Репозиторий с общим кодом — одна из фундаментальных идей в разработке программного обеспечения. Библиотеки делают программистов гораздо более эффективными. В некотором смысле они даже меняют сам процесс решения проблем программирования.
Как выглядит идеальная библиотека с точки зрения разработчика алгоритмов машинного обучения?
Мы хотим делиться предобученными моделями. Опубликованная с открытым кодом обученная модель позволит программисту, не имеющему доступа к вычислительным ресурсам или закрытому датасету, настроить ее и использовать в своей задаче. Например, обучение NASNet занимает тысячи GPU-часов. “Поделившись” подготовленными весами, разработчик упростит коллегам настройку модели для работы.
Идея подобной библиотеки для машинного обучения вдохновила нас на создание TensorFlow Hub, и сегодня мы рады поделиться ею с сообществом. TensorFlow Hub — это платформа, где можно публиковать, изучать и использовать модули машинного обучения, написанные в TensorFlow. Под модулем мы подразумеваем самодостаточную и обособленную часть графа TensorFlow (с обученными весами), которая может быть использована в других задачах. С помощью модуля разработчик cможет обучить модель на меньшем датасете, улучшить способность обобщать или просто увеличить скорость обучения.
Image Retraining
В качестве первого примера рассмотрим технику обучения классификатора изображений на небольшом датасете. Современные модели распознавания содержат миллионы параметров и весов, вычисление и разметка данных требует времени. Технология Image Retraining позволит обучить модель в условиях ограниченного набора данных и времени для вычислений. Вот как это выглядит в TensorFlow Hub:
Основная идея в том, чтобы использовать существующую модель распознавания изображений для получения признаков, а затем обучить новый классификатор. Отдельные модули TensorFlow Hub доступны по URL (или в файловой системе), включая модификации NASNet, MobileNet (v. 2), Inception, ResNet и другие. Для использования модуля, нужно импортировать TensorFlow Hub, а затем скопировать и вставить URL модуля в код.
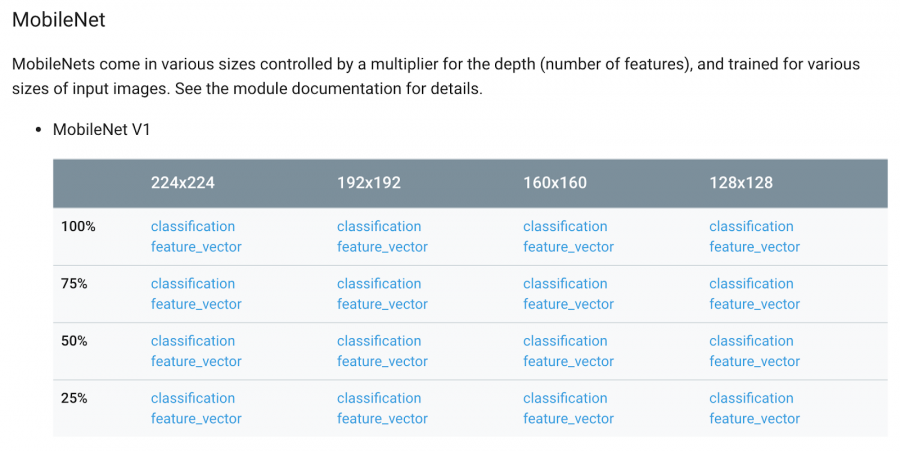
Каждый модуль соответствует определенному интерфейсу, их можно менять и без знаний о внутреннем устройстве. В примере есть метод, позволяющий извлекать ожидаемый размер изображения. Разработчику остается предоставить набор изображений правильного размера, и подать его на вход модулю получения признаков, который самостоятельно осуществит препроцессинг изображений. Это позволит перейти от изображений к признакам практически за один шаг. Уже после этого можно обучать линейную модель или другой подобный классификатор.
Обратите внимание, что модуль в примере размещен компанией Google и представлен в нескольких версиях (выбирайте стабильную версию для экспериментов). Модули можно применять как обычные функции Python для построения графа. Будучи экспортированным на диск, модуль становится самодостаточным, и его можно использовать без доступа к коду и данным, с помощью которых он был создан и обучен (хотя, разумеется, их тоже можно опубликовать).
Классификатор текста
Давайте взглянем на второй пример. Представьте, что Вы хотите обучить модель для классификации отзывов о фильмах на положительные и отрицательные, но в распоряжении имеется небольшой набор данных (например, 400 отзывов). Поскольку примеров немного, есть смысл задействовать эмбеддинг слов, предварительно обученный на гораздо большем массиве слов. Вот как это выглядит с использованием TensorFlow Hub:
Как и раньше, начинаем с выбора модуля. На TensorFlow Hub вы найдете модули для обработки текста для различных языков (английский, японский, немецкий, испанский), word2vec, обученный на Википедии, а также NNLM эмбеддинг, обученный на Google Новостях:

Мы будем использовать модуль для эмбеддинга слов. Код выше загружает модуль, использует его для предобработки предложения, затем вызывает эмбеддинг от каждого токена. Это означает, что за один шаг Вы можете сразу перейти от предложения из Вашего датасета к подходящему для классификатора формату. Модуль сам заботится о разбиении предложения на токены, а также о таких аспектах, как обработка слов, не входящих в словарь. И препроцессинг, и эмбеддинг уже реализованы в модуле, что упрощает экспериментирование с различными датасетами эмбеддинга слов или различными стадиями предобработки, без необходимости постоянно править код.

Если хотите сделать все самостоятельно, а также узнать, как TensorFlow Hub взаимодействует с TensorFlow Estimators, читайте руководство для начинающих.
Универсальный энкодер предложений
Представляем пример использования универсального энкодера предложений. Это эмбеддинг на уровне предложений (sentence-level), обученный на обширном наборе датасетов (отсюда “универсальность”). Среди задач, с которыми он справляется хорошо — семантическое сходство, классификация текста, кластеризация.

Так же, как и в image retraining, здесь не требуется большого набора размеченных данных для решения задачи. Рассмотрим работу энкодера на примере отзывов о ресторанах:
Чтобы узнать больше, посмотрите этот туториал.
Другие модули
TensorFlow Hub — это больше, чем просто классификация текстов и картинок. На сайте вы найдете несколько модулей для Progressive GAN и Google Landmarks Deep Local Features.
Важные замечания
Во-первых, не забывайте, что модули содержат исполняемый код, поэтому загружайте и используйте их только из доверенных источников.
Во-вторых, нужно быть объективным, оба примера, которые мы показали выше, используют предварительно подготовленные большие наборы данных. При повторном использовании набора данных важно помнить о том, какие ограничения он содержит, и как это может повлиять на продукт.
Надеемся, что TensorFlow Hub пригодится в вашем проекте! Посетите tensorflow.org/hub, чтобы начать использовать библиотеку.
Оригинал — TensorFlow, перевод — Эдуард Поконечный.