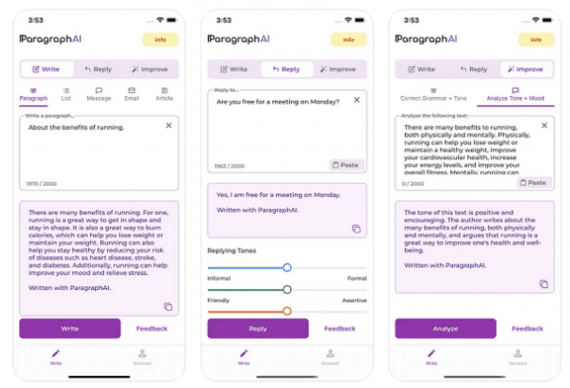
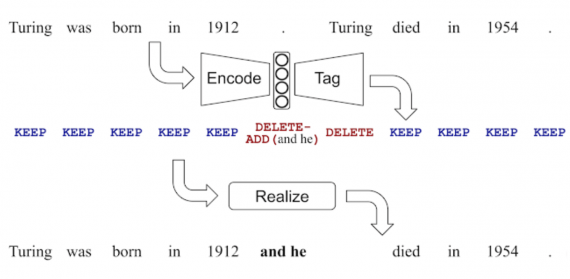
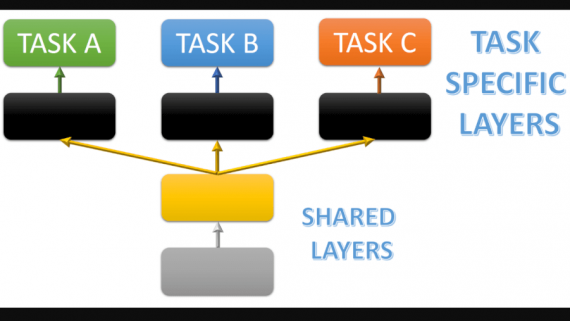
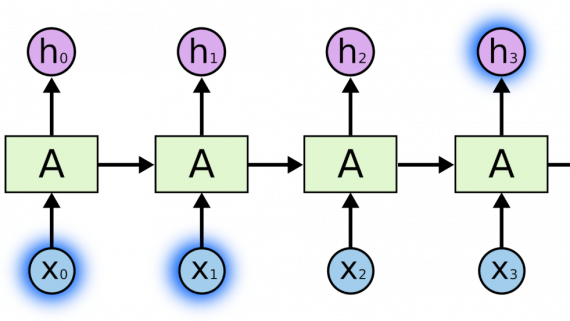
Нейросети для написания текста на русском языке: топ 5 сервисов в 2024 году
14 августа 2023

Нейросети для написания текста на русском языке: топ 5 сервисов в 2024 году
Из этой статьи вы узнаете о самых полезных сервисах для генерации текста с помощью нейросетей, большинство из которых совершенно бесплатны. Нейросети для написания текста стали популярны благодаря развитию глубокого обучения…