
The so-called “green screens” are the most common technique for adding custom backgrounds to a foreground object picture, and they have been widely adopted in areas such as film production. It is often the case that the foreground objects are people therefore the term “human matting” refers to the prediction of matte for segmenting people out of images and videos.
In a recent project, a group of researchers from the University of Hong Kong and SenseTime Research has developed a lightweight neural network that eliminates the need for using the green screen.
Their method, based on deep convolutional neural networks allows processing human matting with high precision in real-time. Researchers, in fact, propose a framework for human matting which consists of several steps and can tackle matting under changing scenes. The proposed framework has three subsequent steps: human matting using the novel MODNet (matting objective decomposition network), self-supervised fine-tuning, and smoothing using a newly proposed one-frame-delay trick. A simple scheme of the framework is shown in the image below.
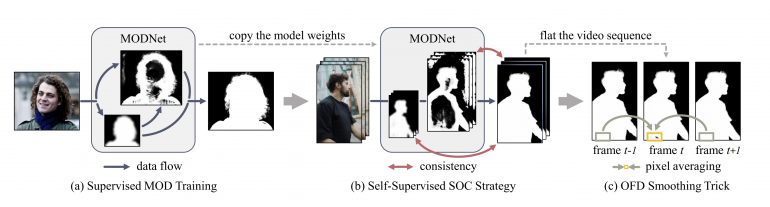
As part of this project, researchers also introduced a benchmark for human matting. They proposed the novel PHM-100 benchmark for human matting that contains 100 finely annotated portraits. Quantitative and qualitative experiments were conducted to measure the performance of the proposed framework but also compare it to existing state-of-the-art methods. The results showed that the method outperforms all other methods in the quantitative analysis. Researchers also showed that the method is computationally efficient.
More details about the network architecture, the experiments, and results can be found in the paper published on arxiv. The implementation of MODNet was open-sourced and can be found on Github.


