
В Tencent AI разработали нейросетевой алгоритм для генерации аудиозаписи с пением человека на основе его обычного голоса. Алгоритм основывается на архитектуре DurIAN. Примеры сгенерированных аудиозаписей доступны по ссылке.
Предложенный алгоритм сначала интегрирует генерацию речи и пения в общий фреймворк, а затем выучивает эмбеддинги спикера. Эмбеддинги спикера в задачах генерации речи и пения разделяются. В общем фреймворке эмбеддинги спикера, которые модель выучила на данных обычной речи с помощью целевой функции для генерации речи, разделяются с теми эмбеддингами, которые были выучены по данным с пением с помощью целевой функции для генерации аудио с пением. Таким образом, выученные моделью эмбеддинги переносятся с задачи генерации речи на задачу генерации пения и обратно.
Как это работает
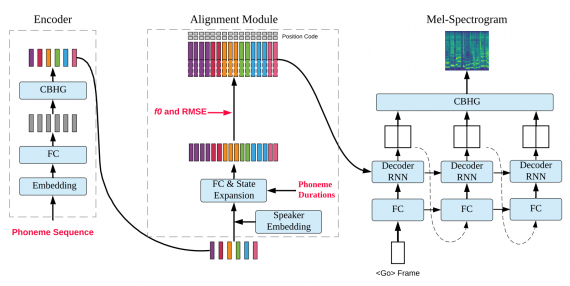
DurIAN based Speech and Singing Synthesis System (DurIAN-4S) алгоритм основан на ранее представленной архитектуре DurIAN. Изначально DurIAN был разработан для задачи мультимодальной генерации речи. Этот фреймворк может использоваться для других генеративных задач. Исследователи модифицировали оригинальную архитектуру DurIAN. Основное отличие DurIAN-4S от DurIAN — модель дополнительно принимает на вход атрибуты пения. Под атрибутами понимаются ноты, частота и другие характеристики, которые связаны с целевой аудиозаписью.
Архитектура DurIAN-4S включает в себя:
- Кодировщик, который кодирует контекст каждой фонемы;
- Модель, которая соотносит входную последовательность фонем с целевыми звуками;
- Авторегрессионный декодировщик, который последовательно генерирует целевую спектрограмму
Тестирование работы модели
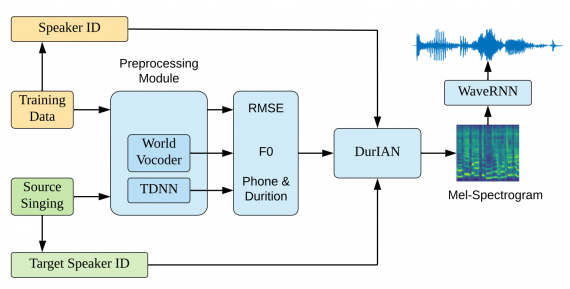
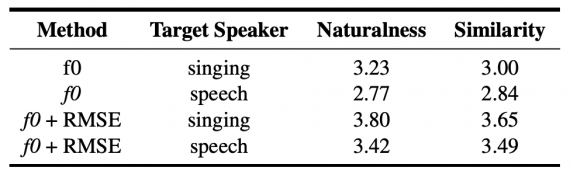
Исследователи протестировали предложенный алгоритм на задаче генерации пения. По результатам экспериментов, сгенерированные поющие голоса схожи с оригинальными голосами с обычным тоном.
В качестве обучающих данных исследователи выбрали Tencent multi-speaker speech corpus (TSP) и Tencent singing corpus (TSG). Из TSP корпуса взяли аудио трех спикеров-мужчин и 4 спикеров-женщин. Всего полтора часа аудиозаписей на каждого спикера. TSG датасет состоит из 28 часов пения трех певиц. Для задачи ковертации обычного голоса в пение отобрали отдельные данные, которые отсутствовали при обучении. В качестве метрики качества использовали Mean Opinion Score (MOS).
Ниже видно, что предложенный метод реалистично конвертирует обычный голос в поющий.



«»Нейросеть генерирует аудиозапись с пением на основе обычного голоса»» Вы хоть сами поняли что сказали? Откуда, чего, куда генерирует??!?!?!?!!