
A group of researchers from the University of Alberta has proposed new neural network architecture for salient object detection called U² Net.
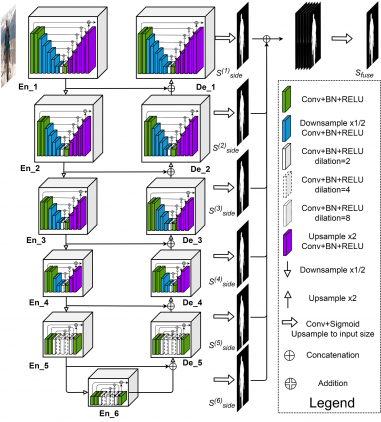
In their recent paper, researchers argue that most of the current methods for image segmentation and salient object detection rely on deep features extracted from existing backbones from image classification, such as AlexNet, ResNet, VGG, DenseNet etc., and this, in turn, introduces a problem when dealing with tasks such as salient object detection, where local details are of higher importance than semantic meaning. To overcome this problem, they propose a novel architecture which they call U² Net because of its nested U-structure. In this architecture each stage of the encoder-decoder U-Net structure contains the newly proposed RSU block, which is, in fact, a downsampling upsampling encoder-decoder itself. The structure of the RSU block is shown in the diagram below. The idea behind this new block is to use multi-scale features as residuals instead of the original features. According to researchers, this will introduce the desired effect of keeping the fine-grained details and will force the network to extract features from multiple-scales at every residual block.
The proposed model was trained using DUTS-TR dataset that contains around 10 000 sample images, augmented using standard data augmentation techniques. Researchers evaluated the model on six benchmark datasets for salient object detection: DUT-OMRON, DUTS-TE, HKU-IS, ECSSD, PASCAL-S, and SOD. Results from the evaluations showed that the new model performs comparably well with existing methods on these 6 benchmarks.
The implementation of U² Net was open-sourced along with pre-trained models for two variants of the method: U² Net (a larger model of 176.3 MB, 30 FPS on GTX 1080Ti GPU) and a smaller U² Net version of just 4.7 Mb that achieves up to 40 Fps. The code and the models can be found here. The paper was published on arxiv.


