
CleanLab — это библиотека на Python для поиска неверно размеченных данных с помощью машинного обучения. Библиотека чистит данные от ложно присвоенных классов и помогает обучать модели на шумных данных. В основе библиотеки лежит теория уверенного обучения (confident learning).
Уверенное обучение
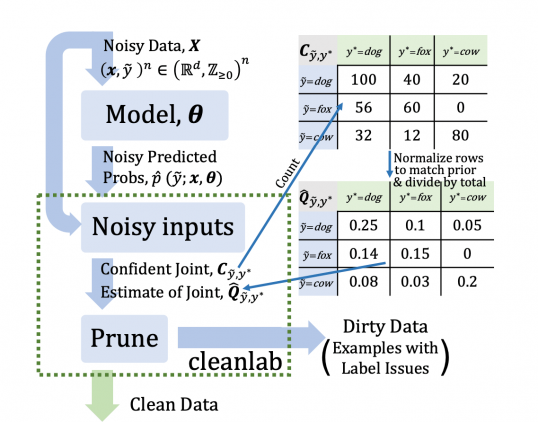
Уверенное обучение (CL) — это подход для поиска и классификации шумных данных. Подход заключается на принципах фильтрации шумных данных, которые позволяют оценить количество шума. CL также дает возможность проранжировать объекты в выборки в зависимости от уверенности в том, что объект можно использовать для обучения.
Исследователи отмечают, что ранее не анализировалась прямая оценка совместного распределения между шумными и чистыми данными. С помощью такой оценки получается достать информацию о количестве ошибок разметки для каждой пары реальных и шумных лейблов. Оценка совместного распределения также полезна для поиска проблем в датасетах. Например, исследователи нашли, что в ImageNet есть два класса для одного типа рубашки.
Итоговая процедура процедура CL — это набор алгоритмов для классификации ошибок в разметке. CL использует предсказанные вероятности и шумные данные для подсчета примеров в не нормализованном распределении, чтобы отфильтровать ошибки в разметке. На выходе CL модели отдают чистый датасет.
Концепция уверенного обучения имеет три преимущества перед предыдущими подходами:
- Прямая оценка совместного распределения шума разметки;
- Устойчивость работы против неравномерно распределенного шума в данных;
- Точечное распознавание ошибок разметки
Исследователи протестировали подход на задачах обучения с шумными данными и поиска шумных данных. Эксперименты показали прирост в качестве моделей при использовании CL подхода.
В GitHub репозитории проекта доступен тьюториал по уверенному обучению с использованием numpy и for-циклов.
Подробнее про библиотеку
CleanLab ищет и чистит ошибки в разметке целевой переменной в данных. Для поиска ошибок и шума используются state-of-the-art алгоритмы. В библиотеке реализованы оптимизированные алгоритмы, которые параллелизованы по потокам на CPU. CleanLab поддерживает мултиклассовые переменные и разреженные матрицы. Стандартная реализация библиотеки не требует подбора гиперпараметров.
