
На прошлой неделе на Google IO исследователи представили Умный Набор (Smart Compose) — новую функцию в Gmail, которая использует машинное обучение, чтобы интерактивно предлагать завершение предложения, позволяя вам отвечать на электронные письма быстрее. Опираясь на технологии, разработанные для Умного ответа (Smart Reply), Умный набор предлагает новые подсказки в составлении ответов на входящее письмо или создании нового с нуля.
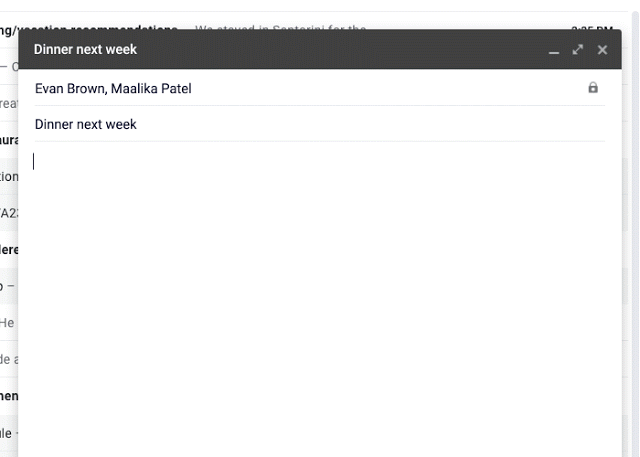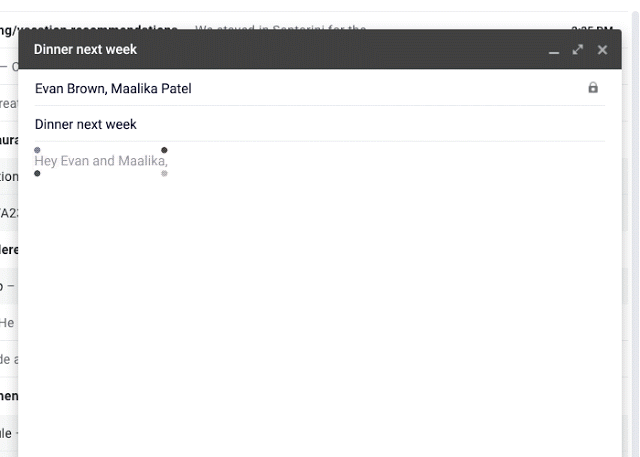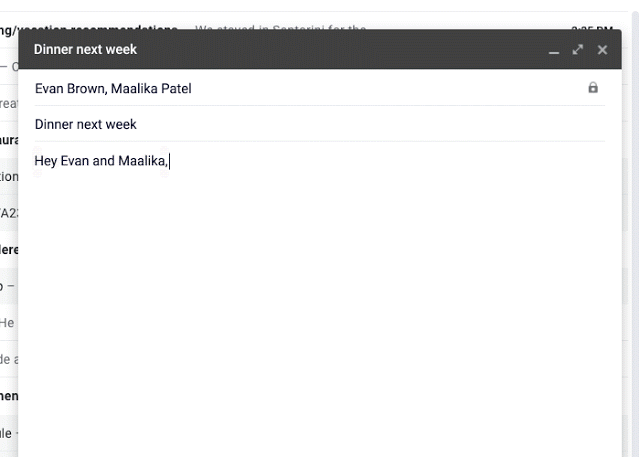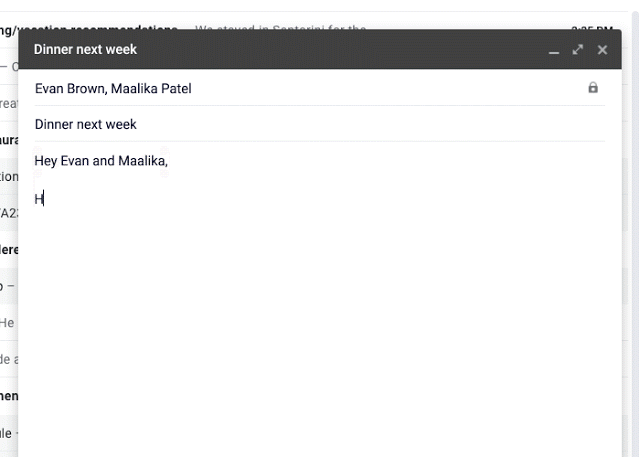
В течение разработки Smart Compose встретились несколько ключевых сложностей:
- Задержка: поскольку Smart Compose обеспечивает предсказания на каждое нажатие клавиши, в идеале оно должно давать ответ в течение 100 мс, чтобы пользователь не замечал задержек. Важно найти баланс сложности модели и скорости вывода подсказок.
- Выборка: Gmail пользуется более миллиарда человек. Чтобы предлагать полезное для пользователя автоматическое завершение предложений, модель должна иметь достаточно вместимости для создания подсказок, учитывающих даже небольшие изменения контекста.
- Честность и конфиденциальность: во время разработки Smart Compose исследователям было необходимо учитывать источники повышенной предвзятости и придерживаться тех же строгих пользовательских стандартов, что и в Smart Reply, будучи уверенными, что их модель никогда не выдаст конфиденциальной информации о пользователе. Исследователи не имели доступа к письмам, что означало, что они должны были разрабатывать и обучать систему машинного обучения на базе данных, которую они сами не могли просматривать.
Поиск правильной модели
Стандартные модели генерации текста, такие как N-грамма (ngram), neural bag-of-words (BoW) и RNN language (RNN-LM) модели, учатся предсказывать следующее слово, основываясь на прошлой последовательности слов. Однако слова, написанные пользователем в текущем письме, служат только “сигналом”, которые модель может использовать для предсказания следующего слова. Модель также берет в расчет тему и текст предыдущего письма (если пользователь отвечает на входящее сообщение).
Один из подходов для добавления дополнительного контекста — рассматривать задачу как “последовательность-в-последовательность” (sequence-to-sequence, seq2seq) задачу машинного перевода, в которой последовательность является конкатенацией (соединением) темы и текста предыдущего письма (если таковое имеется), а целевой последовательностью является письмо, которое пользователь создает в данный момент. В то время как данный подход работает хорошо в смысле качества предсказаний, он не соответствует ограничению по задержке.
Чтобы улучшить это, разработчики скомбинировали модель BoW и модель RNN-LM, которая быстрее seq2seq, немного жертвуя качеством предсказания. В данном гибридном подходе, кодируется тема и предыдущее письмо путем усреднения значений векторов слов (word embeddings) в каждом поле. Далее эти два усредненных вектора соединяются и получившийся вектор передаётся в качестве целевой последовательности для RNN-LM на каждом этапе декодирования (как показывает схема ниже).
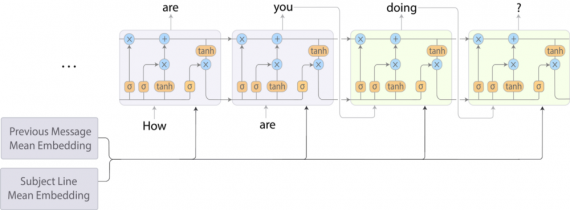
Обучение и работа ускоренной модели
Конечно, когда разработчики решили использовать этот подход, они по-прежнему должны были настраивать различные гиперпараметры и обучать модель на миллиардах примеров, что может быть очень времязатратным. Чтобы ускорить процесс, они использовали полную TPUv2 Pod для выполнения эксперимента. С использованием TPU исследователи получили возможность обучать модель до сходимости меньше чем за один день.
Даже после обучения этой быстрой гибридной модели, изначальная версия Smart Compose, запущенная на CPU, имела среднюю задержку в разы превышающую сто миллисекунд, что является неприемлемым для функции, созданной с целью сохранения времени пользователей.
К счастью, TPU также могут использоваться для значительного ускорения и во время вывода. Перенеся основную часть вычислений на TPU, разработчики улучшили среднюю задержку на десятки миллисекунд, в то время как количество запросов, которые могут быть обработаны одной машиной, значительно увеличилось.
Честность и конфиденциальность
Модели понимания текста могут отражать человеческие когнитивные предубеждения, приводя к нежелательным связям между словами и окончанием предложений. Как Caliskan и другие отметили в своей недавней работе, эти связи глубоко запутаны в текстовых данных, что усложняет создание любой текстовой модели. Исследователи активно исследуют пути дальнейшего снижения потенциальных перекосов в тренировочных процессах. Так как Умный Набор обучен на миллиардах фраз и предложений, кстати, так обучены и модели определения спама, разработчики провели тщательное тестирование, чтобы убедиться, что моделью запоминаются только общие фразы, написанные многими пользователями.
Предстоящая работа
Исследователи постоянно работают над улучшением качества предсказания моделей генерации текста, изучая передовые архитектуры (например Transformer, RNMT+ и т.д.), и экспериментируют с продвинутыми способами обучения. Когда их ограничения по задержке будут устранены, они развернут эти более продвинутые модели в своих продуктах. Они также работают над включением персонализированной языковой модели, сконструированной для более точного понимания пользовательского стиля написания.
Виктор Новосад






