Исследователи из University of Rochester опубликовали нейросеть, которая генерирует видеозаписи с говорящими людьми на основе аудиозаписи. Предложенная модель генерирует более реалистичные видеозаписи, чем state-of-the-art подходы. При этом в нейросети эксплицитно генерируются движения головы человека.
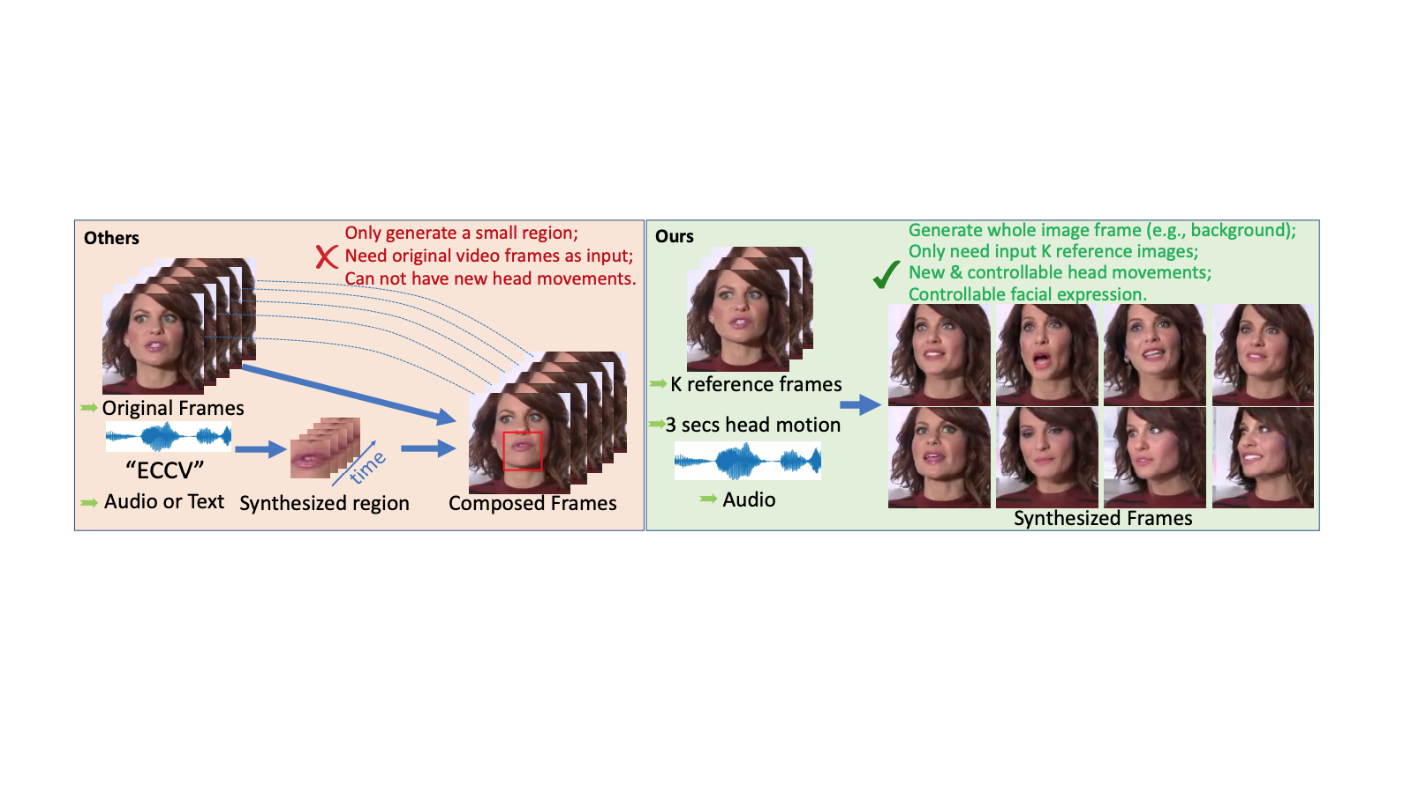
Когда люди разговаривают, их голова естественно двигается. Это ритмичное движение головы содержит просодическую информацию. Задача генерации видео, где человек одновременно двигает губами и головой, является сложной. Предыдущие подходы опираются на разметку частей лица или видеокадры для генерации движений головы. Это ведет к нереалистичности и бесконтрольности движений на сгенерированных записях. Чтобы обойти это ограничение, исследователи предлагают генеративную сеть, которая учитывает 3D структуру лица, вместе с гибридным модулем эмбеддингов и нелинейным модулем.
Подход моделирует движения головы и выражения лица напрямую, используя при этом 3D анимацию, и динамически кодирует референсные изображения. Это позволяет модели синтезировать фотореалистичные, последовательные и контролируемые видеозаписи.
Что внутри модели
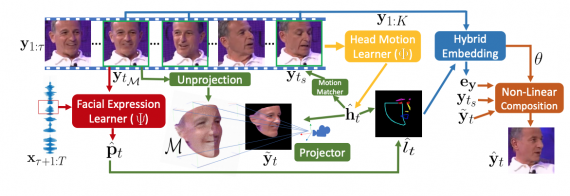
Чтобы напрямую моделировать выражения лица и движения головы, нейросеть использует три субмодуля:
- Модуль генерации выражения лица на основе аудиозаписи;
- Модуль генерации движения головы, который принимает на вход короткое референсное видео и аудиозапись;
- Сеть для генерации видеокадров, которая учитывает 3D структуру головы
Подход принимает на вход аудиозапись. На выходе модель отдает видеозапись с говорящей головой. Видеозапись полностью соотносится по содержанию с аудиозаписью.
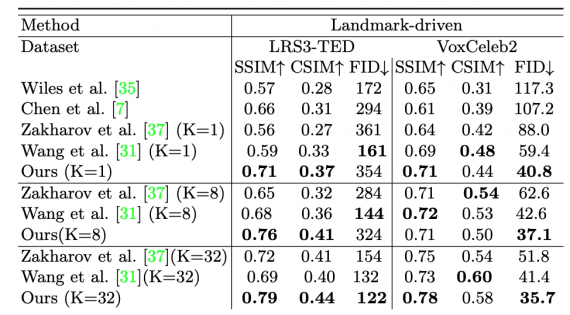
Оценка работы нейросети
Количественные эксперименты показывают, что предложенный подход генерирует более реалистичные видеозаписи в сравнении с state-of-the-art.