Вы заметили, что всё больше компаний ставят на свой сайт виджет с ботом? Чат-боты сегодня повсюду. И это только один из многих примеров применения технологий обработки естественного языка (Natural Language Processing, NLP) и понимания естественного языка (Natural Language Understanding, NLU). Потенциал NLP и NLU кажется безграничным. Сейчас ко всем приходит понимание, что мы только в начале длинного пути.
Титаны ИТ-сферы создают специальные исследовательские отделы для изучения этой области. Intel не остался в стороне. Недавно Intel AI Lab выпустила продукт под названием NLP Architect. Это библиотека с открытым исходным кодом, призванная служить основой для дальнейших исследований и сотрудничества разработчиков со всего мира.
Обзор NLP Architect
Команда NLP-исследователей и разработчиков из Intel AI Lab занимается изучением актуальных архитектур глубоких нейросетей и методов обработки и понимания текста. Результатом их работы стал набор инструментов, интересных как с теоретической, так и с прикладной точки зрения.
Вот что есть в текущей версии NLP Architect:
- Модели, извлекающие лингвистические характеристики текста: например, синтаксический анализатор (BIST) и алгоритм для извлечения именных групп (noun phrases);
- State-of-the-art модели для понимания языка: например, определение намерения пользователя (intent extraction), распознавание именованных сущностей (named entity recognition, NER);
- Модули для семантического анализа: например, коллокации, наиболее вероятный смысл слова, векторные представления именованных групп (NP2V);
- Строительные блоки для создания разговорного интеллекта: например, основа для создания чатботов, включающая в себя систему поддержания диалога, анализатор предложений (sequence chunker), система для определения намерения пользователя;
- Примеры применения глубоких end-to-end нейросетей с новой архитектурой: например, вопросно-ответные системы, системы понимания текста (machine reading comprehension).
Для всех вышеупомянутых моделей есть примеры процессов обучения и предсказания. Более того, команда Intel добавила скрипты для решения типичных задач, возникающих при внедрении таких моделей — конвейеры для обработки данных и утилиты, часто применяющиеся в NLP.
Библиотека состоит из отдельных модулей, что упрощает интеграцию. Общий вид фреймворка NLP Architect изображён на схеме ниже.
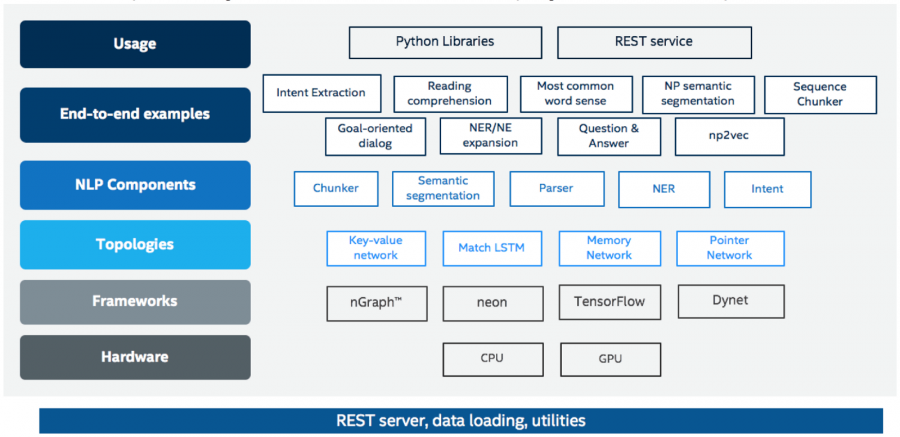
Компоненты для NLP/NLU
Теперь давайте рассмотрим некоторые модули поближе, чтобы лучше понимать, о чём идёт речь.
Анализатор предложений. Анализ предложений (sequence chunking) — одна из базовых задач обработки текста, которая заключается в разделении предложения на синтаксически связанные части. Например, предложение
“Маленькая Саша шла по шоссе”
можно разделить на четыре части: именные группы “Маленькая Саша” и “шоссе”, глагольную группу “шла” и предложную группу “по”.
Анализатор предложений из NLP Architect умеет строить подходящую архитектуру нейросети для разных типов входных данных: токенов, меток частей речи, векторных представлений, символьных признаков.
Семантический сегментатор именных групп. Именная группа (noun phrase) состоит из главного члена — существительного или местоимения — и нескольких зависимых уточняющих членов. Упрощая, можно разделить именные группы на два типа:
- с описательной структурой: зависимые члены не влияют существенно на семантику главного члена (например, “морская вода”);
- с коллокационной структурой: зависимые члены существенно изменяют смысл главного члена (например, “морская свинка”).
Для определения типа именной группы обучается многослойный персептрон. Эта модель используется в алгоритме семантической сегментации предложений. В результате её работы именные группы первого типа распадаются на несколько семантических элементов, а именные группы второго типа остаются едиными.
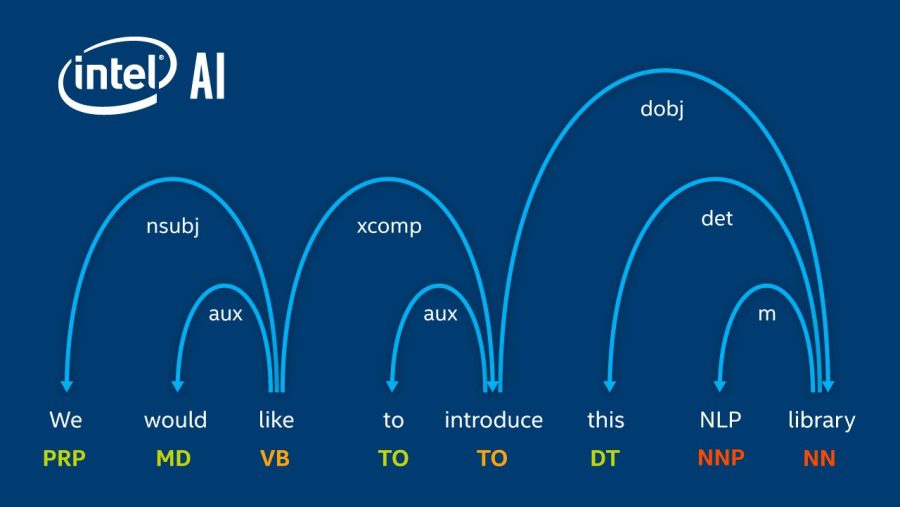
Синтаксический анализатор выполняет грамматический анализ предложений, рассматривая отношения между словами в предложениях и выделяя такие вещи, как прямые дополнения и сказуемые. В NLP Architect входит парсер зависимостей, основанный на графах, который использует BiLSTM для извлечения признаков..
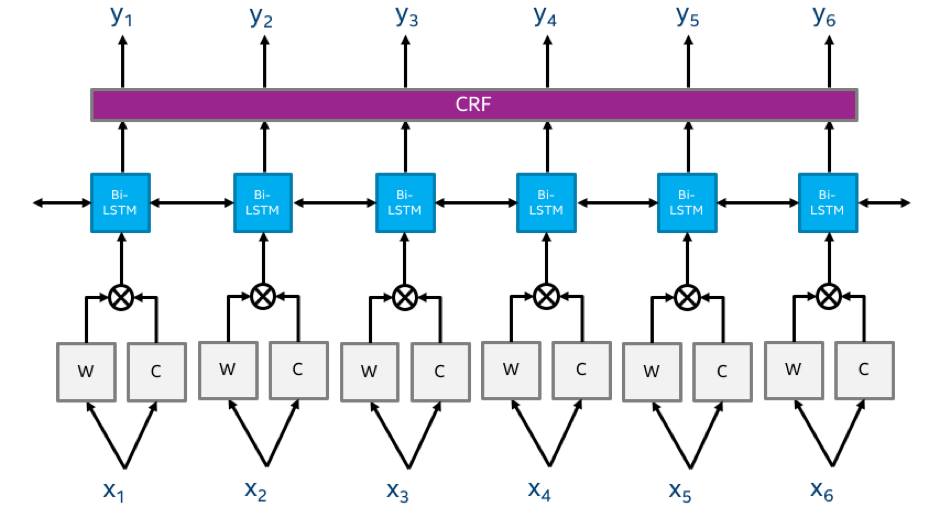
Распознаватель именованных сущностей (NER) выделяет в тексте определённые слова или сочетания слов, относящиеся к некоторому интересующему нас классу. К примерам сущностей относятся имена, числа, места, валюты, даты, организации. Иногда сущности можно довольно легко выделить с помощью таких признаков, как форма слов, наличие слова в определённом словаре, часть речи. Однако довольно часто эти признаки нам не известны или даже не существуют. В таких случаях для того, чтобы определить, является ли слово или словосочетание сущностью, необходимо анализировать его контекст.
Модель для NER в NLP Architect основана на двунаправленной LSTM-сети и CRF-классификаторе. Высокоуровневый обзор модели представлен ниже.
Алгоритм определения намерения пользователя решает задачу понимания языка. Его цель — понять, о каком действии идёт речь в тексте, и определить все вовлечённые стороны. Например, для предложения
“Сири, пожалуйста, напомни мне забрать вещи из прачечной по пути домой.”
алгоритм определяет действие (“напомнить”), кто должен выполнить это действие (“Сири”), кто просит выполнить это действие (“я”) и сам объект действия (“забрать вещи из прачечной”).
Анализатор смысла слова. Алгоритм получает слово на вход и возвращает все смыслы этого слова, а также числа, характеризующие распространённость каждого из смыслов в языке.
Примеры применения End-to-End нейросетей
Уже было сказано, что в библиотеку NLP Architect входят некоторые end-to-end модели. Давайте вкратце рассмотрим две из них.
Понимание текста. В папке с названием reading_comprehension находится реализация модели понимания языка из статьи Machine Comprehension Using Match-LSTM and Answer Pointer. Идея этого метода заключается в построении векторного представления фрагмента текста с учётом вопроса и подаче этого векторного представления на вход нейросети, которая возвращает позиции начала и конца ответа на вопрос в фрагменте.
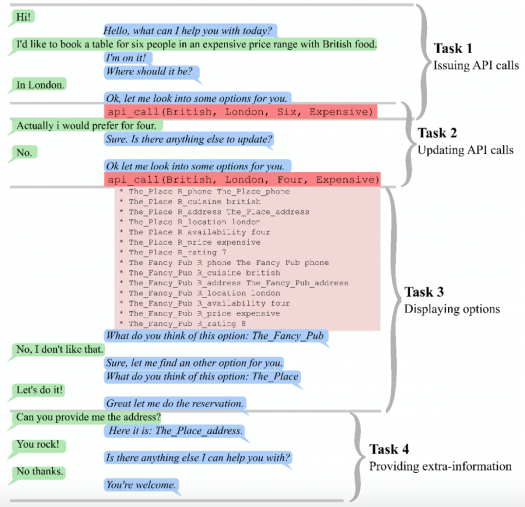
End-to-end нейросеть с памятью для целевого диалога. В папке с названием memn2n_dialogue находится реализация нейросети с памятью (memory network) для поддержания целевого диалога (goal-oriented dialogue).
Во время целевого диалога, в отличие от разговора на свободную тему, автоматическая система имеет определённую цель, которой необходимо добиться в результате взаимодействия с пользователем. Вкратце, системе необходимо понять запрос пользователя и выполнить соответствующую задачу за ограниченное число диалоговых ходов. Задачей может быть заказ столика в ресторане, установка таймера и так далее.
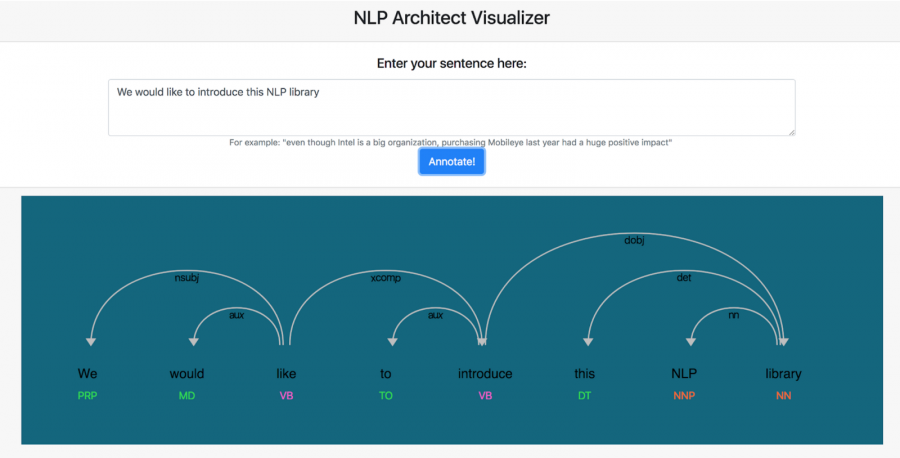
Визуализатор NLP Architect
В библиотеку входит небольшой веб-сервер — NLP Architect Server. Он позволяет легко проверить работу разных моделей NLP Architect. Среди прочего, в сервере есть визуализатор, который стоит довольно красивые диаграммы, демонстрирующие работу моделей. Сейчас визуализацию поддерживают два сервиса — синтаксический анализатор и распознаватель именованных сущностей. Кроме того, есть шаблон, с помощью которого пользователь может добавить визуализацию для других сервисов.
Заключение
NLP Architect — открытая и гибкая библиотека с алгоритмами для обработки текста, которая даёт возможность для взаимодействия разработчиков со всего мира. Команда Intel продолжает добавлять в библиотеку результаты своих исследований, чтобы любой мог воспользоваться тем, что они сделали и улучшили.
Для начала работы достаточно скачать код с репозитория на Гитхабе и выполнить инструкции по установке. Здесь можно найти исчерпывающую документацию для всех основных модулей и готовых моделей.
В будущих релизах Intel AI Lab планирует продемонстрировать преимущества создания алгоритмов анализа текста с помощью новейших технологий глубокого обучения, и включить в библиотеку методы для извлечения тональности текста, анализа тематик и трендов, расширения специализированных лексиконов и извлечения отношений. Кроме того, специалисты из Intel исследуют методы обучения без учителя и частичного обучения, с помощью которых можно создать новые интерпретируемые модели для понимания и анализа текста, способные адаптироваться к новым областям знания.
Перевод — Николай Кругликов, оригинал — Kateryna Koidan