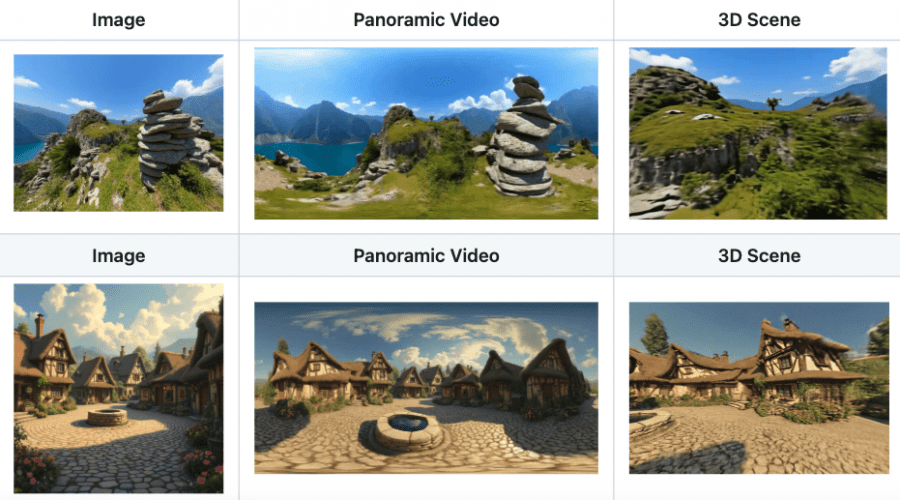
Researchers from Skywork AI and the Hong Kong University of Science and Technology have introduced Matrix-3D — a framework for creating fully explorable 3D worlds from a single image or text description. Martix-3D addresses the limited field of view of existing 3D scene generation methods, enabling 360-degree views without boundary artifacts. The model code is available on Github.
Matrix-3D supports a ready-made pipeline for generating a 3D world in multiple steps or with a single command. Users can download checkpoints and run automatic generation, or follow a step-by-step process: first convert text or an image into a panoramic photo, then create a panoramic video at 960 × 480 or 1440 × 720 resolution, and finally reconstruct the 3D scene using one of two methods — optimization for maximum quality or feed-forward for faster processing. Generated scenes are saved in .ply format along with renderings.
Framework Architecture
The framework is built on the video diffusion model Wan2.1-I2V-14B. Training was conducted on 200K video clips of 81 frames each, with a learning rate of 1×10^-4 and batch size 21. Models were trained at resolutions 480×960 and 720×1440.

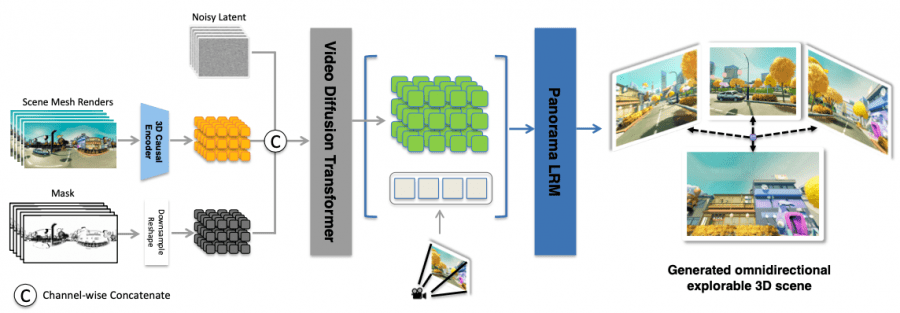
Matrix-3D uses panoramic images as an intermediate scene representation, capturing a full 360° × 180° view. The framework consists of three components: generating panoramic video with controlled trajectories, reconstructing scenes through mesh rendering, and converting to a 3D world via two alternative approaches.
The main difference from previous works is the use of mesh renders instead of point clouds. Experiments showed that point cloud renders produce moiré patterns and incorrectly handle occlusions between objects. Mesh representation eliminates these geometric artifacts, confirmed by quantitative metrics: PSNR increased from 23.4 to 23.8, FVD decreased from 260 to 242.
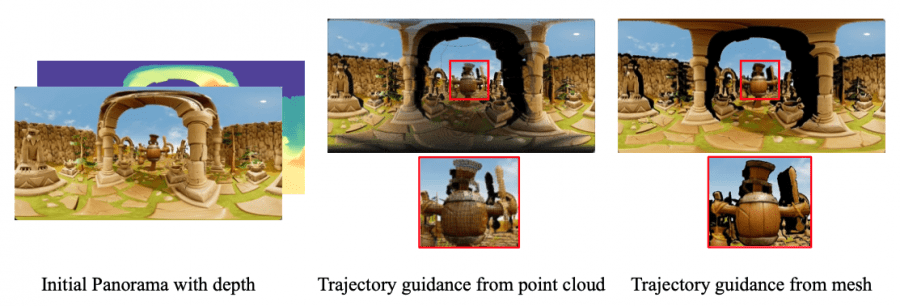
3D Reconstruction Methods
Matrix-3D offers two approaches for converting panoramic video into a 3D world.
Optimization method selects key frames every 5 frames from the generated video. Each panoramic frame is split into 12 perspective images, which go through super-resolution (StableSR) before entering the 3D Gaussian Splatting pipeline. Depth is estimated via MoGe and then aligned using least squares.
Feed-forward model (Large Panorama Reconstruction Model) works directly with latent video representations of size t×h×w×c. The architecture includes:
- Patchify modules to convert frames into tokens;
- 4 transformer blocks to capture global context;
- DPT head for predicting Gaussian attributes;
- 3D deconvolution to increase temporal resolution.
The model is trained in two stages: first, depth prediction with harmonic loss, then other Gaussian attributes with a combination of MSE and LPIPS losses.
Matrix-Pano Dataset
The team created Matrix-Pano — a synthetic dataset of 116,759 panoramic video sequences at 1024×2048 resolution. Each sequence contains 81 frames, camera motion trajectories, depth maps, and text descriptions. The dataset was generated in Unreal Engine 5 from 504 3D scenes.
Data generation included:
- Automatic trajectory generation via Dijkstra’s algorithm with Laplacian smoothing;
- Filtering paths shorter than 18 meters for sufficient temporal dynamics;
- Collision detection using a bounding box algorithm;
- Two-stage quality control: automated via Video-LLaMA3 and manual validation of the first frames.
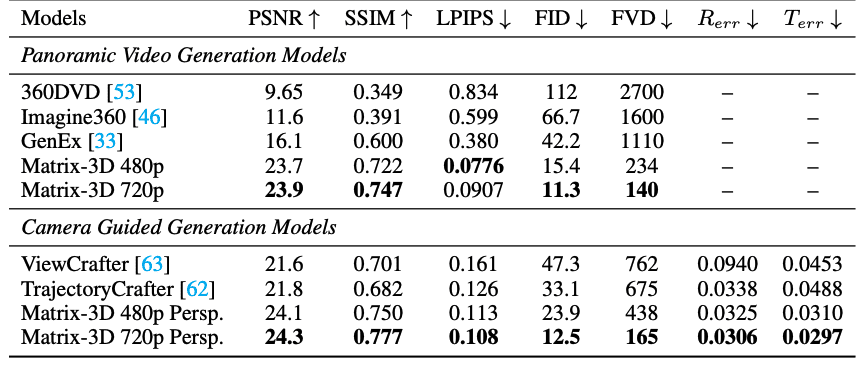
Matrix-3D Results and Benchmark Comparisons
Quantitative results:
Qualitative comparison of 3D reconstruction: ODGS (left), Matrix-3D feed-forward (center), Matrix-3D optimization (right), and ground truth. The optimization method achieves the best visual quality:

Limitations
Generation requires 40 GB of VRAM for 480p and 60 GB for 720p. A lightweight version is planned, allowing 720p content creation with 24 GB VRAM, compatible with GPUs like NVIDIA RTX 4090.
Current limitations:
- Scene generation takes tens of minutes;
- Unnatural depth transitions in semi-transparent areas (trees, fences);
- Latent video representation lacks explicit geometric cues, complicating depth prediction.
Matrix-3D represents a major advance in fully explorable 3D world generation, combining panoramic representation, mesh rendering, and flexible reconstruction pipelines for high-quality outputs.






