Vision Transformers without layers of attention performed strongly on ImageNet. This shows that the attention mechanism is not the key to the effectiveness of the Vision Transformer architecture, contrary to the common version.
Why is it needed
The usefulness of modern AI architectures is primarily proven in practice, and its theoretical justification helps to improve existing models and develop new ones. Therefore, it is very important to understand the key reasons for the effectiveness of each architecture.
At the moment, Vision Transformer (ViT) architecture is state-of-the-art in computer vision. The high ViT scores in computer vision are often attributed to the design of multi-head attention layers. Recently, a significant amount of work has been directed towards improving their effectiveness. However, it is still unclear how important the contribution of attention layers is. This is what a researcher at Oxford University decided to find out.
How it works
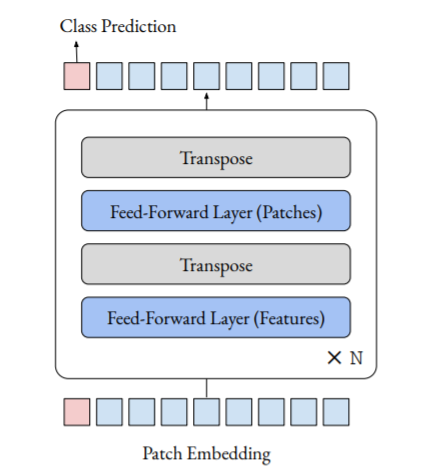
The classical ViT architecture divides the image into a sequence of patches and then applies a series of Transformer blocks to this sequence. Each Transformer block consists of two layers:
- multi-head attention layer;
- feed-forward layer applied along feature dimension (the simplest single-connected layer).
The researcher removed the attention layers from ViT, replacing them with feed-forward layers along patch dimension. The result is a sequence of the simplest layers, separated by the operation of transposition.
Results
The author tested several modern variations of the ViT architecture on the popular ImageNet dataset for image classification, replacing the attention layers. The models performed worse without attention, but the DeiT-based variation managed to achieve amazingly high accuracy (74.9% top-1 accuracy). For comparison, the accuracy of classic ViT and DeiT is 77.9% and 79.9%, respectively. The results show that the high performance of ViT has more to do with patching and training procedures than with attention layer construction. Such papers help the industry to develop by adjusting the focus of the research community.
You can read more about the research in the arXiv article.
The pre-trained code is also available in the Github repository.


