JigsawGAN is a self-supervised generative neural network model that has been trained on a puzzle-solving task. The model accepts chaotically located parts of the image as input and outputs the original image at the output. The neural network does not require additional information about the image to find a solution.
JigsawGAN bypasses alternative approaches for quantitative and qualitative metrics.
Previous approaches for solving puzzles
The task of assembling the puzzle assumes that the image is cut into equal square pieces. The model should reconstruct the image based on the information from the parts. Standard algorithms for solving puzzles use information about the boundaries of the pieces to find a solution. However, such solutions ignore the semantic information stored in the parts of the image. JigsawGAN addresses this limitation and uses semantic information to find a solution.
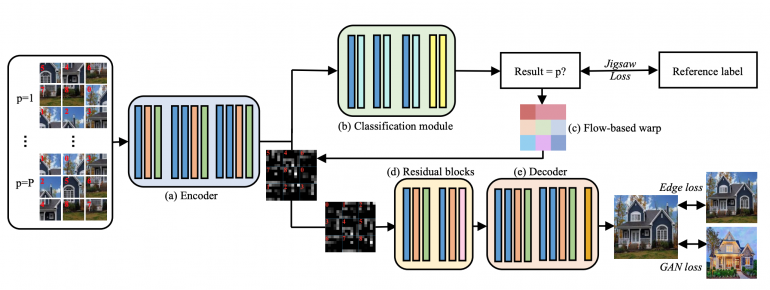
The JigsawGAN architecture
Researchers have developed a multitasking pipeline that includes two stages:
- Classification of puzzle permutations;
- GAN model that reconstructs features for images in the correct order.
The classification model is limited to artificially generated labels that correspond to the shuffled pieces of the puzzle. GAN extracts semantic features from image parts.