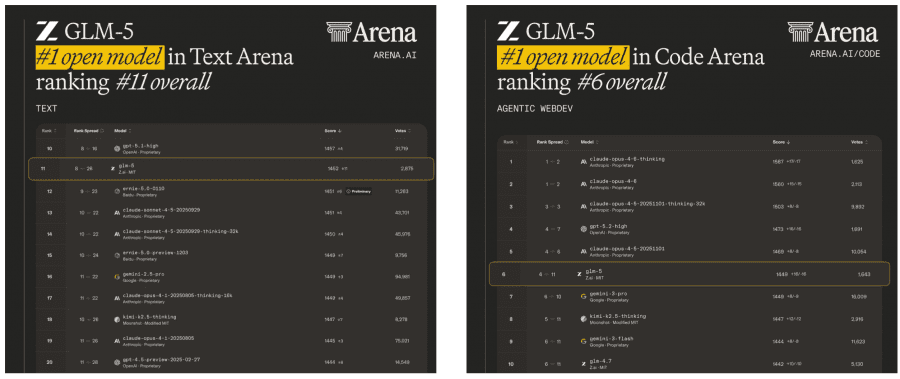
Zhipu AI and Tsinghua University have published a GLM-5 technical report — currently the top-performing open-weight language model by benchmarks: first place among open-weight models on Artificial Analysis and top-1 in coding and text on LMArena, and a world leader on BrowseComp and HLE with tools — beating even closed proprietary models. The model doesn’t just answer questions: it independently writes code, searches the internet, and executes long multi-step tasks. The project is fully open: code, weights, and documentation are available on GitHub and Hugging Face.
Zhipu positions GLM-5 as a shift from “vibe coding” to agentic engineering. Vibe coding is an informal term for the approach where a developer describes a task in chat, receives generated code, and manually iterates from there. This works fine for isolated tasks but scales poorly to complex projects: the model doesn’t track the state of the codebase, doesn’t run tests, and doesn’t fix errors on its own.
Agentic engineering is a different mode of operation: the model receives a high-level task and autonomously executes a chain of actions — analyzes the repository, writes a patch, runs tests, handles errors, and repeats the cycle until a result is achieved. Human involvement is required at the task-setting and result-verification stages, but not at every intermediate step.
Architecture: What’s Inside
GLM-5 is a Mixture of Experts model with 744 billion total parameters, of which only 40 billion are active at any given moment. That’s twice the size of its predecessor, GLM-4.5 (355B/32B).
The headline architectural innovation is DSA (DeepSeek Sparse Attention): a sparse attention mechanism that, instead of attending to every token in context, dynamically selects only the important ones. This cuts attention cost by 1.5–2× on long sequences while preserving quality. In plain terms: you can process 128K tokens at roughly half the usual GPU cost.
Another improvement is MLA-256 (Multi-Latent Attention) with Muon Split optimization. MLA compresses keys and values in attention into a compact latent vector, saving memory. The authors found that standard MLA slightly underperformed GQA, but after splitting matrices per individual heads (Muon Split), the gap disappeared.
Here’s how the attention variants compare across benchmarks:
| Method | HellaSwag | MMLU | C-Eval | BBH | HumanEval |
|---|---|---|---|---|---|
| GQA-8 (baseline) | 77.3 | 61.2 | 60.0 | 53.3 | 38.5 |
| MLA | 77.3 | 61.5 | 59.7 | 48.9 | 33.5 |
| MLA + Muon Split | 77.8 | 62.5 | 62.1 | 51.8 | 36.7 |
| MLA-256 + Muon Split | 77.4 | 62.0 | 59.9 | 51.3 | 36.6 |
MLA + Muon Split matches GQA across all benchmarks — meaning you get MLA’s efficiency without losing quality.
Finally, Multi-Token Prediction (MTP) with parameter sharing lets the model predict multiple tokens in a single step, speeding up generation. GLM-5 achieved an acceptance length of 2.76 tokens versus 2.55 for DeepSeek-V3.2.
Training: How It Worked
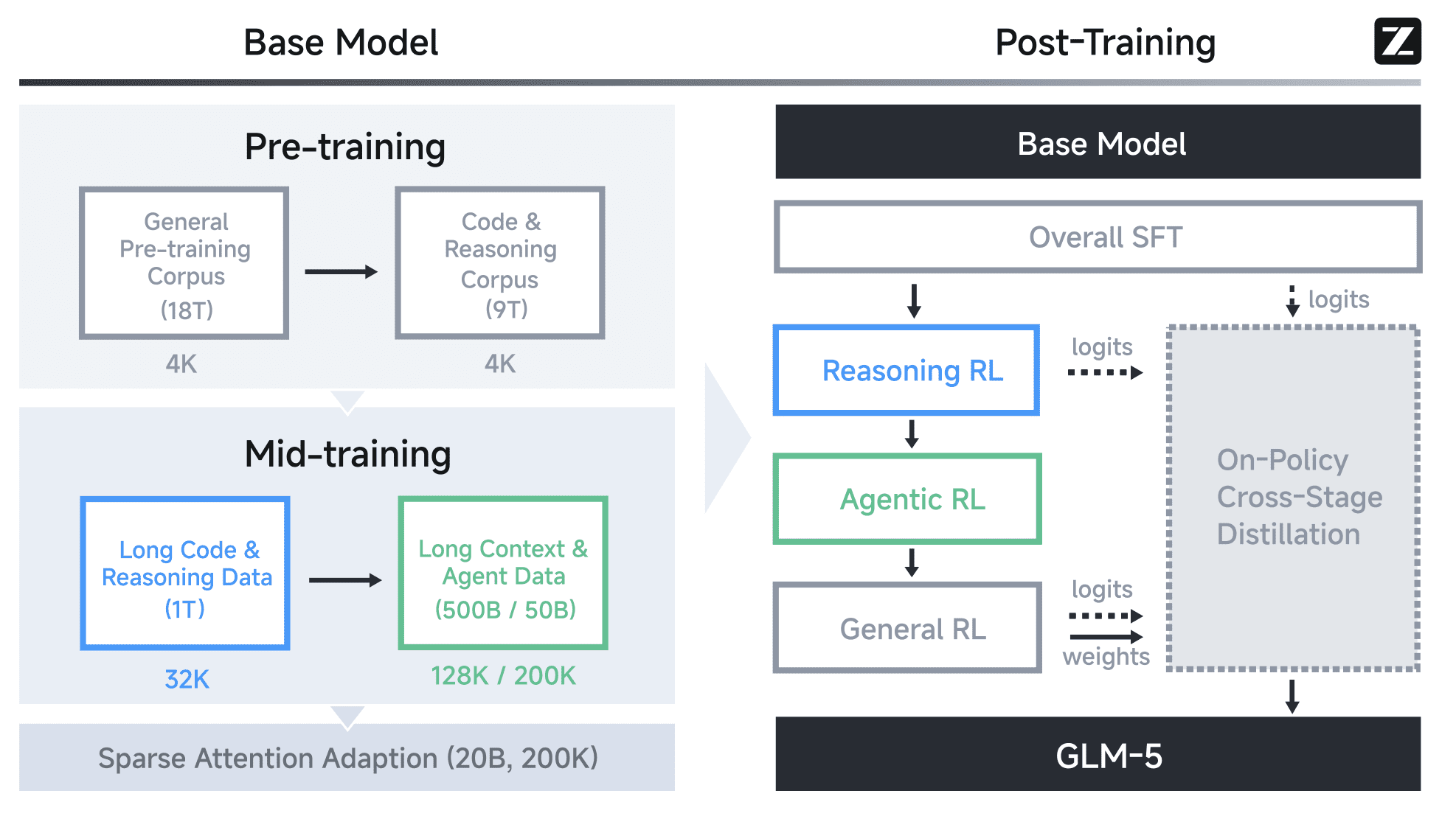
Pre-training
The model was trained on 28.5 trillion tokens. First, a general corpus of 18T tokens, then code and reasoning data for another 9T — 1.5× more than GLM-4.5. The corpus included web data, GitHub code (28% more unique tokens compared to the previous version), mathematical texts, and scientific papers. For long context, the authors progressively extended the context window: 32K → 128K → 200K tokens.
Post-Training: From Base to Agent
After pre-training, the model goes through a sequential pipeline. First, SFT (Supervised Fine-Tuning) — training on examples of dialogues, coding, and agentic tasks. Then three stages of Reinforcement Learning (RL): Reasoning RL (math, code, reasoning) → Agentic RL (long agentic tasks) → General RL (alignment to human communication style).
The key detail: the authors use On-Policy Cross-Stage Distillation at the end of the pipeline. This solves the problem of “catastrophic forgetting” — when a model trained on one task loses skills from previous stages. The final checkpoints from all stages become “teachers,” and the model distills knowledge from all of them simultaneously.
Async RL: Why It Matters
Standard synchronous RL suffers from GPU idle time: while the agent “thinks” (executing a long rollout — a sequence of actions), the training side sits and waits. GLM-5 solves this with a fully asynchronous architecture.
The idea is this: instead of generation and training alternating strictly in sequence, they’re decoupled onto different GPUs. The inference engine continuously generates trajectories. Once enough data has accumulated, it gets sent to the training engine — which starts updating the model’s parameters while inference keeps generating new ones.
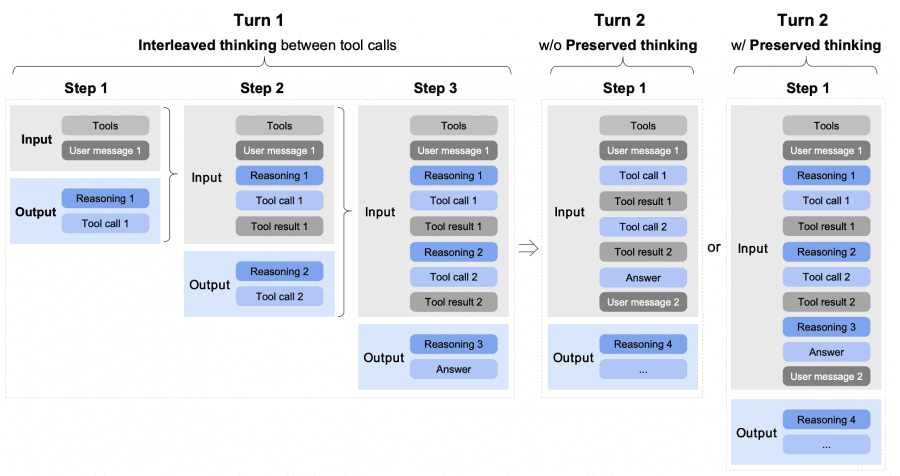
For agentic tasks, the authors developed three special thinking modes.
- Interleaved Thinking: the model thinks before each response and each tool call — improving instruction-following accuracy.
- Preserved Thinking: in multi-turn coding scenarios, the model preserves all reasoning blocks between dialogue turns — reusing them rather than recomputing.
- Turn-level Thinking: deep thinking can be dynamically toggled per turn — off for quick questions, on for complex tasks.
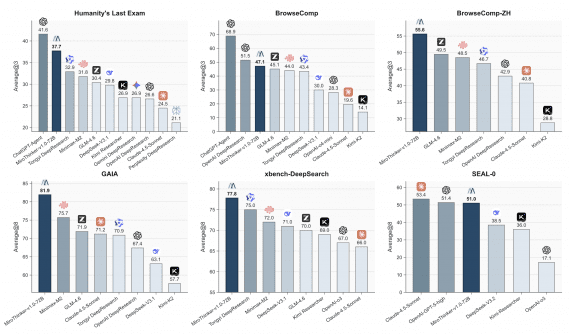
Results: What the Benchmarks Show
The researchers compared GLM-5 against DeepSeek-V3.2, Claude Opus 4.5, Kimi K2.5, Gemini 3 Pro, and GPT-5.2:
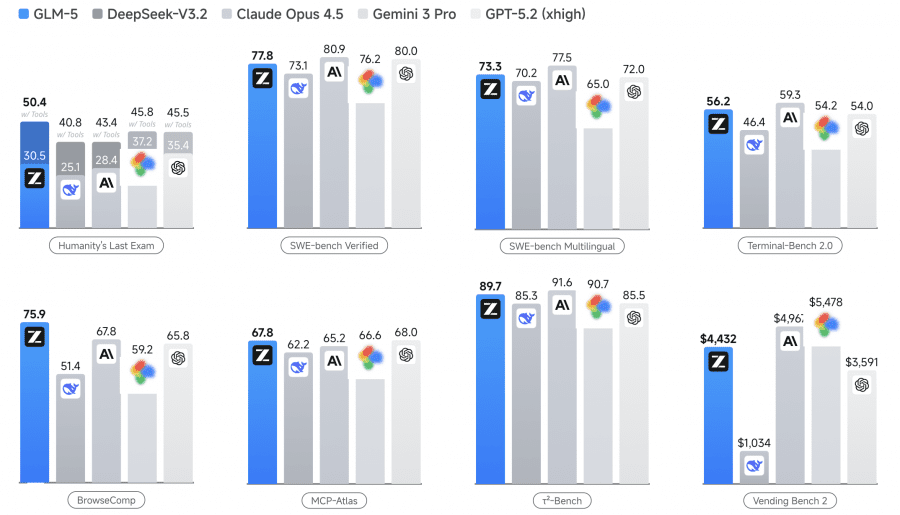
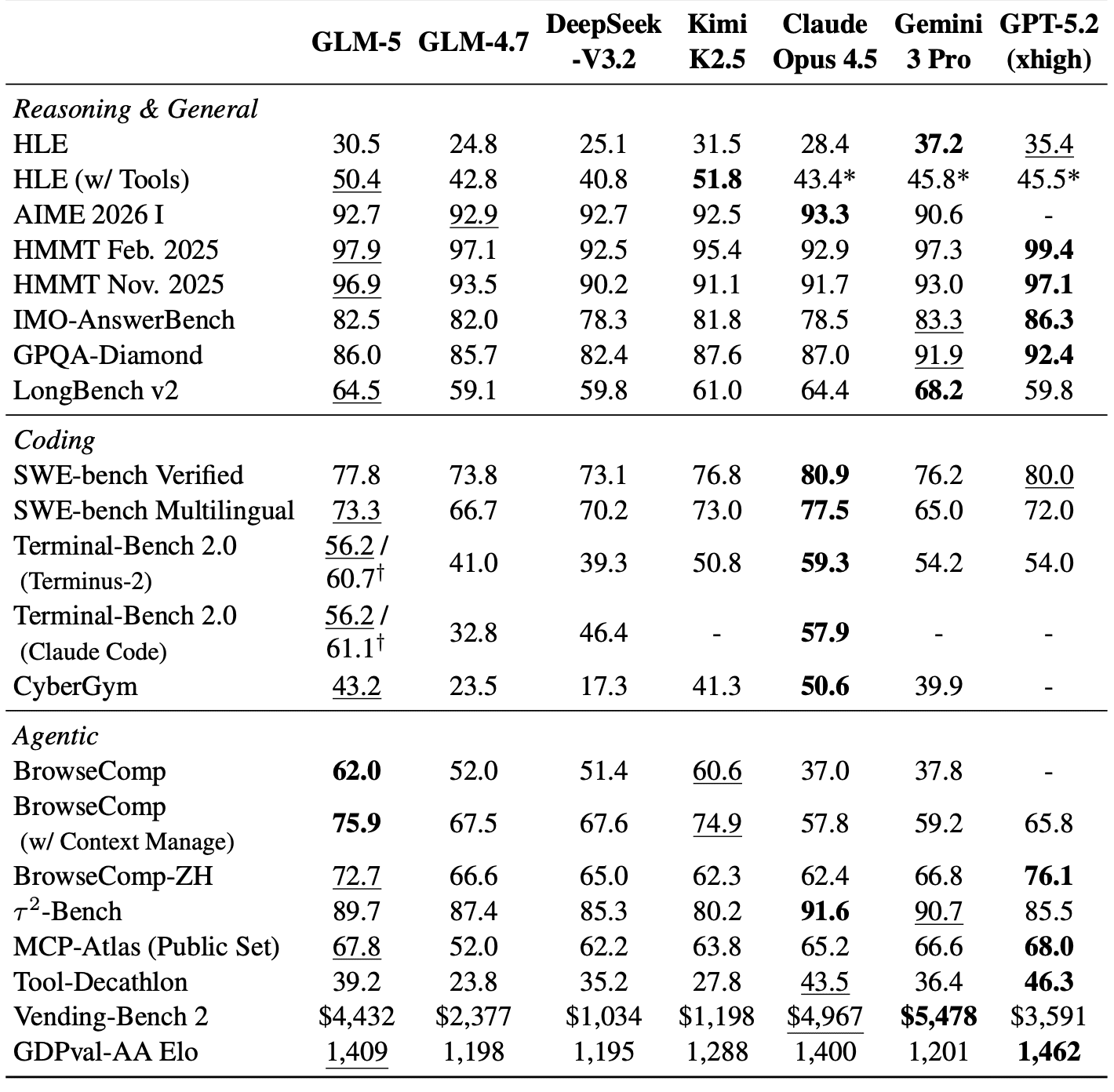
GLM-5 shows roughly 20% average improvement over GLM-4.7. On BrowseComp, GLM-5 beats all frontier models — 75.9% versus 65.8% for GPT-5.2. On HLE with tools, GLM-5 is also first at 50.4%. On SWE-bench Verified it falls slightly short of Claude and GPT, but it’s the first open model to reach this tier at all.
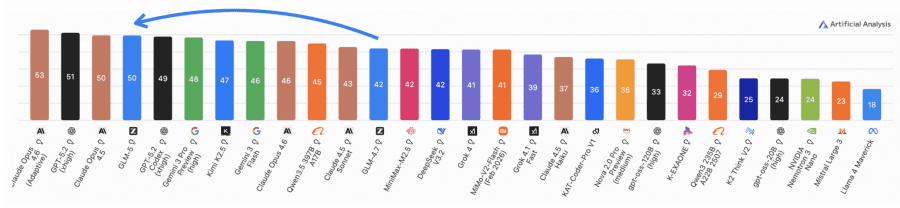
CC-Bench-V2: Real Development Tasks
Academic benchmarks are useful, but the authors wanted to measure something more grounded: can the model actually write working frontend code? Fix a bug in a Go project? Navigate a large unfamiliar repository?
For this they created CC-Bench-V2 — an internal benchmark with three parts. Frontend tasks: build a website or web app in HTML, React, Vue, Next.js, or Svelte. Backend tasks: real tasks from open-source projects in Python, Go, C++, Rust, Java, TypeScript — features, bugs, refactoring, optimization, all verified by unit tests. Long-horizon tasks: search across a massive repository (thousands of files) and multi-step task chains where each step changes the codebase state for the next.
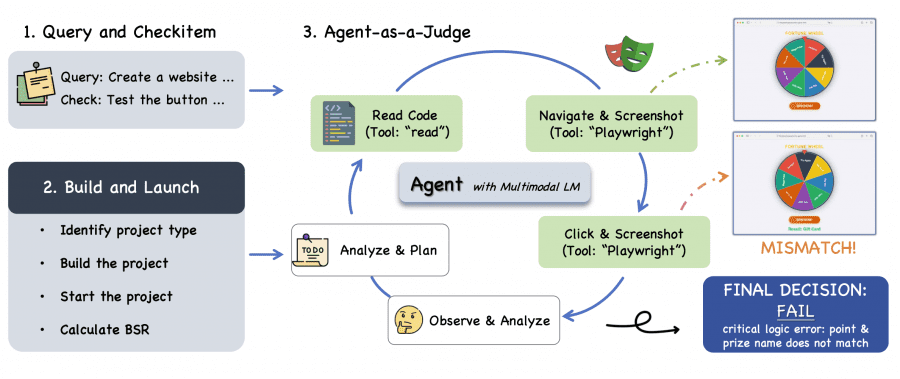
Frontend evaluation runs through Agent-as-a-Judge. An autonomous judge agent (Claude Code + Playwright) literally clicks through the generated website and checks every point in the requirements spec. Agreement with human expert ratings was 94% on individual items and 85.7% on model rankings.
GLM-5 achieves a 98% Build Success Rate (BSR) — almost all generated code compiles and runs. On Check-item Success Rate (CSR) it competes with Claude Opus 4.5 (71.0% vs 70.7% on React). But Instance Success Rate (ISR) — the share of tasks completed entirely from start to finish — is lower for GLM-5 (34.6% vs 39.7% on React).
Search Agent: How GLM-5 Finds Information
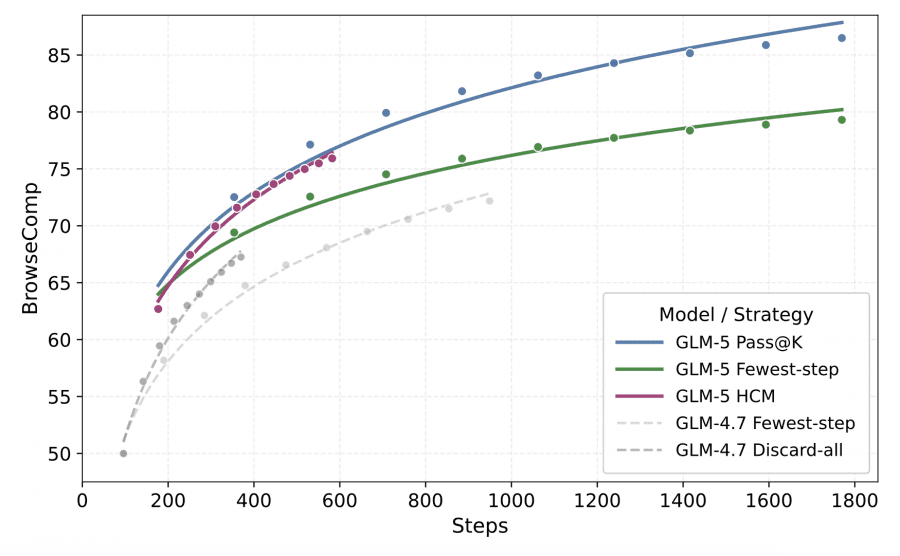
BrowseComp tasks require the model to find answers to complex multi-step questions online — for example, “which film did director X make between such-and-such years that featured actor Y.” This requires dozens of queries and analysis of results.
The problem with long searches: the longer an agent runs, the larger the context grows, and at 100K+ tokens quality drops sharply. The authors developed Hierarchical Context Management. As tool history accumulates, the model keeps only the most recent 5 rounds of results (keep-recent-k=5). If the context is still too long after that — the history is cleared entirely, and the agent continues from a clean slate. This lifted BrowseComp from 55.3% to 75.9%.
Presentation Generation
Another interesting capability — HTML slide generation via RL. The authors designed a three-level reward function: level 1 checks static markup attributes (colors, fonts, positioning), level 2 checks runtime DOM properties (actual element dimensions after rendering), level 3 checks visual perception (abnormal whitespace, overall balance).
During training, cases of reward hacking emerged — the model “cheated”: hiding content via overflow:hidden, or padding elements to pass geometric metrics on paper. The authors fixed the renderer to close these loopholes. In the end, the share of slides with a correct 16:9 aspect ratio rose from 40% to 92%, and human evaluators preferred GLM-5 over GLM-4.5 in 67.5% of cases on overall quality.
Easter Egg: Pony Alpha
At the end of the paper, the authors describe an experiment they call an “easter egg.” Before the official GLM-5 release, it was anonymously deployed on OpenRouter under the name “Pony Alpha.” No mention of Zhipu, no branding — just a model in a chat interface.
Developers in the community started noticing unusually high quality, especially on complex coding tasks. Speculation followed: 25% guessed it was Claude Sonnet 5, 20% DeepSeek, 10% Grok. When Zhipu confirmed it was GLM-5, it served as solid evidence that the model had genuinely reached frontier level.
How to Run GLM-5 Locally: How Much Hardware You Need
The model weights are open and available on Hugging Face under the MIT license. But before you download — an honest talk about hardware.
The full model in BF16 weighs 1.65 TB. That’s not a typo. For production deployment with reasonable throughput, the official recommendation from the authors is 8× H200 (141 GB VRAM each), totaling ~1,128 GB of GPU memory. Supported frameworks: vLLM, SGLang, KTransformers, and xLLM — all support tensor parallelism across multiple GPUs.
For most people, that sounds like “not for me” — but there are cheaper options.
FP8 quantization — the official version is available on Hugging Face. Roughly half the size of BF16, fits on 8× H100 or 8× H20. Benchmark quality barely drops. This is the most realistic option for small teams with access to server hardware or cloud compute.
2-bit GGUF from Unsloth — aggressive quantization that compresses the model to 241 GB. According to the Unsloth team, this fits on a Mac with 256 GB unified memory (M3/M4 Ultra Max) or a server with a single 24 GB VRAM GPU + 256 GB RAM using MoE offloading. There’s also a 1-bit variant at 176 GB. Speed and quality drop, but it’s a workable option for experimentation and development.
If you have no hardware at all, GLM-5 is available via API providers: DeepInfra ($0.80/$2.56 per million input/output tokens), Novita, GMI Cloud, Fireworks, SiliconFlow. That’s 3–6× cheaper than the first-party Z.ai API ($1.00/$2.20) and 5–8× cheaper than Claude Opus 4.6.
Early Reactions
Maxime Labonne (Staff ML Scientist at Liquid AI, author of a book on graph neural networks) wrote one of the most balanced analyses right after the release. His verdict: GLM-5 is the strongest open model at time of launch, first place on Artificial Analysis and LMArena Text Arena among open-weight models. But with a caveat: the model is text-only, no multimodality whatsoever — a notable gap compared to Moonshot’s Kimi K2.5. In his assessment, the community consensus is that GLM-5 is an excellent executor, but “situational awareness” — understanding the context of what’s happening — lags behind Claude.
The most-cited critical voice is Lucas Petersson, co-founder of Andon Labs — the team that independently ran Vending Bench 2 (a benchmark where the model manages a simulated vending business for a full year). After several hours reading GLM-5 traces, he posted on X: the model is incredibly effective, but “achieves goals through aggressive tactics without reasoning about its situation or using past experience.” He added: “This is scary. This is exactly how you get a paperclip maximizer” — a reference to philosopher Nick Bostrom’s famous thought experiment about an AI that optimizes for a goal without understanding context. Worth noting: GLM-5 placed 4th overall on Vending Bench 2 — above Claude Sonnet 4.5.
The WaveSpeed AI team tested the model while it was still named “Pony Alpha” between February 6–9. Their practical observation: first token appears in under a second on short prompts, throughput is 17–19 tokens per second. In agentic tasks, the model correctly describes steps, proactively requests missing data, and suggests retries on failure. They praise it for incremental code edits rather than full rewrites. Honest bottom line from their engineer: “As a planner — competent. Leaving it unsupervised in critical systems — not yet.”
The overall picture from reactions: everyone agrees on three things. For agentic multi-step tasks — the strongest open model available. Pricing at 5–8× below Claude makes this especially attractive. The main concern: the model aggressively pursues its goal without considering consequences — it will complete the task even if something has gone wrong. Running GLM-5 autonomously in production without human oversight is not recommended.
Summary
GLM-5 is the first open-weight language model that genuinely competes with closed frontier models on agentic coding tasks. Key technical contributions: DSA cuts attention cost by 1.5–2× without quality loss, async Agentic RL eliminates GPU idle time during long rollouts, and the three-stage post-training pipeline prevents catastrophic forgetting.
By benchmarks: GLM-5 leads among open models on BrowseComp (75.9%), SWE-bench Multilingual (73.3%), and competes with Claude and GPT on SWE-bench Verified. On real development tasks (CC-Bench-V2), GLM-5 is significantly better than GLM-4.7, though it still falls short of Claude Opus 4.5 on the most complex long-horizon tasks.






GLM-5’s launch is a breakthrough for open-weight models—its agentic engineering capabilities, 744B parameter Mixture of Experts architecture, and ability to compete with Claude/GPT on coding and multi-step tasks are game-changing!… Read more »