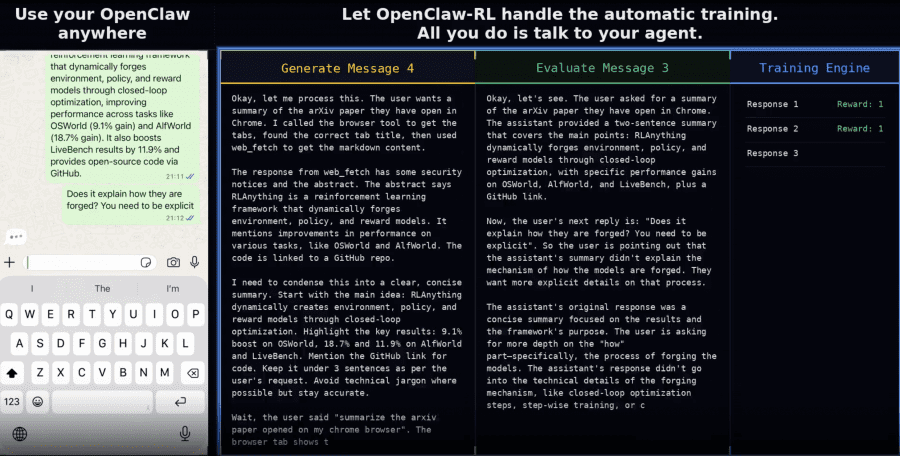
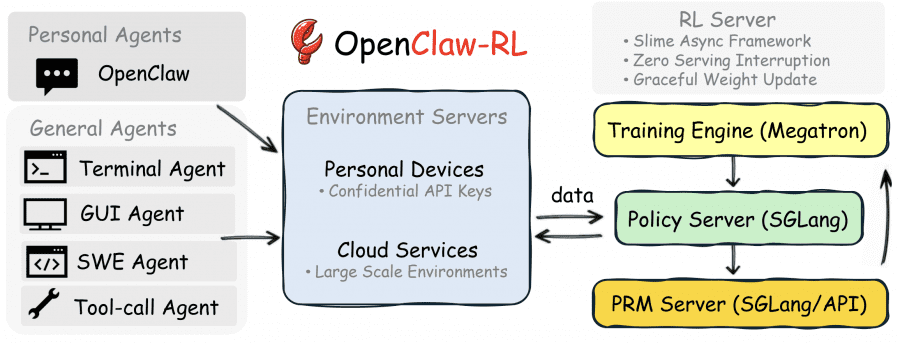
Исследователи из Princeton University предложили фреймворк OpenClaw-RL, позволяющий ИИ-агенту улучшаться в режиме реального времени — без отдельного этапа сбора данных и без ручной разметки. Большинство RL-фреймворков для языковых моделей работают в batch-режиме: сначала собирают датасет, потом обучают. OpenClaw-RL устроен иначе — модель, развёрнутая на собственной инфраструктуре, подключается через OpenClaw, и фреймворк обучает её непосредственно на живых разговорах, в фоне, не прерывая работу модели. Источником обучающего сигнала служат ответы среды на каждое действие агента.
OpenClaw реализует тот же формат запросов, что и OpenAI API, — это означает, что существующий код или инструменты, написанные под ChatGPT, заработают с OpenClaw без изменений: достаточно сменить базовый URL. Проект полностью открыт: код инфраструктуры опубликован на GitHub под лицензией Apache 2.0. Все компоненты доступны без закрытых зависимостей — эксперименты можно воспроизвести или адаптировать под собственного агента.
Нераскрытый потенциал сигналов взаимодействия
Каждое действие агента порождает ответ среды — next-state signal (сигнал следующего состояния): результат выполнения команды в терминале, изменение состояния графического интерфейса, ответ пользователя на реплику ассистента. Существующие агентные архитектуры используют этот сигнал исключительно как контекст для следующего шага, игнорируя его обучающий потенциал.
Авторы выделяют два вида информации, которые содержатся в next-state сигналах и систематически теряются.
Evaluative signals (оценочные сигналы) — неявная оценка качества предыдущего действия. Повторный вопрос пользователя сигнализирует о неудовлетворённости ответом, пройденный тест подтверждает корректность кода, сообщение об ошибке указывает на сбой. Такая оценка возникает бесплатно при любом взаимодействии и не требует отдельного аннотационного пайплайна.
Directive signals (направляющие сигналы) — конкретное указание на то, как действие должно было быть выполнено иначе. Если пользователь пишет «нужно было сначала проверить файл», это не просто негативная оценка — это информация на уровне токенов о том, какой ответ следовало сгенерировать. Скалярная награда (+1/−1), применяемая в стандартных RLVR-методах, уничтожает эту информацию полностью.
Архитектура OpenClaw-RL: четыре независимых компонента
Ключевой принцип OpenClaw-RL — полная асинхронность. Четыре компонента работают в независимых циклах без блокирующих зависимостей:
- Policy Server (SGLang) обслуживает входящие запросы;
- Environment Server принимает результаты взаимодействий;
- PRM Server оценивает качество каждого шага;
- Training Engine (Megatron) обновляет веса политики.
Пока тренировочный движок применяет градиенты, модель продолжает отвечать на новые запросы, а PRM оценивает предыдущие ответы — ни один компонент не ждёт завершения работы другого.
Такая архитектура решает практическую проблему длинных горизонтов: в агентских задачах один роллаут может занять десятки шагов, и синхронное ожидание его завершения блокировало бы весь пайплайн. Асинхронность позволяет накапливать обучающие сигналы из параллельных окружений без простоев.
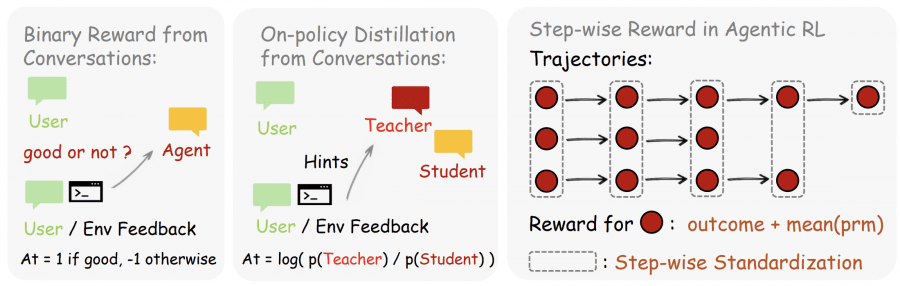
Два метода извлечения обучающего сигнала
Binary RL — оценочные сигналы как скалярная награда
PRM-судья (Process Reward Model — модель оценки процесса) получает на вход действие агента и следующее состояние среды, после чего выдаёт оценку: +1 (корректно), −1 (некорректно) или 0 (нейтрально). Для повышения надёжности запускают m параллельных независимых запросов к судье и принимают решение большинством голосов. Полученная оценка используется как advantage в стандартном PPO (Proximal Policy Optimization — оптимизация ближайшей политики) с асимметричными ограничениями: ε=0.2, ε_high=0.28, β_KL=0.02.
Метод охватывает все оцененные ходы и работает с любым типом сигнала — в том числе с неявными реакциями (пользователь просто повторил вопрос) или структурированными выводами среды (коды завершения, вердикты тестов). Ограничение подхода: всё содержательное богатство next-state сигнала сжимается до единственного числа.
Hindsight-Guided OPD — направляющие сигналы на уровне токенов
Метод конвертирует директивную часть next-state сигнала в пошаговое руководство на уровне токенов. Если пользователь написал «нужно было сначала проверить файл», эта фраза содержит информацию не только о том, что ответ был неверен, но и о том, какие токены следовало сгенерировать. Binary RL эту информацию теряет, OPD её сохраняет.
Алгоритм состоит из четырёх шагов. На первом судья анализирует ответ агента и следующее состояние, извлекая краткую «подсказку» — 1–3 предложения о том, что следовало сделать иначе. На втором среди всех полученных подсказок выбирается наиболее информативная, сэмплы без валидных подсказок отбрасываются — OPD намеренно жертвует объёмом выборки ради качества сигнала. На третьем подсказка добавляется к исходному промпту, формируя «улучшенный контекст учителя» (enhanced teacher context): та же модель теперь видит ситуацию так, как будто пользователь изначально дал более точную инструкцию. На четвёртом вычисляется разница log-вероятностей токенов между ответом модели в улучшенном контексте («учитель») и исходным ответом («студент»): Aₜ = log π_teacher(aₜ|s_enhanced) − log π_θ(aₜ|sₜ).
Знак advantage на уровне каждого токена указывает направление корректировки: положительное значение означает, что модель должна повысить вероятность данного токена, отрицательное — снизить. В отличие от скалярного advantage, разные токены одного ответа могут получать противоположные направления коррекции.
Персональный агент: обучение на разговорных сигналах
Авторы протестировали OpenClaw-RL на двух сценариях персонализации с ассистентом OpenClaw. Оба сценария реализованы как симуляция: роль пользователя выполняет языковая модель, которая взаимодействует с агентом-политикой. Базовая модель в обоих сценариях — Qwen3-4B, обучение запускается каждые 16 собранных обучающих сэмплов.
Сценарий «Студент»: агент помогает решать задачи из датасета GSM8K, при этом пользователь-студент требует, чтобы ответы не выглядели как сгенерированные ИИ — без структурированных шагов с жирным форматированием, без фразы «Final Answer», без характерного технического стиля.
Сценарий «Учитель»: агент проверяет домашние задания. Пользователь-учитель требует конкретных и доброжелательных комментариев — с указанием на то, что именно студент сделал правильно, а не формальной констатацией результата.
Примеры ответов агента до и после оптимизации в сценариях «Студент» и «Учитель». Слева — ответы с AI-like стилем (жирный текст, шаблонные фразы), справа — после 36 и 24 взаимодействий соответственно.

Результаты персонализации OpenClaw-RL
Авторы измеряли качество первого ответа агента на новую задачу — до того, как пользователь успел что-то уточнить. Оценивала та же модель-симулятор по шкале 0–1. Базовая оценка без персонализации составила 0.17 для сценария «Студент» и 0.22 для сценария «Учитель»; таблица ниже относится к сценарию «Студент».
| Метод | 8 шагов | 16 шагов |
|---|---|---|
| Binary RL | 0.25 | 0.23 |
| OPD | 0.25 | 0.72 |
| Combined (Binary + OPD) | 0.76 | 0.81 |
Binary RL даёт заметный прирост на начальных шагах, но быстро выходит на плато: оценка практически не растёт с 8-го по 16-й шаг. OPD демонстрирует замедленный старт — на 8 шагах результаты совпадают с Binary RL — однако затем резко ускоряется: к 16-му шагу оценка достигает 0.72. Задержка объясняется строгой фильтрацией: в обучение попадают только сэмплы с извлекаемыми директивными подсказками, что снижает объём выборки, но повышает плотность информации на сэмпл. Комбинированный метод показывает лучший результат на обоих временных горизонтах: Binary RL обеспечивает градиентное покрытие по всем ходам, OPD добавляет высокоточную токен-уровневую коррекцию на подмножестве сэмплов с направляющими сигналами.
Базовые оценки 0.17 и 0.22 отражают уровень Qwen3-4B без персонализации в сценариях «Студент» и «Учитель» соответственно. Рост до 0.81 за 16 взаимодействий означает, что агент адаптировался к специфическим предпочтениям конкретного пользователя без какой-либо ручной разметки.
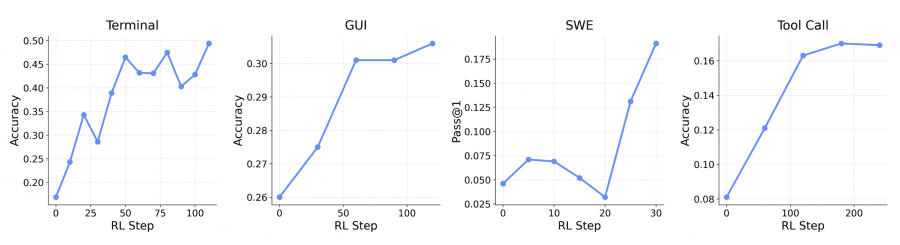
Общие агенты OpenClaw-RL: терминал, GUI, SWE, вызовы инструментов
Та же инфраструктура тестировалась на четырёх типах агентных задач с разными моделями и бенчмарками. Терминальный агент — Qwen3-8B, датасет SETA RL. GUI-агент — Qwen3VL-8B-Thinking, бенчмарк OSWorld-Verified. SWE-агент (разработка программного обеспечения) — Qwen3-32B, бенчмарк SWE-Bench-Verified. Tool-call-агент — Qwen3-4B-SFT на данных DAPO RL, оценка на олимпиадных математических задачах AIME 2024. Масштаб параллельных окружений: 128 для терминального агента, 64 для GUI и SWE, 32 для tool-call.
Интеграция пошаговых наград от PRM с итоговой наградой (outcome reward) стабильно улучшает результаты относительно обучения только на исходе траектории.
| Агент | Integrated (PRM + outcome) | Outcome only |
|---|---|---|
| Tool-call | 0.30 | 0.17 |
| GUI | 0.33 | 0.31 |
Для tool-call-агента прирост наиболее выражен: accuracy вырастает с 0.17 до 0.30. Для GUI-агента прирост меньше (0.31 → 0.33), что соответствует более короткому горизонту задач в этом сценарии. Содержательный компромисс — хостинг отдельного PRM-сервера требует дополнительных вычислительных ресурсов.
Что появилось после публикации пейпера
Репозиторий активно развивается: с момента выхода пейпера 10 марта 2026 года авторы добавили несколько важных возможностей.
LoRA. 12 марта добавлена поддержка LoRA-обучения — параметрически эффективного метода, при котором обновляются не все веса модели, а только малоразмерные адаптеры. Это снижает требования к памяти GPU и делает обучение доступным на менее мощном железе.
Tinker — обучение без GPU. 13 марта появилась поддержка облачного сервиса Tinker, который позволяет запустить RL-обучение вообще без локального GPU. Все три метода (Binary RL, OPD, Combined) поддерживаются через одну команду, например: python run.py --method combine --model-name Qwen/Qwen3-8B. Авторы оговариваются, что Tinker поддерживает только LoRA, что может уступать полному дообучению по качеству.
Минимальные требования для локального запуска. Стандартная конфигурация рассчитана на 8 GPU; количество настраивается через переменные окружения. Требования: CUDA 12.9, Python 3.12.
Все данные остаются локально. Вся инфраструктура — модель-политика, PRM-судья и тренировочный движок — запускается на собственном сервере пользователя. Данные разговоров не передаются в сторонние сервисы.
Сравнение с другими методами выравнивания
RLHF (Reinforcement Learning from Human Feedback — обучение с подкреплением на основе человеческих предпочтений) требует отдельного аннотационного пайплайна с участием разметчиков. OpenClaw-RL извлекает сигналы из живых взаимодействий без привлечения человека к разметке.
DPO (Direct Preference Optimization — прямая оптимизация предпочтений) предполагает наличие парных примеров предпочтительного и отвергнутого ответа, собранных заранее. OpenClaw-RL не требует ни пар, ни предсобранного датасета.
GRPO (Group Relative Policy Optimization) и смежные RLVR-методы работают в batch-режиме: сначала сбор данных, затем обучение. OpenClaw-RL обучается онлайн — без разделения фаз.
Стандартная дистилляция предполагает отдельную модель-учителя, превосходящую студента по качеству. В Hindsight-Guided OPD роль учителя и студента выполняет одна и та же модель: разница лишь в контексте — с подсказкой или без.
Практические следствия
Основной практический результат исследования — непрерывное онлайн-обучение из живых взаимодействий становится технически реализуемым без специализированной инфраструктуры для сбора данных. Вместо цикла «сбор данных → обучение → деплой → повтор» агент улучшается непосредственно в продакшене.
Для персональных агентов это означает, что адаптация к индивидуальным предпочтениям пользователя происходит автоматически в ходе обычного использования — без какого-либо технического участия пользователя.
Ограничения подхода: эксперименты с персональными агентами проводились только в симуляционном режиме, реальное поведение пользователей может существенно отличаться. Не все взаимодействия содержат извлекаемые направляющие сигналы, поэтому OPD работает на подмножестве сэмплов. Хостинг PRM создаёт дополнительную вычислительную нагрузку, особенно ощутимую в GUI-сценариях с мультимодальными судьями.