Chatbots are everywhere today. Have you noticed how more and more business websites have a chatbot popping up on their home page? And this is only one out of multiple and diverse examples of Natural Language Processing (NLP) and Natural Language Understanding (NLU) application. Potential of NLP and NLU seems to be unlimited, and the general perception is that we are only at the beginning of this journey.
Major tech giants are opening specialized research divisions to explore this field. Intel is not an exception, and the latest NLP offering, called NLP Architect, comes from the Intel AI Lab. This is an open source library, created as a platform for future research and collaboration of developers.
NLP Architect Overview
The team of NLP researchers and developers from Intel AI Lab have been exploring the state-of-the-art deep learning topologies and techniques for NLP and NLU. As a result of this work, they’ve presented set of features, which are interesting from both research perspectives and practical applications. So, the current version of NLP Architect includes the following features:
- NLP core models that allow robust extraction of linguistic features for NLP workflow: for example, dependency parser (BIST) and NP chunker;
- NLU modules that provide best in class performance: for example, intent extraction (IE), name entity recognition (NER);
- Modules that address semantic understanding: for example, colocations, most common word sense, NP embedding representation (e.g., NP2V);
- Components instrumental for conversational AI: for example, Chatbot applications, including dialog system, sequence chunking, and IE;
- End-to-end DL applications using new topologies: for example, Q&A, machine reading comprehension.
All the above models are provided with the end-to-end examples of training and inference processes. Moreover, Intel team has included some additional functionalities that is often used when deploying this kind of models. These are data pipelines, common functional calls, and utilities related to NLP.
The library consists of separate modules for easy integration. You can see the general framework of NLP Architect depicted in the figure below.

NLP/NLU Components
And now for you to understand better, what it’s all about, let’s dig deeper into some of the library’s components.
Sequence Chunker. Phrase chunking is a basic NLP task that consists of tagging parts of a sentence syntactically. For instance, the sentence:
The quick brown fox jumped over the fence.
can be divided into 4 phrases: “The quick brown fox” and “the fence” are noun phrases, “jumped” is verb phrase and “over” is a prepositional phrase.
The Sequence Chunker model of NLP Architect comes with several options for creating the neural network topology depending on what input is given, i.e., tokens, POS, embeddings, char features.
Noun Phrase Semantic Segmentation. Noun Phrase (NP) has a noun or pronoun as its head and a number of dependent modifiers. The most basic division of the semantic segmentation is into two classes:
- descriptive structure — a structure where all dependent modifiers are not changing the semantic meaning of the head (e.g., “hot pizza”);
- collocation structure — a sequence of words or term that co-occur and change the semantic meaning of the head (e.g., “hot dog”).
The model trains multilayer perceptron (MLP) classifier in order to conclude the correct segmentation between these two classes for the given noun phrase.
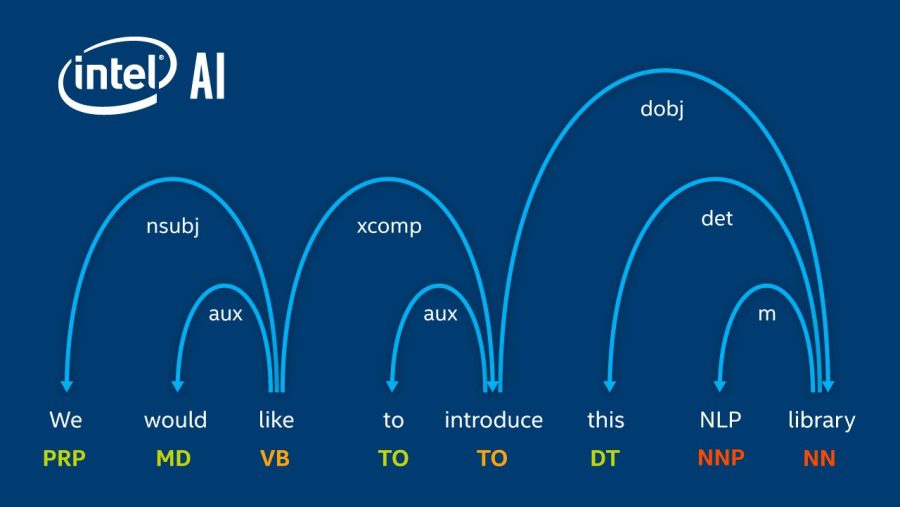
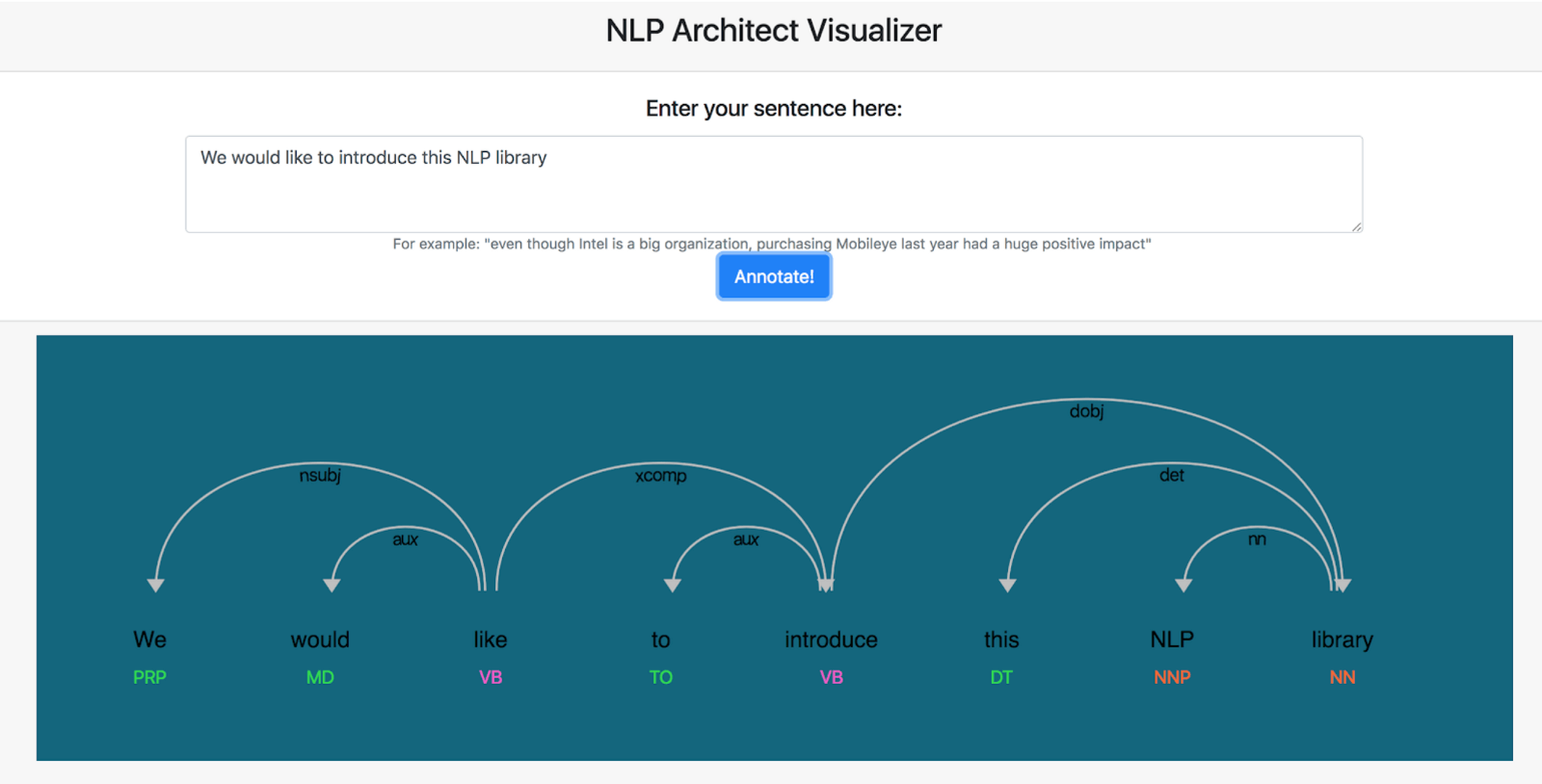
Dependency Parser executes grammatical analyses of the sentences; dependency parsing focuses on the relationships between words in a sentence (marking things like primary objects and predicates). NLP Architect includes graph-based dependency parser that uses BiLSTM feature extractors.
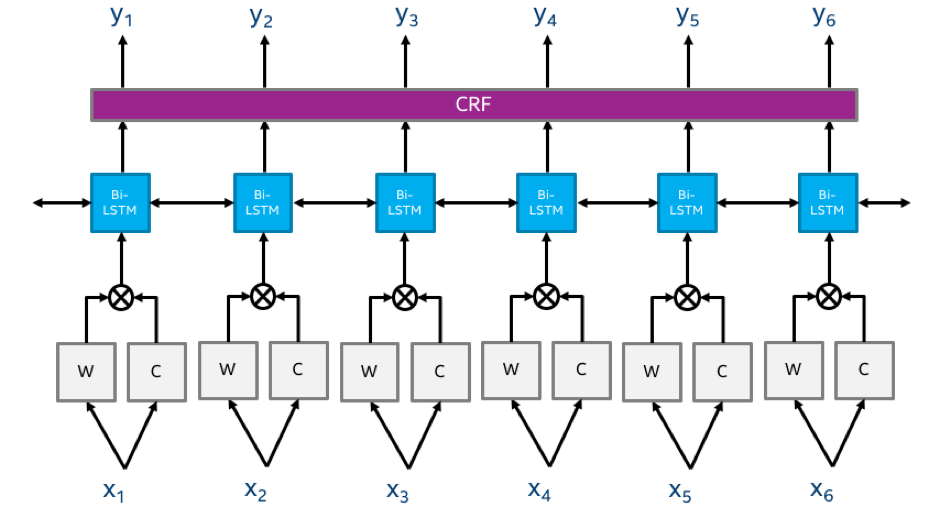
Named entity recognition (NER) implies the classification of words or phrases into the predefined groups or marking them as non-interesting. Examples of entity groups include names, numbers, locations, currency, dates, organizations. Sometimes it can be relatively easy to identify the entity group of words or phrases by the shape of the words, pre-built lexicons, part-of-speech analysis or combination of the above features. However, quite often, those features are not known or even do not exist. In such cases, the context provides the indication of whether a word or a phrase is an entity.
The NER model in NLP Architect is based on the Bidirectional LSTM with Conditional Random Field sequence classifier. A higher-level overview of the model is provided below
Intent Extraction is a type of NLU task that helps to understand the kind of action conveyed in the sentences and all its participating parts. If the sentence is:
“Siri, can you please remind me to pick up my laundry on my way home?”
the algorithm defines an action (“remind”), an assignee that has to do the action (“Siri”), an assignee that the action applies to (“me”) and an object of the action (“to pick up laundry”).
Most Common Word Sense. The goal of this algorithm is to extract the most common sense of a target word. It receives a target word as an input and outputs the senses of this word, each with a corresponding score according to the most commonly used sense in the language.
End-to-end Examples
As it was already mentioned, NLP Architect library also includes some end-to-end models. Let’s have a short overview of two of them.
Reading Comprehension. This directory contains an implementation of the boundary model Match LSTM and Answer Pointer network for Machine Reading Comprehension. The idea behind this method is to build a question aware representation of the passage and use this representation as an input to the pointer network, which identifies the start and end indices of the answer.
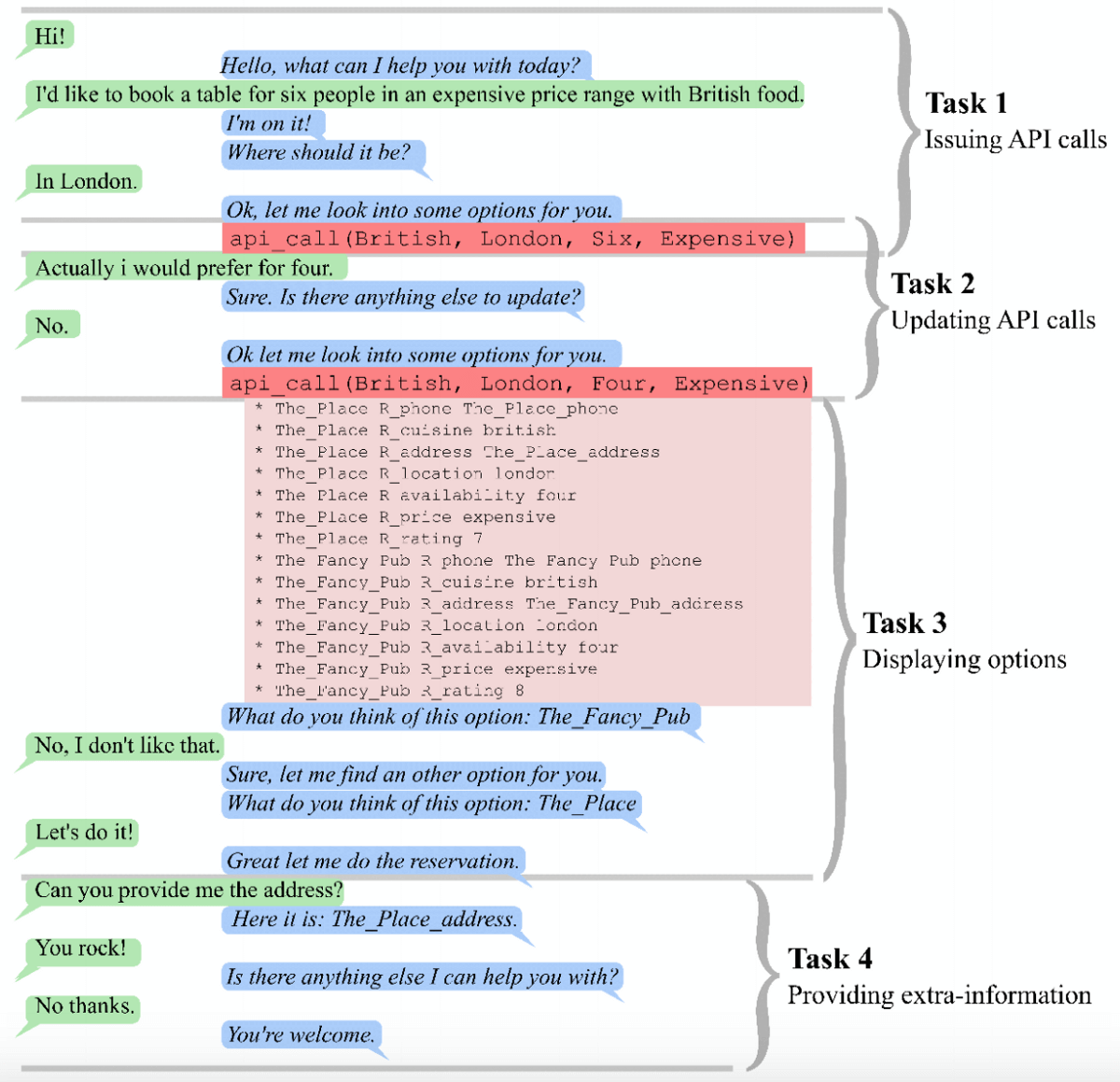
End-to-end Memory Networks for Goal-Oriented Dialogue. This directory contains an implementation of an end-to-end memory network for goal-oriented dialogue in ngraph.
Goal-oriented dialogue is a subset of open-domain dialogue, where an automated agent has a specific goal for the outcome of the interaction. To make it short, the system needs to understand a user’s request and complete a related task within a limited number of dialog turns. This task could be making a restaurant reservation, placing an order, setting a timer, etc. An example of the goal-oriented dialogue is provided below.
NLP Architect Visualizer
The library comes with the NLP Architect Server. It has been designed with the aim of providing predictions across different models in NLP Architect. This server includes a visualizer that demonstrates the model’s annotations in a pretty neat way. Currently, two services are provided: BIST dependency parsing and NER annotations. In addition, a template is provided for developers to add a new service.
Bottom Line
NLP Architect is an open and flexible library of NLP components, which provides opportunities for collaboration of developers. Intel team continues incorporating their research results into this stack so that everyone can reuse what they’ve built and optimized.
Developers can start by downloading the code from the GitHub repository and following the instructions to install NLP Architect. A comprehensive documentation for all the core modules and end-to-end examples can be found here.
In future releases, Intel AI Lab is planning to demonstrate advantages of building NLP components based on the latest deep-learning technologies by providing solutions to sentiment extraction, topic and trend analysis, term set expansion and relation extraction. They are also researching unsupervised and semi-supervised methods that will be introduced into interpretable NLU models and domain-adaptive NLP solutions.









