HateXplain — это датасет для обучения моделей распознавания оскорблений в тексте. Датасет собирали исследователи из Indian Institute of Technology и University of Hamburg. Датасет разрабатывали так, что бы учитывать метрики интерпретируемости моделей распознавания.
Зачем это нужно
Хейтспич — это комплексная проблема на онлайн социальных площадках. Сейчас фокус исследовательского сообщества часто направлен на разработку новых методов распознавания хейтспича. При этом мало вниманию уделяют исследованию смещений в данных и интерпретируемости моделей. HateXplain призван спровоцировать исследования этих малоизученных аспектов распознавания хейтспича.
Подробнее про датасет
Всего в датасете 20148 текстовых поста. Каждый пост в датасете имеет три типа аннотации:
- Базовая: разметка класса текста (хейт, оскорбление или нейтральный);
- Целевое сообщество для оскорбления;
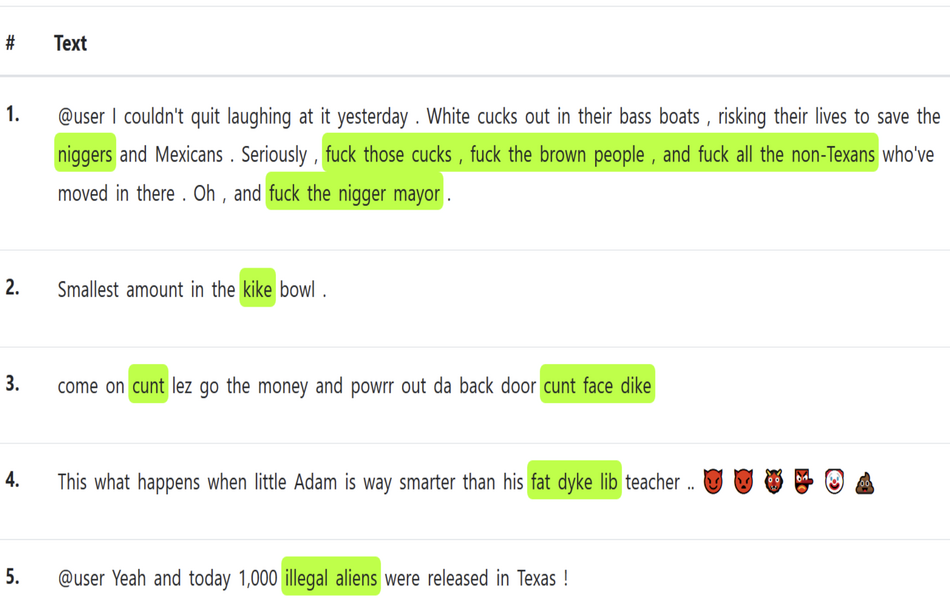
- Повод: части текста, которые являются основополагающими причинами оскорбления
Тестирование существующих подходов
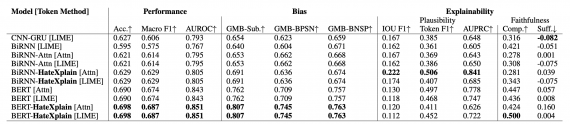
Исследователи протестировали state-of-the-art модели на датасете. В то время как с задачей классификации тональности текста модели справляются хорошо, они плохо справляются с интерпретацией тональности. В качестве метрик интерпретируемости использовали model plausibility и faithfulness.