
A team of researchers from StepFun, Southern University of Science and Technology, and the Chinese Academy of Sciences has published RealRestorer — an open-source image quality enhancement model that removes blur, noise, rain, lens flare, haze, compression artifacts, moiré patterns, and reflections. On the FoundIR benchmark with real paired images, RealRestorer outperformed the closed-source Nano Banana Pro on the PSNR metric — 21.45 dB vs 20.37 dB. PSNR (Peak Signal-to-Noise Ratio) measures how closely a restored image matches a clean reference. In practice, a difference of 1 dB is visible to the naked eye — roughly the difference between a decent and an excellent JPEG compression. On the RealIR-Bench benchmark, the model ranks first among open-source solutions and trails Nano Banana Pro by just 0.007 points.
The project is partially open: the code is available under the Apache 2.0 license, but model weights and the RealIR-Bench dataset are restricted to non-commercial academic research. Weights, benchmark, and code are published on GitHub and Hugging Face.
What’s wrong with existing approaches
Most previous restoration models were trained on synthetic pairs of degraded and clean images. Synthetic data is easy to generate — take a clean photo, apply an algorithm to degrade it, and the pair is ready. But real-world noise from a phone camera or real motion blur looks different from what an algorithm produces. The model trains on one data distribution and gets tested on another, which leads to poor results.
Closed-source models like GPT-Image-1.5 and Nano Banana Pro worked around this by training on massive datasets of real degraded images. But their weights and data are proprietary — they can’t be reproduced, and researchers can’t use them as a foundation for their own work. RealRestorer addresses this: the authors built a large-scale open dataset and fine-tuned an open-source base model on it.
Where the training data came from
This is the most technically interesting part. The authors assembled a dataset of 1.65 million image pairs covering nine degradation types, using two fundamentally different approaches.
RealRestorer also relies heavily on synthetic data — 1.57 million synthetic pairs vs 87,000 real ones, meaning roughly 95% of the dataset is synthetic.
The difference isn’t whether synthetic data is used at all, but how well it’s made. The authors put considerable effort into making synthetic degradations closer to real ones: segment-aware noise instead of uniform noise, temporal averaging over video frames for blur instead of simple Gaussian filters, blending real haze and moiré patterns with synthetic ones. The second training stage then adds real pairs that “calibrate” the model toward real-world distribution.
Previous models trained exclusively on synthetic data with simplified degradation models, while RealRestorer uses more realistic synthetic data and augments it with real pairs in the second stage. It’s a fundamentally different recipe, but synthetic data remains a key ingredient in both cases.
Two approaches to data collection
The first approach is synthetic degradation generation (Synthetic Degradation Data). A clean image is taken and a degradation algorithm is applied to it. For blur, temporal averaging over video frames was used to simulate realistic motion trajectories. For noise, the authors introduced segment-aware noise — noise is applied differently to different semantic regions of the image, producing more realistic results. For haze, synthesis was based on the classic atmospheric scattering model with depth estimation via MiDaS. This approach is scalable — clean images are abundant online — but it still can’t fully replicate the complexity of real-world degradations.
The second approach uses real degraded images (Real-World Degradation Data). The authors collected genuinely degraded photos from the web and used powerful generative models to produce clean references for them. To filter out low-quality examples, they used CLIP for degradation-based semantic filtering and Qwen3-VL-8B-Instruct to assess degradation severity. These pairs are closer to real-world distribution but harder to collect.
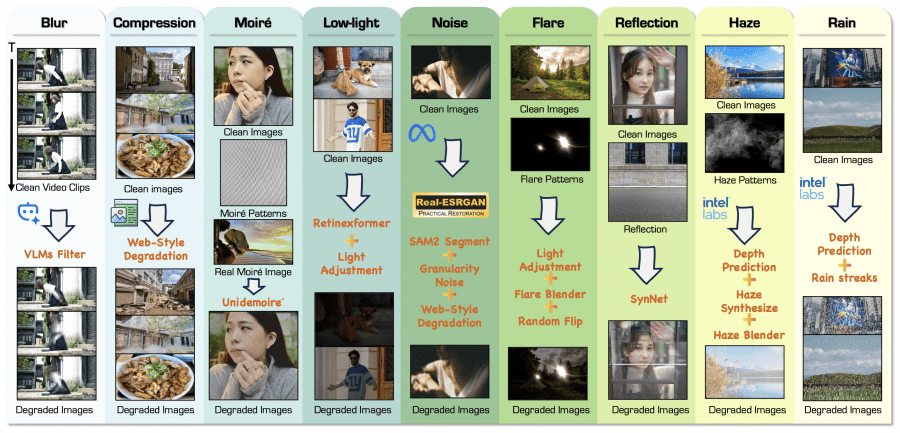
The final dataset breaks down as follows: 1.57 million synthetic pairs and 87,000 real ones. For some degradation types there are no real samples at all — moiré and compression artifacts are represented by synthetic data only.
How the model works
RealRestorer is not a from-scratch architecture — it’s a fine-tuned version of the open-source Step1X-Edit model, built on a DiT (Diffusion Transformer) backbone. Internally it uses a dual-stream design: semantic information is processed simultaneously through the QwenVL text encoder alongside the noisy signal and the conditional input image. The Flux-VAE handles encoding into latent space.
Training proceeded in two stages. In the first stage (Transfer Training), the model was trained exclusively on synthetic data — this transferred knowledge from image editing to image restoration. The learning rate was held constant at 1e⁻⁵ throughout, with a fixed resolution of 1024×1024. In the second stage — supervised fine-tuning — real degraded pairs were added to the synthetic data, and the learning rate decayed via cosine annealing. The gradual cosine decay allows the model to smoothly shift toward the new data distribution without abrupt jumps. The authors also employed a Progressively-Mixed Training strategy: a small proportion of synthetic data was retained in the second stage to prevent overfitting to real-world patterns and preserve generalization ability.
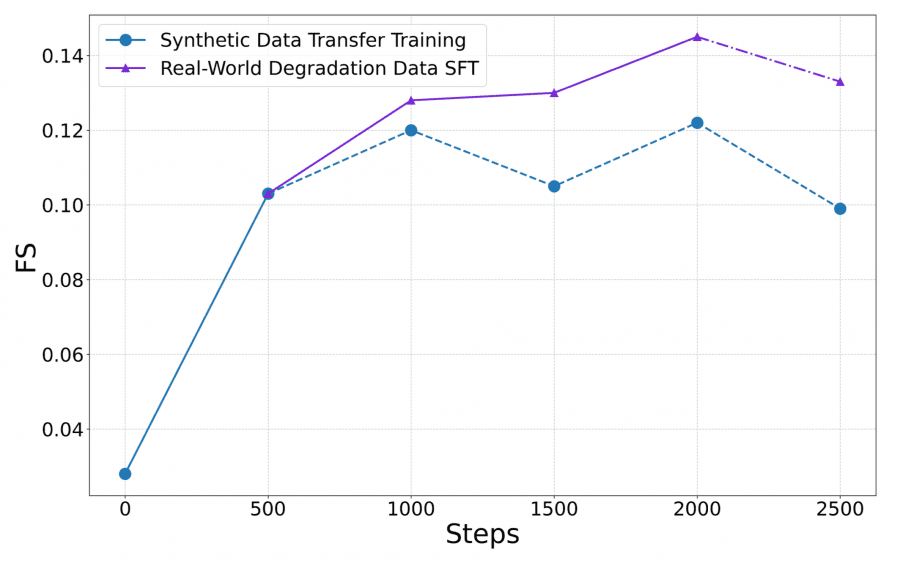
Here’s what happens with quality under different training strategies: a model trained only on synthetic data peaks at a Final Score of 0.122 and then degrades — synthetic data lacks sufficient diversity. A model trained only on real pairs starts removing normal light sources as “flare” and loses structural consistency. The two-stage approach strikes the right balance.
The new RealIR-Bench benchmark and metrics
Standard quality metrics — PSNR and SSIM — require a clean reference image for comparison. But when a benchmark is built from genuinely degraded photos scraped from the web, no such references exist. The authors therefore created RealIR-Bench — 464 real degraded images across nine categories — and designed reference-free evaluation metrics.
Restoration Score (RS) measures how much degradation the model removed. A VLM, Qwen3-VL-8B-Instruct, rates degradation severity before and after restoration on a scale from 0 to 5 — RS is the difference between these scores. LPIPS (Learned Perceptual Image Patch Similarity) measures perceptual similarity between the restored and original degraded image — that is, how well the model preserved scene content. The Final Score combines both: FS = 0.2 × (1 − LPIPS) × RS. If a model removes degradation effectively but destroys image content, the overall score will still be low.
Comparison results
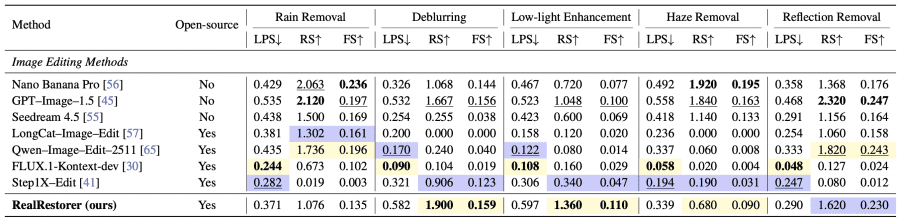
The authors compared RealRestorer against seven models: closed-source Nano Banana Pro, GPT-Image-1.5, and Seedream 4.5, and open-source LongCat-Image-Edit, Qwen-Image-Edit-2511, FLUX.1-Kontext-dev, and Step1X-Edit.
By average Final Score on RealIR-Bench, RealRestorer ranked third overall with 0.146 — behind Nano Banana Pro (0.153) and GPT-Image-1.5 (0.150), but ahead of all open-source models. The closest open-source competitor is Qwen-Image-Edit-2511 at 0.127. On individual tasks, RealRestorer achieved the best results of all tested models — including closed-source commercial ones — on deblurring and low-light enhancement.

Detailed comparison across all nine tasks
Three metrics are reported for each task: LPS (LPIPS, lower is better), RS — Restoration Score (higher is better), and FS — Final Score (higher is better). In the original paper, yellow highlights the best open-source result and blue the second best.
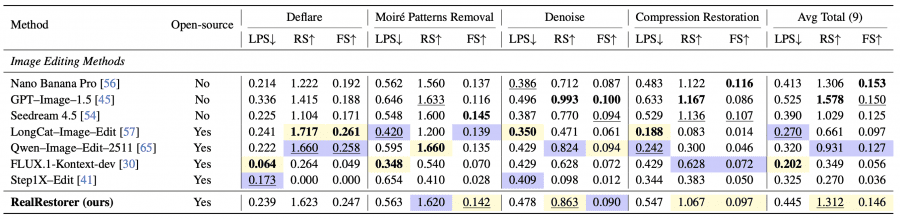
On the FoundIR benchmark, which provides clean reference images, RealRestorer achieved the best results on 5 out of 7 degradations with an average PSNR of 21.45 dB vs 20.37 dB for Nano Banana Pro.

The authors also evaluated zero-shot generalization — the ability to handle degradation types not seen during training. RealRestorer showed promising results on snow removal and old photo restoration, despite having no such data in training.
User study
32 participants rated 3,200 groups of images from the five best-performing models across two criteria: restoration quality and content preservation. Nano Banana Pro received the highest ranking from 32% of participants, GPT-Image-1.5 from 23.8%, and RealRestorer from 21.5%. This aligns with the numerical Final Score results. Statistical analysis showed moderate agreement between the proposed metrics and human judgments (p < 0.01 by Kendall τb, SRCC, and PLCC).
Limitations
The authors identify three issues. Inference cost is higher than that of smaller specialized networks — the base model uses a 28-step denoising process. Under strong semantic and physical ambiguity — such as mirror selfies — the model sometimes fails to distinguish real scene content from reflections. And with extremely severe degradations where most pixel information is lost, the model may fail to reconstruct physically consistent structures such as water reflections.
Running RealRestorer locally is not straightforward: it requires a GPU with at least 34 GB of VRAM — the level of an A100 or H100, out of reach for most consumer GPUs like the RTX 4090 with its 24 GB. No quantized versions are available yet. Installation requires Python 3.12 and a patched version of the Diffusers library from the project repository — a standard pip install won’t work. Inference runs through RealRestorerPipeline with recommended settings: 28 steps, guidance scale 3.0, torch dtype bfloat16. The authors don’t publish the parameter count, but Step1X-Edit — the model it’s based on — is comparable in scale to FLUX.1, meaning several billion parameters. This explains the high memory requirements.
RealRestorer closes the gap between open-source and closed-source image quality enhancement models to a nearly negligible margin, while releasing weights, data, and the full pipeline for non-commercial use. This gives the research community a strong open foundation to build on.








