One of the widely used Natural Language Processing & Supervised Machine Learning (ML) task in different problems and used cases is the so-called Text Classification. It is an example of Supervised Machine Learning task since a labeled dataset containing text documents and their labels is used for training a text classifier.
Previous Works on Text Classification
Historically, the problem of text classification was addressed by feature engineering and training simple classifiers such as linear regression models or Support Vector Machines (SVMs). As a classification task, text classification can be the multi-class – unique category for each text sample out of multiple classes and multi-label – multiple categories.
In recent years, deep neural networks have shown remarkable success also in the task of text classification. From a Natural Language Processing (NLP) perspective, text classification was tackled by learning a word-level representation using word embeddings and later learning a text-level representation used as the feature for classification. Although successful, this kind of encoding-based methods ignores fine-grained details and clues for classification (because a general text-level representation is learned by compressing the word-level representations).
State-of-the-art Idea
Researchers from Shandong University and the National University of Singapore, have proposed a new model for text classification that incorporates word-level matching signals into the text classification task. Their method uses an interaction mechanism to inject fine-grained, word-level matching clues into the classification process.
EXAM
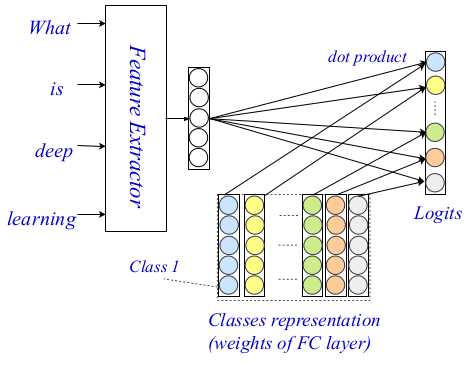
To address the problem of incorporating finer word-level matching signals, the researchers propose to calculate the matching scores between the words and classes explicitly. The key idea is to compute an interaction matrix out of word-level representation which will carry the matching clues on a word-level. Each entry of this matrix is the matching score between a word and a particular class.
The proposed framework for text classification called EXAM – EXplicit interAction Model, contains three major components: a word-level encoder, interaction layer, and the aggregation layer. This three-level architecture allows to encode and classify text using both fine- and coarse-grained signals and clues. The whole architecture is given in the image below.
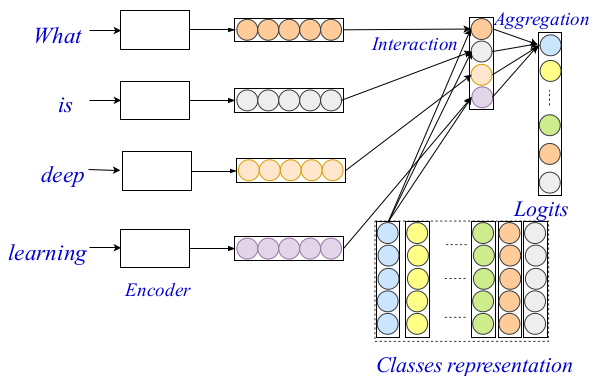
In the past, word-level encoders have been explored extensively within the NLP community, and there exist very powerful word-level encoders. The authors use an existing method as a word-level encoder, and in their paper, they elaborate on the other two components of their architecture: the interaction and aggregation layer.
The interaction layer the main contribution and novelty in the proposed method are based on the well-known interaction mechanism. In this part, the researchers’ first project classes into real-valued latent representations. They use a trainable representation matrix to encode each of the classes for later to be able to compute word-to-class interaction scores. The final scores are estimated simply using dot product as the interaction function between the target word and each class. More complex functions have not been considered due to an increase in computational complexity.
Finally, as an aggregation layer, they employ a simple fully-connected two-layer MLP. They also mention that here it is possible to use more complex aggregation layer incorporating CNN or LSTM. The MLP is used to compute the final classification logits taking the interaction matrix and the word-level encodings. Cross-entropy is used as a loss function for the optimization.
Evaluation and Comparison
To evaluate the proposed framework for text classification, the researchers did extensive experiments both in multi-class and multi-label settings. They show that their method outperforms current corresponding state-of-the-art methods remarkably.
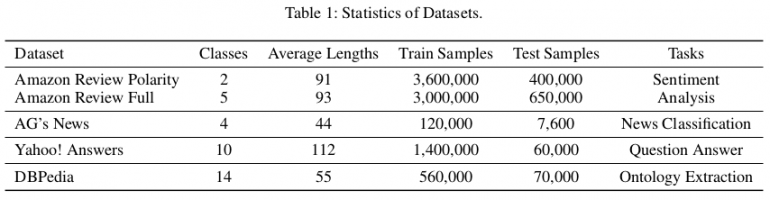
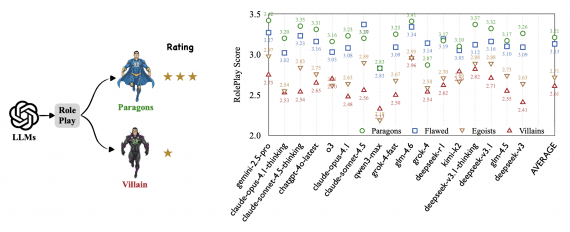
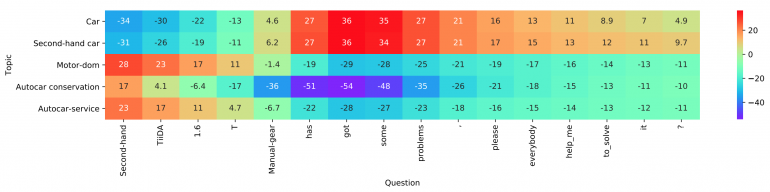
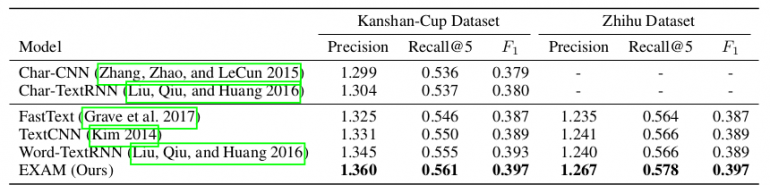
For the evaluation, they set three different baseline model types: 1) models based on feature engineering; 2) Char-based deep models, and 3) Word-based deep models. They used publicly available benchmark datasets from (Zhang, Zhao, and LeCun 2015) to evaluate the proposed method. There are in total six text classification datasets, corresponding to sentiment analysis, news classification, question-answer, and ontology extraction tasks, respectively. In the paper, they show that EXAM achieves the best performance over the three datasets: AG, Yah. A., and DBP. The evaluation and comparison to other methods can be seen in the tables below.
![Test Set Accuracy [%] on multi-class document classification tasks and comparison with other methods](https://neurohive.io/wp-content/uploads/2018/12/text-classification-methods-comparison-770x315.png)
Conclusion
To conclude, this work represents an important contribution in the field of Natural Language Processing (NLP). It is the first work that introduces finer, word-level matching clues in text classification with deep neural network models. The proposed model achieves state-of-the-art performance on several datasets.