Google AI предложили автоматическую метрику BLEURT для оценки моделей генерации текста. BLEURT выдает более стабильные оценки, чем BLEU. Метрика доступна в открытом репозитории на GitHub.
Методы ручной оценки сгенерированных текстов являются ресурсозатратными, так как предлолагают наличие аннотаторов. Чтобы оптимизировать ресурсы на оценку моделей, на текущий момент наиболее популярны автоматические методы оценки. Однако стандартные автоматические метрики, как BLEU, являются ненадежной заменой человеческой интерпретации и оценке. BLEURT (Bilingual Evaluation Understudy with Representations from Transformers), в свою очередь, лучше коррелирует с человеческой оценкой. Метрика строится поверх transfer learning подхода к обучению моделей. BLEURT позволяет учитывать лингвистические феномены, как перефразирование.

Как работает BLEURT
BLEURT обучается на открытом наборе рейтингов, — WMT Metrics Shared Task. При этом пользователь может добавить дополнительные рейтинги для обучения. Пайплайн обучения BLEURT предполагает:
- Использование контекстных представлений слов из BERT;
- Новая схема предобучения для увеличения устойчивости метрики
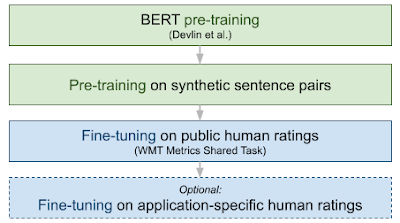
Ранее векторные представления из BERT уже использовались для оценки моделей: YiSi или BERTscore. BLEURT предобучается дважды. Сначала с использованием целевой функции языковой модели. Затем модель дообучается на датасете WMT Metrics, на наборе рейтингов пользователи или на комбинации этих двух наборов данных.

