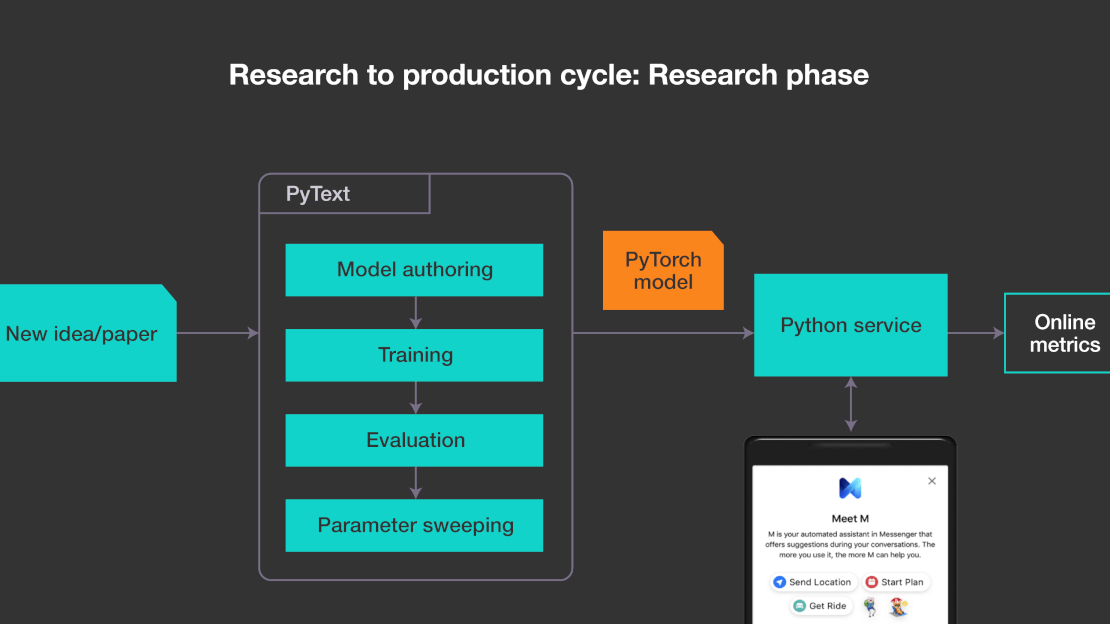
Команда FAIR открыла исходный код PyText — библиотеки для создания моделей обработки естественного языка. Социальная сеть ежедневно применяет модели, разработанные с помощью фреймворка, для работы с миллиардами прогнозов.
PyText позволил повысить точность диалоговых моделей на 10%. «Мы планируем использовать PyText в качестве нашей основной платформы NLP», — отмечают разработчики в блоге FAIR. На PyText уже основана технология распознавания голосовых команд и работа «умного» ассистента в Messenger.
Возможности PyText
Платформа построена на PyTorch 1.0 и позволяет работать с ONNX для конвертирования моделей и движком Caffe2 для экспорта.
Фреймворк можно использовать для классификации документов, разметки речевой последовательности, семантического анализа, моделирования и других задач. Среди преимуществ PyText:
- доступ к готовому набору архитектур и моделей обработки языка, которые используют контекст для более точного определения сути высказываний и правильного перевода;
- возможность использования готовых NLP-моделей и инструментов PyTorch;
- возможность работы с несколькими моделями одновременно;
- ускорение работы: при распределенном обучении на нескольких серверах и кластерах GPU, PyText сокращает время обучения моделей в 3-5 раз.
В ближайшие планы разработчиков входит работа по упрощению отладки моделей и дополнительная оптимизация для распределенного обучения.
Код PyText доступен на GitHub. Подробная статья с описанием особенностей работы библиотеки опубликована здесь.