ANLI (Adversarial Natural Language Inference) — это датасет от FAIR для обучения более робастных NLP-моделей. Задача natural language inference тестирует модель на то, как хорошо модель понимает язык. Цель заключается в том, что бы определить, можно ли выражение вывести из определенного куска текста. Например, предложение “Сократ смертен” можно вывести из предложение “Сократ — это человека, а люди смертны”. Модель, которая способна верно определять такие случаи, обладает высокой обобщающей способностью.
Ограничения прошлых NLI датасетов
Стандартно датасеты для NLI являются статичными: исследователи собирают датасет, на котором затем сравниваются разные архитектуры. Однако такой подход приводит к тому, что модели переобучаются на датасете. Переобученные модели имеют ограниченное применение, потому что не масштабируются на данные, которые отличаются от тех, на которых они обучались и повторно тестировались.
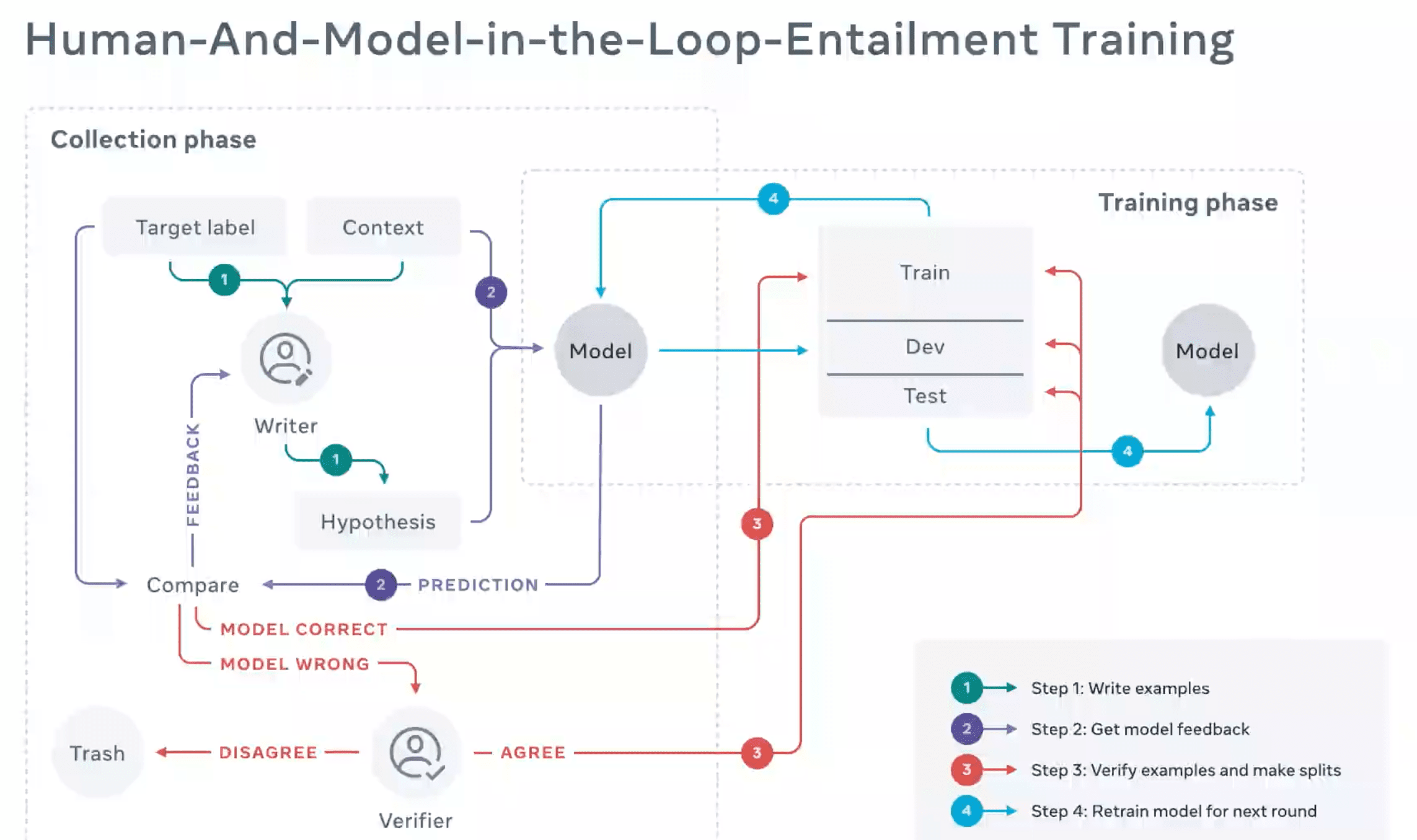
Исследователи из FAIR предлагают динамичный подход к сбору датасета. Аннотаторы специально обманывают state-of-the-art модели на NLI задачах через добавление неверных объектов в данные. Для этого используют подход к сбору данных HAMLET (Human-and-Model-in-the-Loop-Entailment Training). Он позволяет обучать более устойчивые модели. Если модель переобучается или выучивает bias из данных, есть возможность добавить состязательных примеров в данные. Такой адаптивный формат повышает обобщаю способность тестируемых подходов.
