Исследователи из Google AI опубликовали первый датасет для тестирования устойчивости моделей к шумным данным. Кроме датасета, исследователи опубликовали модель классификации для шумных данных. MentorMix обходит state-of-the-art подходы для шумных данных с top-1 точностью классификации в 67.5%.
Синтетический и реальный шум в данных
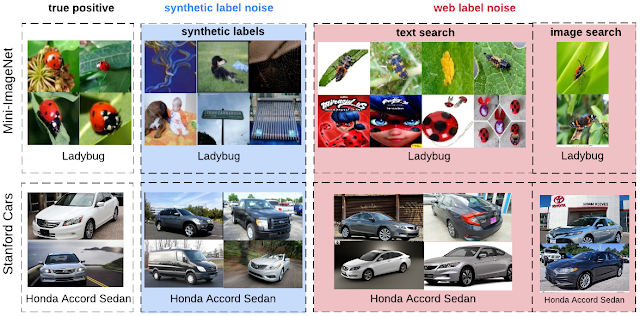
Между синтетическим и реальным распределениями шума в лейблах есть ряд различий:
- Изображения с реальным шумом обычно более визуально и семантически схожи с true positive изображениями;
- Синтетический шум — это шум на уровне классов, где все примеры одного класса одинаково шумные. В то же самое время реальный шум — это шум на уровне инстанса, где определенные изображения зашумлены сильнее остальных;
- Изображения с реальным шумом в разметке классов могут принадлежать к классам, которые схожи с размеченным классом, но которые не включены в датасете
Подробнее про датасет
Датасет для тестирования устойчивости моделей к шумным данным основан на двух открытых датасетах: Mini-ImageNet. Чистые изображения постепенно заменялись на некорректно размеченные изображения, которые собирали из интернета.
Например, в поисковике искали изображения по ключевому словосочетанию “божья коровка”. Так в датасет естественным образом попадали шумные данные. Всего в датасете 213 тысяч размеченных изображений. Датасет состоит из 10 сабсетов, в каждом из которых уровень зашумленности данных повышается: от 0% до 80%.
