Задача сжатия размера изображения с минимальной потерей качества — это одна из актуальных проблем в компьютерном зрении. Для ее решения state-of-the-art подходом является использование GAN. Исследователи из Google Research проэкспериментировали с архитектурами GAN для сжатия изображений. Разработчики сравнивают виды нормализации, стратегии обучения, функции потерь и архитетуры генератора и дискриминатора. Предложенная отобранная модель (HiFiC), по результатам сравнений, более предпочтителен даже в случае, если прошлый подходы используют битрейт в два раза выше. Подход можно применять для изображений в высоком разрешении.
Архитектура нейросети
Ниже представлена структура модели, которая состоит из четырех компонентов:
- Кодировщик;
- Генератор;
- Вероятностная модель;
- Дискриминатор
ConvC — это свертка с C каналами; Norm — это LayerNorm; LReLU — это leaky ReLU активация, а Q означает квантизацию.

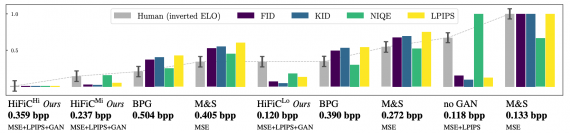
Тестирование HiFiC
Исследователи оценили модель количественным и качественным способами. Количественная оценка проводилась с помощью метрик FID, KID, NIQE, LPIPS, PSNR и MS-SSIM. Результаты, которые генерирует модель, соответствуют rate-distortion-perception теории.