Researchers at Tsinghua University have developed the LCM-LoRA algorithm, revolutionizing real-time image generation from text descriptions or sketches. Consequently, this technology marks a significant advancement in the field.
Popular text-to-image models like Stable Diffusion, Midjourney, and DALLE-3 typically take several seconds to two minutes to generate an image. LCM-LoRA (Latent Consistency Model – Low-Rank Adaptation), an enhancement over Stable Diffusion, significantly reduces the generation time to about 100 milliseconds. Therefore, this development represents a breakthrough in efficiency and speed.
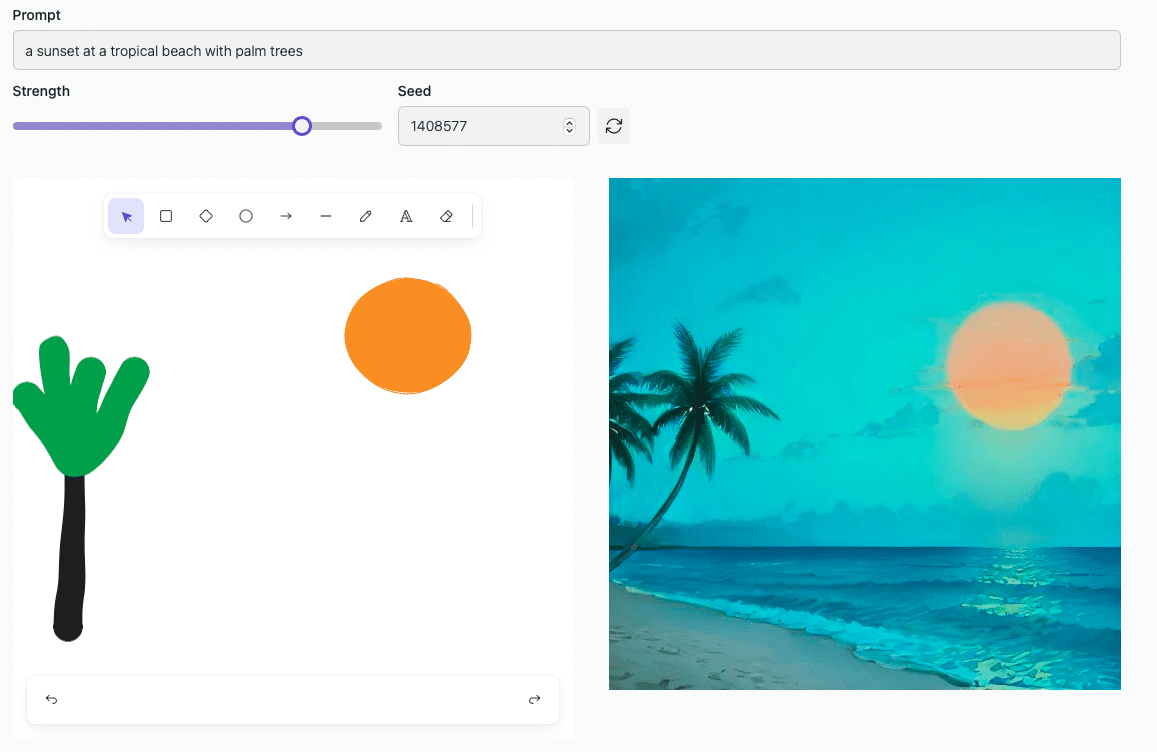
LCM-LoRA accelerates image generation by reducing the number of necessary sampling steps — the processes of converting the original text or image into a more detailed and high-quality image. For instance, images generated by the algorithm in just 4 steps: 
LCM-LoRA can process just a text query, or a combination of a text query and a sketch of primitive shapes (like rectangles, lines, and ovals), or an image that needs modification. Thus, it offers flexibility in input types.
This method is applicable not only for generating two-dimensional but also three-dimensional scenes, significantly accelerating the development of video games, movie special effects, and augmented and mixed reality environments. Moreover, reducing the number of sampling steps implies lower computational resource requirements.
Potentially, LCM-LoRA can be integrated with any text-to-image model, but currently, the authors have tested it only on Stable Diffusion. You can test the algorithm here. The LCM-LoRA code is available publicly on GitHub.








hello my name is sirine drmi i love the time photo