Google AI представила библиотеку TensorNetwork для эффективных вычислений в квантовых системах
6 июня 2019
Google AI представила библиотеку TensorNetwork для эффективных вычислений в квантовых системах
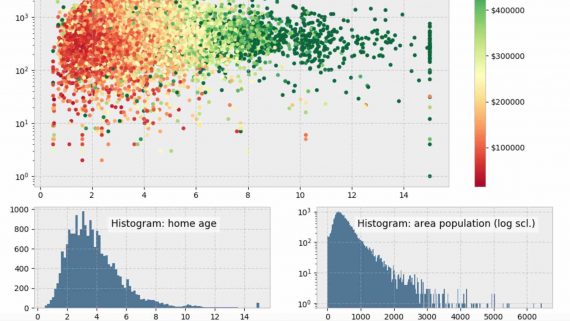
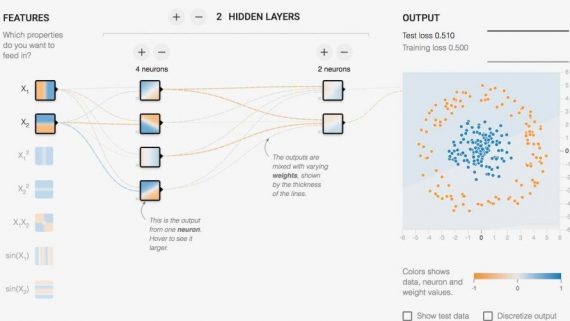
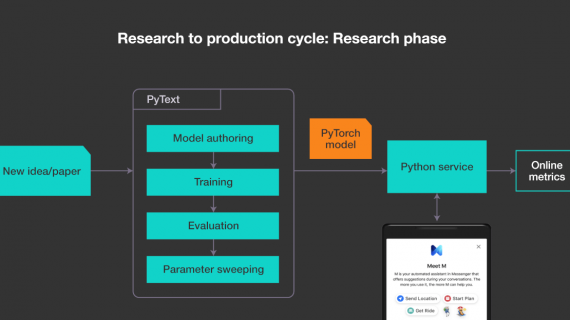
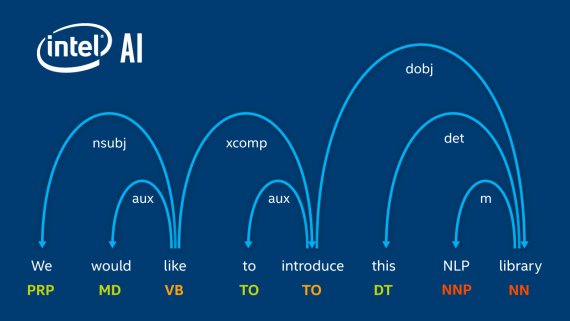
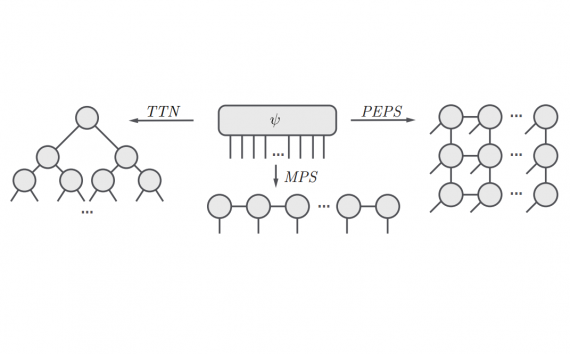
С помощью новой библиотеки TensorNetworks от GoogleAI стало общедоступным использование тензорных сетей, которые играют большую роль в современной квантовой физике. Однако, помимо применения в квантовых системах, тензорные сети все чаще…