GANILLA — это архитектура генеративно-состязательной нейросети для перевода изображения в иллюстрацию. Исследователи предложили метрики для количественной оценки моделей на задаче перевода изображения в изображение. По результатам экспериментов, GANILLA обходит state-of-the-art подходы на задаче генерации иллюстрации из изображения. Код проекта доступен в репозитории на GitHub.
Исследователи использовали разрозненные данные из двух предметных областей для обучения модели: реальные изображения и иллюстрации. Датасет состоял из 9448 иллюстрации из 363 книг от 24 иллюстраторов и 5402 натуральных изображений из датасета CycleGAN.
Чтобы обучить модель балансировать между стилем и содержанием изображения, исследователи внесли две правки в существующие state-of-the-art подходы:
- Предложили новую архитектуру генератора, которая снижает размерность карты признаков на каждом остаточном слое;
- Чтобы лучше переносить содержание из входного изображения, они предложили объединять низкоуровневые признаки с высокоуровневыми с помощью скип-связей и апсемплинга
Обычно низкоуровневые признаки содержат информацию о границах входного изображения.
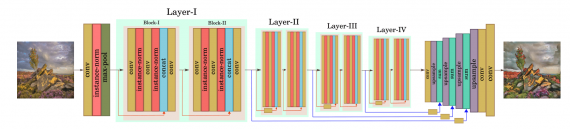
Архитектура модели
Генератор модели состоит из двух этапов:
- Этап понижения размерности (даунсемплинг), в основе которого лежит модифицированная ResNet-18;
- Этап повышения размерности (апсемплинг), когда низкоуровневые признаки через skip-связи используются для сохранения контента из входного изображения
Сеть дискриминатора — это PatchGAN размером 70 × 70.
Оценка работы модели
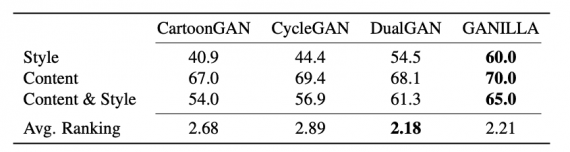
Чтобы оценить работу модели, исследователи сравнили ее с state-of-the-art подходами на датасете. Модель сравнивали с CartoonGAN, CycleGAN и DualGAN. Ниже видно, что, по результатам опроса, GANILLA генерирует изображения сравнимые или лучше, чем текущий state-of-the-art.