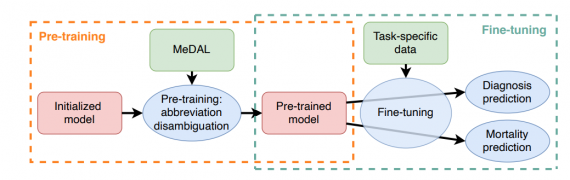
MeDAL — это датасет для расшифровки медицинских аббревиатур. Датасет собирали для предобучения моделей обработки естественного языка для медицинского домена. Данные опубликовали на воркшопе ClinicalNLP на конференции EMNLP.
По результатам экспериментов, предобучение на MeDAL улучшает предсказательную способность моделей на медицинских задачах и ускоряет сходимость на этапе дообучения.
Подробнее про датасет
Medical Dataset for Abbreviation Disambiguation for Natural Language Understanding (MeDAL) состоит из текстов 14,393,619 статей. Среднее количество аббревиатур в статье — 3.
MeDAL собирали из абстрактов статей на PubMed. PubMed — это поисковый сервис, который индексирует научные публикации биомедицинской тематики. Создатели использовали обратную замену для генерации примеров без человеческой разметки. В тексте находили полный термин, для которого была известна аббревиатура, и его заменяли на аббревиатуру. Чтобы не удалять из датасета все полные термины, термины заменяли на аббревиатуры с заданной вероятностью.