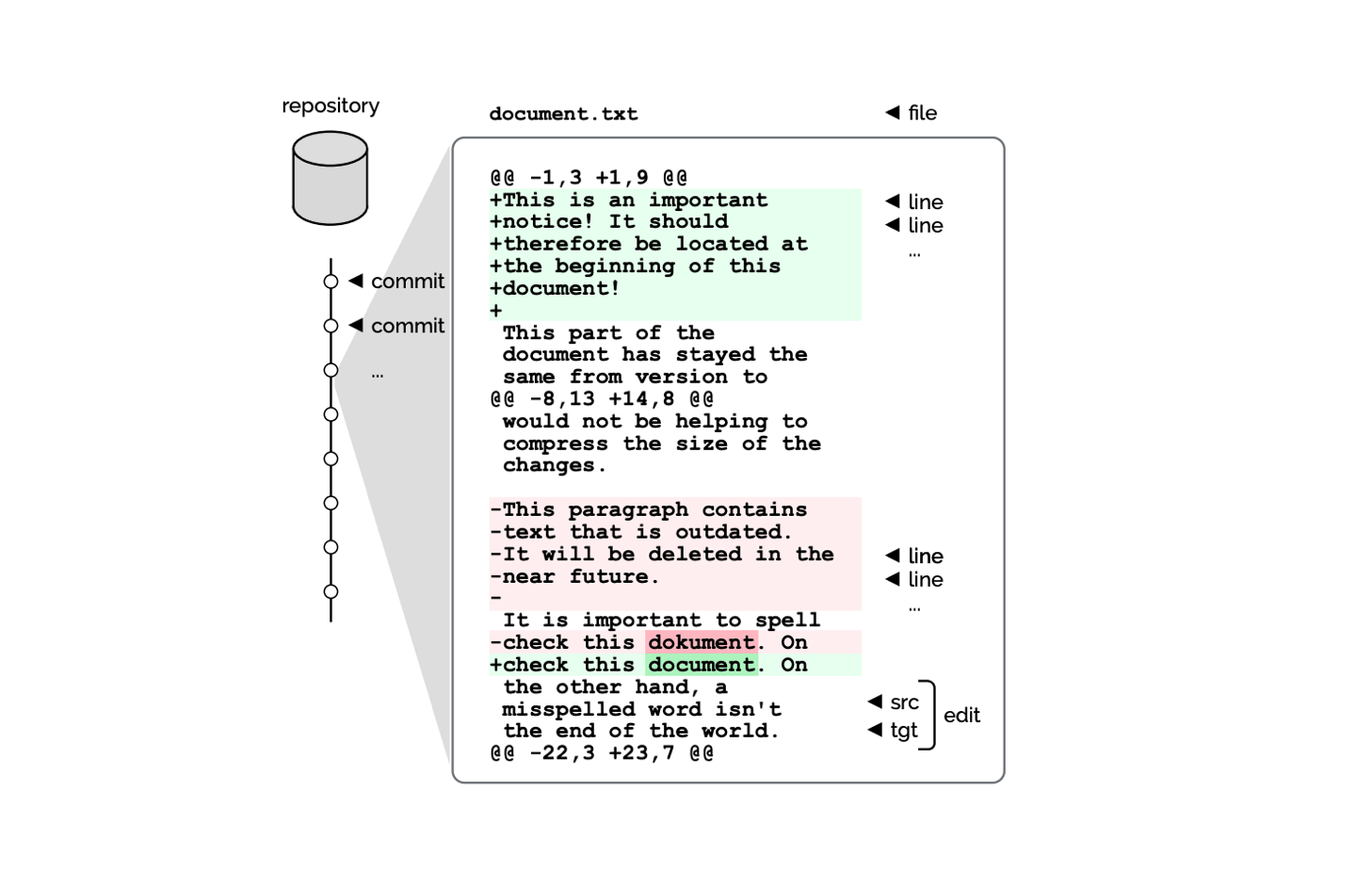
GitHub Typo Corpus — это набор данных с опечатками и грамматическими ошибками на разных языках. Данные ошибок собирали из коммитов GitHub репозиториев. Всего в датасете более 350 тысяч исправлений на 15 языках. Это наиболее крупный датасет с опечатками и грамматическими ошибками на текущий момент.
Отсутствие крупных размеченных датасетов — одна из сложностей при обучении моделей для исправления орфографии и грамматики. Исследователи собрали GitHub Typo Corpus, чтобы облегчить решение задачи исправления ошибок в тексте на естественном языке. В GitHub репозиториях пользователи часто вносят изменения об исправлениях опечаток. У каждого изменения обязательно есть подпись. Зачастую подписи изменений орфографических и грамматических ошибок в репозитории имеют в себе словосочетание “fix typo”.
Изменения опечаток в датасете предсказываются с ~0.9 F1 с помощью простого классификатора и трех признаков. При этом существующие методы для исправления ошибок выдают результаты ~0.6 по F-мере. Кроме того, в многих датасетах для исправления грамматических ошибок процент грамматических ошибок составляет около 10. Такое распределение ограничивает возможность моделей выучить исправление грамматических ошибок. GitHub Typo Corpus может быть дополнением для существующих датасетов благодаря разнообразию данных и точности разметки.
Как собирали датасет
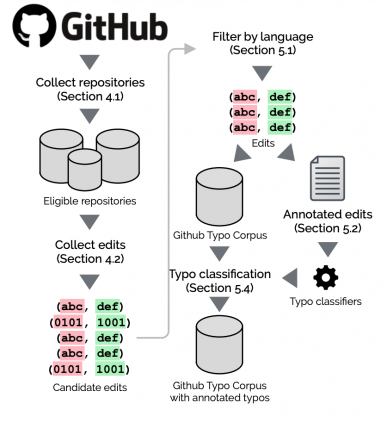
Процесс сбора данных исследователи поделили на три шага:
- Выгрузка и фильтрация репозиториев и коммитов с опечатками по метаданным репозитория и подписи коммита;
- Фильтрация изменений, которые не были написаны на естественном языке;
- Распознавание изменений с опечаткой с помощью классификатора, который обучили на маленьком размеченном датасете
После фильтрации репозиториев их количество составило 43,462. Для отбора изменений на естественном языке и разметки языка исследователи использовали NanigoNet. Архитектура NanigoNet основана на графовых нейросетях.
Что внутри данных
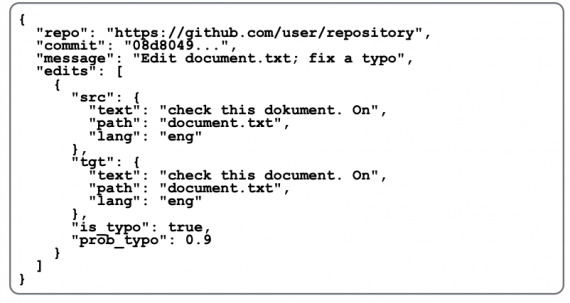
Каждое изменение содержит в себе следующие признаки:
- ссылка на репозиторий;
- хэш коммита;
- подпись коммита;
- список исправлений, которые достали из этого коммита
Каждое исправление в списке содержит следующие признаки:
- текст до исправления;
- текст после исправления (целевая последовательность);
- вероятность, с которой текущее изменение является изменением опечатки
Текст до исправления и текст после исправления также имеют данные о:
- путь к файлу, в котором изменили;
- язык текста;
- перплексия текста