ClawBench — бенчмарк, который проверяет, могут ли ИИ-агенты выполнять настоящие повседневные задачи в интернете: забронировать рейс, откликнуться на вакансию, оформить заказ. Результаты показали, что даже сильнейшая модель — Claude Sonnet 4.6 — справляется только с 33% задач. Это разительно расходится с результатами на традиционных бенчмарках, где ИИ-агенты набирают 65–75%. Код инфраструктуры оценки, задания и пайплайн опубликованы на GitHub, а датасеты и материалы доступны на сайте бенчмарка.
В чём проблема с существующими бенчмарками
Большинство популярных бенчмарков для веб-агентов — WebArena, OSWorld, VisualWebArena — тестируют модели в sandbox-окружениях. Это значит, что агент взаимодействует не с настоящим сайтом, а со статической HTML-копией с фиксированной DOM-структурой, без авторизации и динамического контента. Такие условия сильно упрощают задачу: на реальном сайте агент сталкивается с cookie-баннерами, JavaScript-рендерингом, капчами и многошаговыми формами.
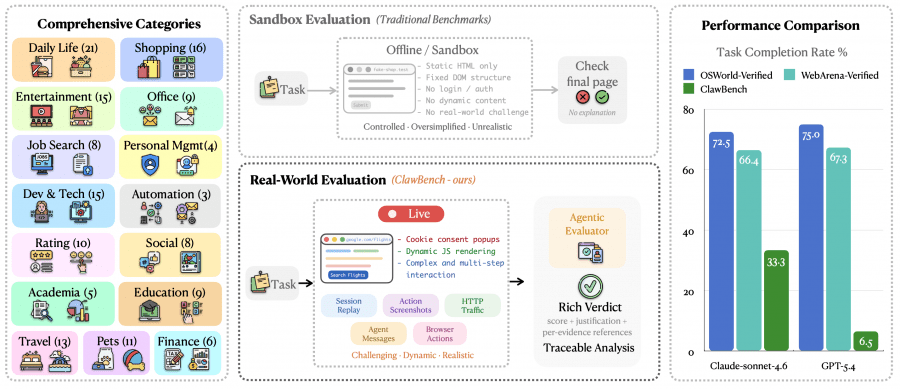
Кроме того, бенчмарки с реальными сайтами — WebVoyager, AssistantBench — проверяют только чтение и поиск информации. Записать что-то, отправить форму, совершить покупку — этого до ClawBench не тестировали систематически.
Как устроен ClawBench
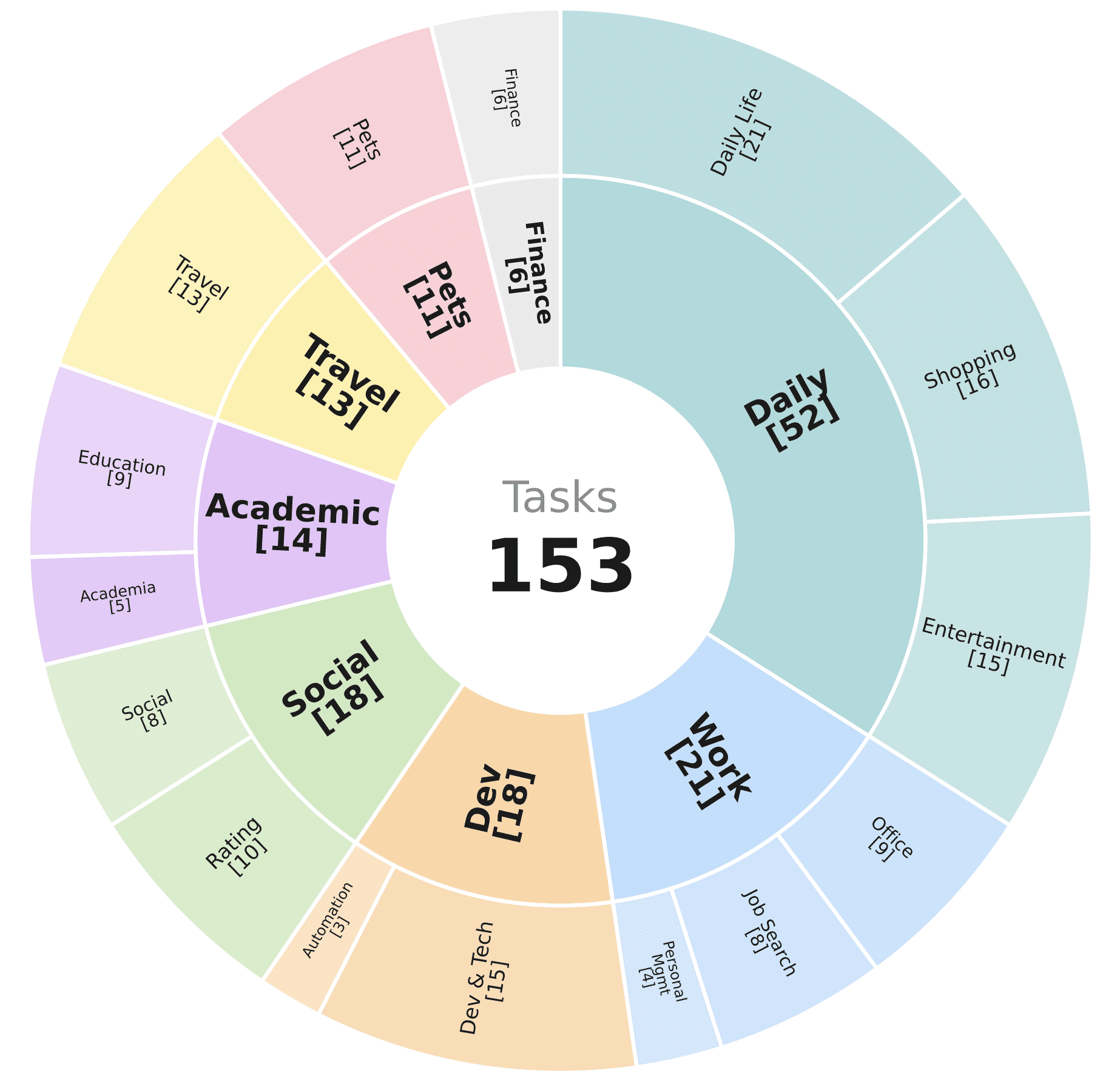
ClawBench содержит 153 задания на 144 реальных платформах, разбитых на 15 категорий: повседневная жизнь, шопинг, развлечения, офисные задачи, поиск работы, личный тайм-менеджмент, разработка и технологии, автоматизация, рейтинги и отзывы, социальные сети, академическая среда, образование, путешествия, домашние животные и финансы.
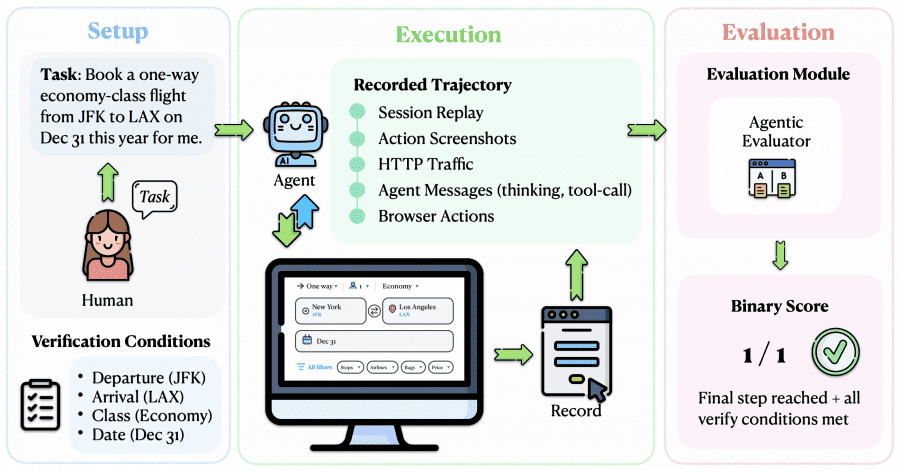
Каждое задание состоит из трёх элементов: инструкция на естественном языке (например, «забронируй перелёт из JFK в LAX на 31 декабря эконом-классом»), начальный URL и конкретный HTTP-запрос, которым должна завершиться задача. Люди-аннотаторы проходили каждое задание вручную, а их действия записывались как эталонная траектория.
Ключевая техническая особенность бенчмарка — механизм перехвата финального запроса. Чтобы агент не совершал реальные покупки или не отправлял настоящие заявки, исследователи разработали лёгкое расширение для Chrome и CDP-сервер (Chrome DevTools Protocol). Когда агент доходит до финального действия — нажимает «Оплатить» или «Отправить заявку» — расширение перехватывает HTTP-запрос до того, как он уходит на сервер, сохраняет тело запроса и блокирует отправку. В валидационном исследовании на всех 153 задачах механизм перехватил финальный запрос в 100% случаев без ложных срабатываний.
Пятислойная запись поведения
Каждый запуск агента фиксирует пять видов данных одновременно:
- запись сессии через Xvfb + FFmpeg (полное видео браузера);
- скриншоты после каждого действия;
- HTTP-трафик через Chrome DevTools Protocol;
- сообщения агента — цепочки рассуждений и вызовы инструментов в JSON;
- низкоуровневые действия браузера — клики, нажатия клавиш, скроллы.
Параллельно те же пять видов данных записываются для человека-аннотатора. Это позволяет сравнивать не просто финальный результат, а весь путь: на каком конкретно шаге агент сошёл с правильной траектории.
Как работает оценка
Оценку выполняет агентный ревьюер (Agentic Evaluator) — суб-агент на основе Claude Code, которому дают задание, эталонную траекторию человека и траекторию тестируемого агента. Ревьюер сопоставляет их пошагово, проверяет, правильно ли заполнены поля формы, и выносит бинарный вердикт: 0 или 1. При этом выдаётся структурированное обоснование — например, «departure = Toronto ✓, return_date = Aug 07 ✓, type = direct flight ✓».

Такой подход надёжнее, чем простая проверка финального URL или скриншота: он выявляет, что именно пошло не так, а не только факт неудачи.
Результаты семи моделей
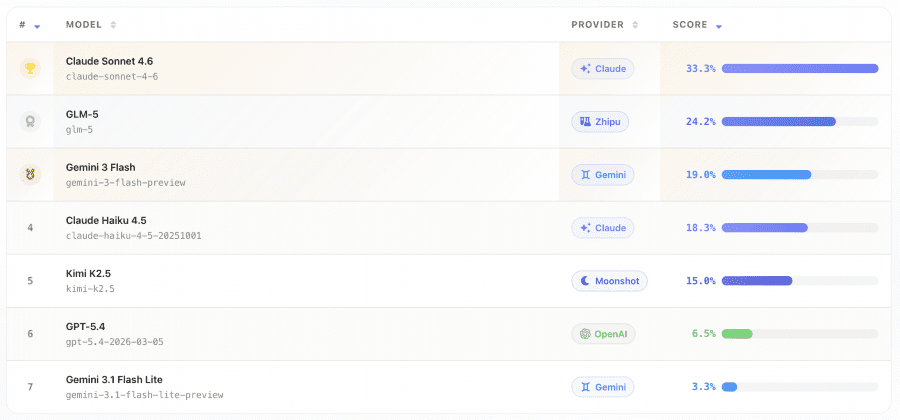
Протестировали семь моделей: Claude Sonnet 4.6, GPT-5.4, Gemini 3 Flash, Claude Haiku 4.5, Gemini 3.1 Flash Lite, GLM-5 и Kimi K2.5.
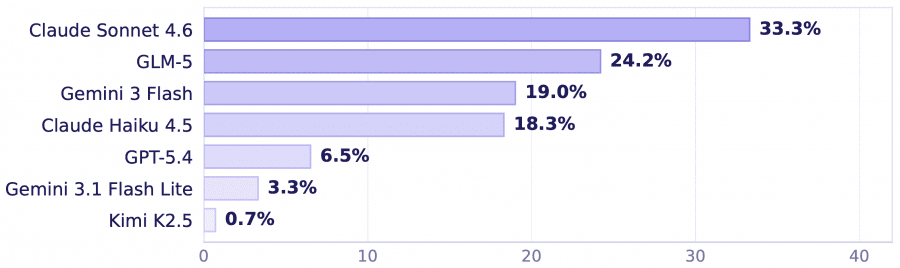
Лучший результат у Claude Sonnet 4.6 — 33.3%. GLM-5 на втором месте с 24.2%, Gemini 3 Flash — 19.0%, Claude Haiku 4.5 — 18.3%. GPT-5.4 справился лишь с 6.5% задач, Gemini 3.1 Flash Lite — с 3.3%, а Kimi K2.5 — с 0.7%.
Для сравнения: Claude Sonnet 4.6 набирает 72.5–75% на OSWorld и WebArena, GPT-5.4 — 67–72.5%. Разрыв хорошо показывает, насколько реальный интернет сложнее sandbox-окружений.
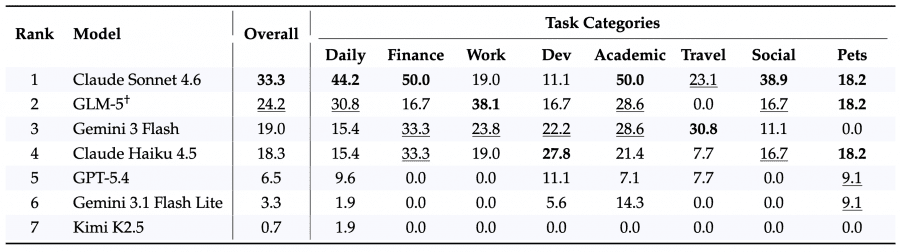
В финансах и академических задачах модели показывают наилучшие результаты: создание аккаунтов на инвестиционных платформах, подача заявок на страховку, запись на курсы Coursera и edX, отправка решений на LeetCode. В категории путешествий относительно хорошо выполняются бронирование билетов на FlixBus, поиск рейсов и аренда автомобилей.
Наибольшие затруднения вызывают задачи на разработку: создание репозитория на GitHub, форк huggingface/transformers, настройка Confluence или Airtable — в этой категории даже лидирующая модель Claude Sonnet 4.6 справляется только с 19% заданий. Социальные задачи также показывают низкие результаты: написание отзыва на Glassdoor, оценка на Vivino, чекин на Untappd — все они требуют точного заполнения многошаговых форм на живых сайтах с постоянно меняющейся структурой страниц. Kimi K2.5 не выполнил ни одного задания почти во всех категориях.
Насыщение старых бенчмарков
Интересный побочный вывод исследования — классические бенчмарки уже почти насыщены. Claude Sonnet 4.6 набирает 88% на PinchBench, 77.6% на WildClawBench, 72.5% на OSWorld-Verified и 66.4% на WebArena-Verified. На ClawBench она смогла набрать только 33.3%.

Это значит, что для исследователей и разработчиков агентов ClawBench сейчас — один из немногих бенчмарков, где есть большое пространство для роста.
Почему ClawBench — шаг вперёд
ClawBench — единственный бенчмарк, который одновременно работает на живых сайтах, тестирует задачи с отправкой данных (а не только чтение), оценивает агента путём сравнения с эталонным прохождением человека и фиксирует полную картину того, что агент видел, думал и делал на каждом шаге. Ни один из предшественников — WebArena, OSWorld, TheAgentCompany, Mind2Web — не совмещает всё это.
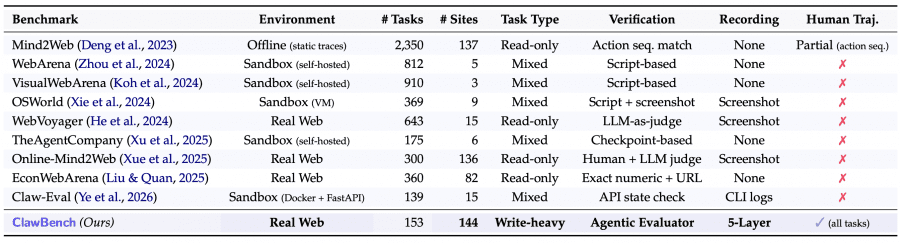
Принципиальное отличие ещё и в том, что большинство предыдущих бенчмарков смотрели только на последовательность действий или финальный URL. ClawBench проверяет реальные данные, которые агент собирался отправить на сервер — например, правильно ли он указал дату вылета, класс билета и маршрут при бронировании рейса.
Итог
ClawBench наглядно показывает разрыв между результатами на академических тестах и реальной работой в интернете. Модели, которые уверенно справляются с навигацией по статичным страницам, теряются на простых с точки зрения человека задачах: забронировать билет, оформить заказ, подать заявку на работу. Инфраструктура бенчмарка открыта, и по мере выхода новых моделей исследователи смогут отслеживать, как меняется этот разрыв.







