Роберт Уэст и Эрик Хорвиц сделали компьютерную игру, которая исследует, как возникает юмор. Игра показывает, как обычная фраза становится смешной на примере новостных заголовков. Игра помогла найти лексические и смысловые паттерны, связанные с созданием смешных фраз и предложений. Она поможет научить машины понимать шутки.
Ученые столкнулись с нехваткой обучающих датасетов с похожими предложениями, одно из которых было бы смешным, а другое нет. Это помогло бы преобразовать несмешное в смешное и наоборот, и понять, на чем строится юмор.
Игра — распознай реальный заголовок
Игра Unfun, созданная учеными из EPFL и Microsoft Research, отчасти решает эту проблему. Разработчики предложили пользователям преобразовать сатирические заголовки из журнала The Onion в серьезные новостные заголовки, изменив как можно меньше слов. В другой части игры участники должны распознать, перед ними реальный заголовок или нет.
Уэст и Хорвиц анализируют полученную базу данных, изучая, какая часть заголовка чаще изменяется, чтобы сделать из смешной фразы несмешную.
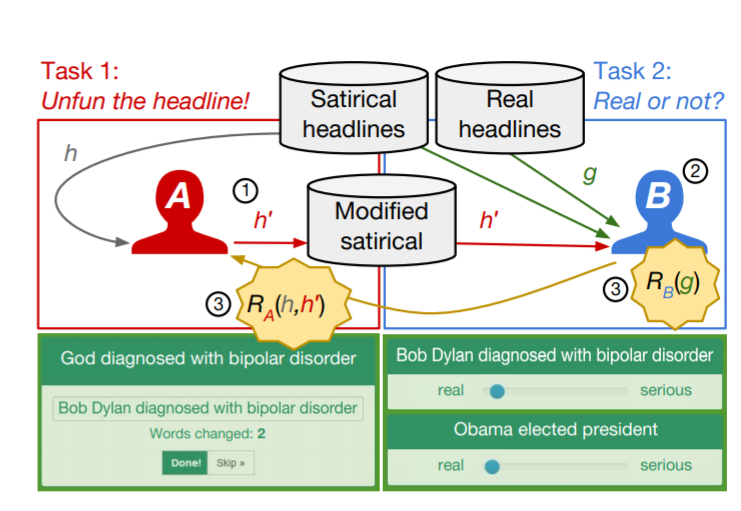
Заголовки, как правило, состоят из нескольких частей: субстантивные словосочетания (те, в которых главное слово — существительное), глагольные словосочетания, прилагательные и предлоги. Оказывается, субстантивное словосочетание — та часть предложения, которую чаще меняют, чтобы смешной заголовок стал несмешным.
Например, сатирический заголовок «Азиатские экономические проблемы вынуждает уволить 700 000 поп-звезд» можно легко сделать серьезным, заменив «поп-звезд» на «рабочих». Анализ показал, что обычно фразы, от которых зависит шутка находятся в конце предложений. Ученые назвали эти фразы микро-панчлайнами.
Разница между смешным и несмешным заголовком должна следовать особым правилам. Cогласно теории юмора, опубликованной Виктором Раскиным в 1985 году, два сценария должны быть противоположны друг другу. Один из двух сценариев должен быть возможным, другой — невозможным; один нормальным, другой — нет; один должен быть фактическим, другой — нематериальным.
В приведенном выше примере увольнение 700 000 рабочих возможно и реально, в то время как уволить 700 000 поп-звезд фактически невозможно и отследить это тоже невозможно. «Таким образом наши результаты подтверждают теорию эмпирически», — говорят исследователи.
По словам разработчиков, так же как и юмор, подобный механизм может исследовать другие явления — грубость, сексизм, эвфемизмы и прочее. Понимание, по каким законам формируются те или иные высказывания, поможет совершенствовать алгоритмы машинного перевода, а также лучше обучать голосовых помощников и чат-ботов.