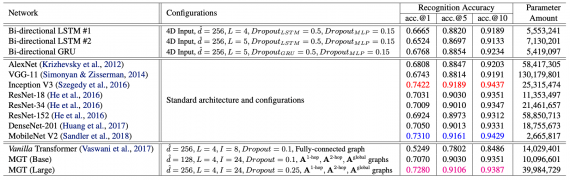
MGT — это архитектура нейросети, которая адаптирована для распознавания набросков. Модель обрабатывает наброски в виде графов. MGT выучивает геометрические и временные признаки рисунков. Предложенный подход протестировали на датасете Google QuickDraw. Результаты MGT сравнимы с подходом, основанном на CNN: 72.80% точность против 74.22%. При этом модель обошла подход, который основан на RNN. Исследователи заявляют, что ранее скетчи не представлялись в виде графов и не обрабатывались с помощью графовых архитектур.
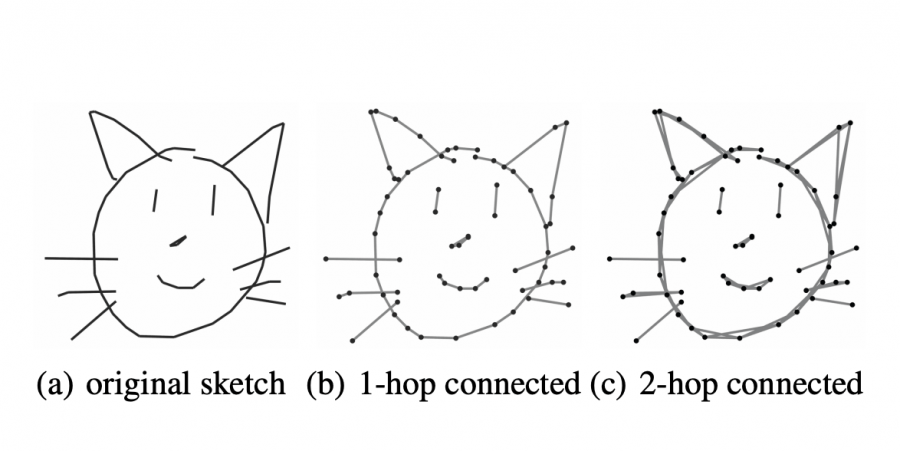
Обучение представлениям рисунков является сложной задачей из-за высокой абстрактности набросков и разреженности линий. Существующие подходы фокусируются на статичности скетчей с помощью сверточных сетей (CNNs). Помимо этого, скетчи могут рассматриваться как последовательности линий. Тогда для их представления используют рекуррентные сети (RNNs). Multi-Graph Transformer (MGT) работает со скетчами как с графами. Графы захватывают локальную и глобальную структуру линий наброска.
Как это работает
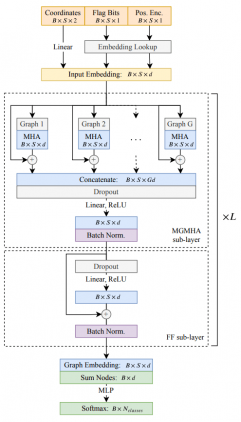
Архитектура MGT вдохновлена трансформером. Каждый слой в модели состоит из двух компонентов:
- Multi-Graph Multi-Head Attention (MGMHA): подслой с механизмом внимания;
- Полносвязный подслой с кодированием позиции (positional encoding)
Тестирование работы модели
Чтобы проверить работу MGT, исследователи взяли задачу распознавания скетчей на датасете Google QuickDraw. Google QuickDraw состоит из 414 тысяч изображений набросков. В качестве базовых моделей исследователи отобрали вариации state-of-the-art CNN архитектур и двунаправленные RNN. Ниже видно, что CNN-подходы выдавали более точные предсказания, чем MGT. Несмотря на это, MGT обошла RNN-подходы.