
Group of researchers from the Technical University of Munich has proposed a new state-of-the-art method for real-time action localization – YOWO (You Only Watch Once).
Arguing that previous approaches decouple the problem and extract spatial and temporal information with separate networks, they propose a novel unified method.
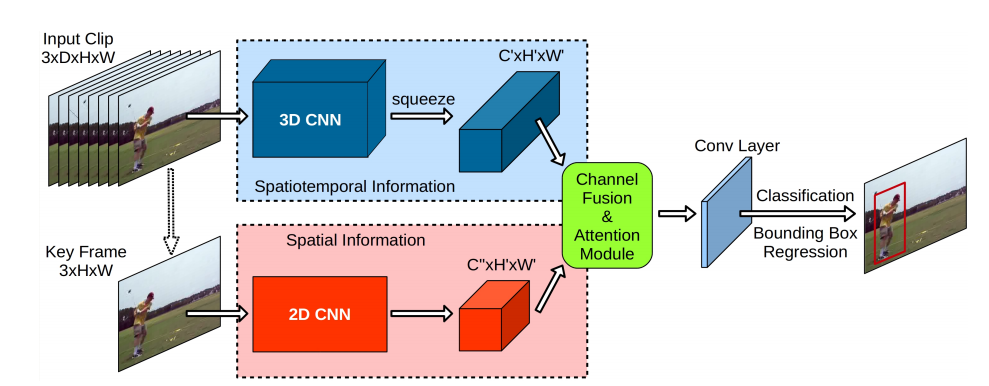
The new method combines spatial and temporal information extraction into a single unified CNN architecture in order to perform real-time action detection and localization. YOWO has a two-branch architecture where the first branch takes an input video (or sequence of frames) and performs spatio-temporal information extraction. The second branch takes the key frame and extracts only spatial information which is fused with a channel fusion and attention module. In the end, a convolutional layer takes care of the classification and the bounding box prediction. The model is optimized in an end-to-end manner jointly training both “sub-networks” to perform the given task.
According to researchers, the YOWO method is fast and it provides 34-frames per second inference on 16-frame long video clips and 62 frames per second on 8-frame clips making the method deployable even on mobile devices. The evaluations showed that YOWO is superior to existing methods and outperforms all previous state-of-the-art results on J-HMDB and UCF101-24.

The full evaluation and more details about the new method can be read in the official paper. The implementation will be open-sourced and available on Github.


