There’s been a lot of hype around OpenAI’s powerful GPT-3 model, which proved to be able to spin novel super-realistic human-like articles but also tackle many different NLP tasks using zero-shot learning. One thing was standing out when OpenAI released the GPT-3 model – its size. The model has 175 billion parameters and it takes a lot of time and requires huge amounts of data to be trained.
Six months later, and we have yet another enormous language model – Google announced it’s so-called Switch Transformer model, featuring one trillion parameters. In a novel paper published last week, researchers from Google describe a method that allows to scale transformer models.
The key idea in their approach is based on the Mixture of Experts (MoE) routing that allows to learn several sparser models instead of a huge dense model. This approach did not receive much attention in the past, and the researchers behind Switch Transformer managed to simplify it and apply the technique to language models.
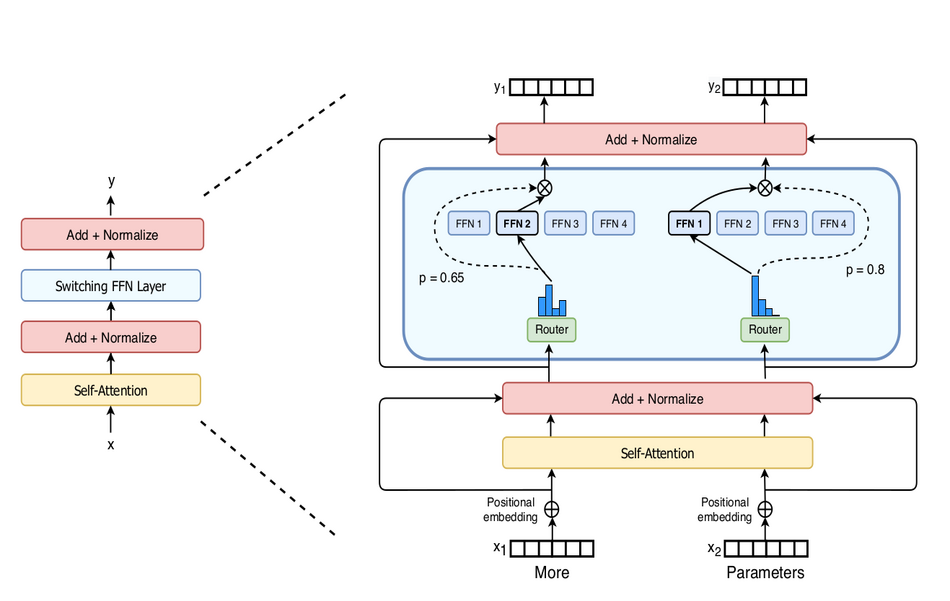
In the architecture of the typical Transformer model, there is a dense feed forward network layer, after the self-attention layer. Researchers propose to replace this dense layer with a novel layer called Switch FFN layer. Such layer operates independently on each of the input tokens provided. It uses routers (as in MoE) that decide which (eventually smaller) feed forward network expert should the token be routed to. During training, the network is trained in parallel with the routers, that learn a distribution for routing the tokens. A simple illustration is given in the image below.
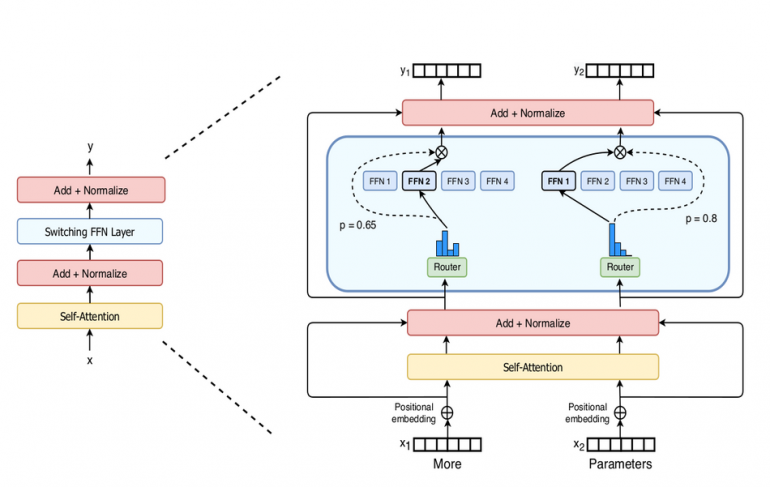
Experiments that researchers conducted showed that the model is more sample efficient and faster than the dense Transformers while using the same computational resources. They also showed that the per-training speed in Switch Transformers has improved up to 7 times.
More details about the method can be found in the paper published on arxiv.


