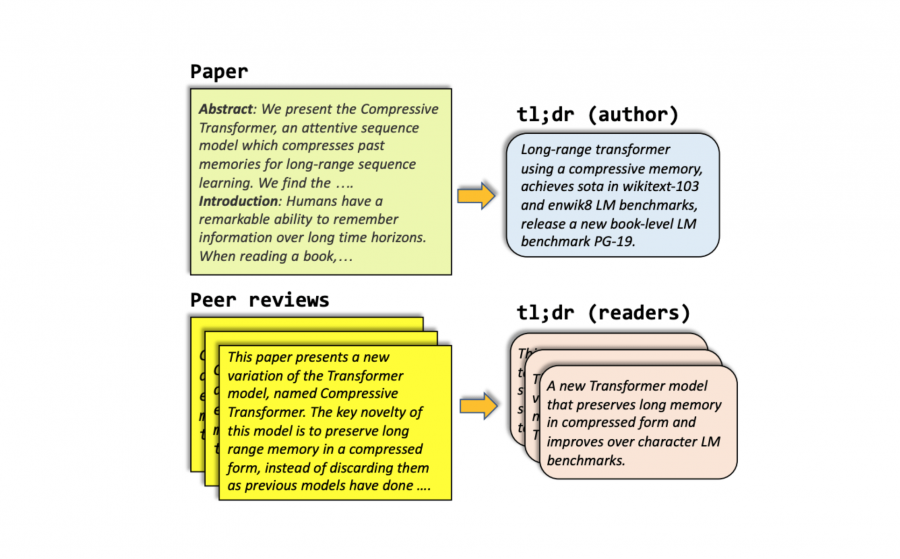
В AllenAI предложили новую задачу по автоматической генерации кратких выдержек из научных статей. Чтобы облегчить исследования на эту тему, исследователи опубликовали датасет SCITLDR. Датасет содержит 3.9 тысячи выдержки. Для каждой научной статьи в выборке присутствуют несколько выдержек: одна написана авторами статей, а другие вручную переписаны из комментариев рецензентов.
Подробнее про датасет
SCITLDR состоит из 3,935 кратких выдержек (TLDR) статей в области компьютерных наук. Научные статьи для датасета отбирали так, что бы они были по теме искусственного интеллекта и к ним был доступ на OpenReview. OpenReview — это популярная платформа для публикации статей, которая позволяет оставлять комментарии и вопросы к доступным статьям. SCITLDR включает 3,229 научных статей, каждая из которых содержит как минимум 1 выдержку от авторов статьи.
Большинство статей в OpenReview имеют краткую выдержку, которую писали сами авторы статей. Исследователи используют API OpenReview, чтобы собрать пары статья-выдержка и получить доступ к PDF-версии статьи. Затем они использовали метод из S2ORC для конвертации PDF в структурированный текст. После конвертации они применили ScispaCy для сегментации предложений. Меньше 5% из собранных статей не имели PDF-версии статей. В таком случае исследователи подавали абстракт статьи на вход модели, а не весь текст.
Датасет разделили на обучающую, валидационную и тестовую выборки в соотношении 60/20/20.

