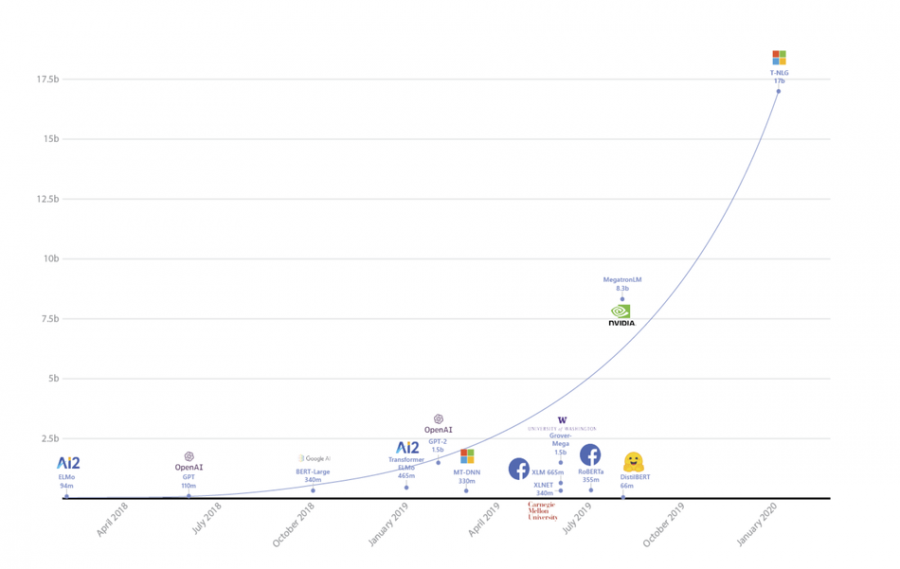
Microsoft announced that it has trained a massive, 17-billion parameter language model that outperforms current state-of-the-art models on many NLP tasks.
Turing-NLG, as the new model was called has almost double the number of parameters of the previous largest model by NVIDIA which had around 8.3 billion parameters, and more than 50 times the number of parameters of BERT. It is a transformer-based generative model that can generate sequences of words to complete open-ended text generation tasks. The model has 78 transformer layers with a hidden size of 4256 and 28 attention heads.
To make the training of such a large model possible researchers and engineers from Microsoft have leveraged several advances both in hardware and software parallelization. They used NVIDIA DGX-2 setup with multiple GPUs that communicate with the improved InfiniBand connections. The model was sliced using tensor slicing across four NVIDIA V100 GPUs and using NVIDIA’s Megatron framework. Last but not least, they used DeepSpeed to increase batch size, reduce model parallelism and reduce training time.
Microsoft researchers presented a demo of their billion-scale model which was trained for several tasks: freeform text generation, question answering, and text summarization. T-NLG is the largest NLP model ever trained and shows superior results on many of the standard language tasks. The model, unfortunately, was not open-sourced and Microsoft is planning to integrate it into some of its products.
More about Turing-NLG can be read in the official blog post.


