Google AI опубликовали нейросеть, которая извлекает структурированную информацию из шаблонных документов. В отличие от предыдущих подходов, модель использует знание о типах целевой информации, чтобы отобрать и проранжировать распознанные части текста в документе. Эксперименты на корпусах счетов и чеков показывают, что нейросеть генерализуется на типы документов, на которых не обучалась.
В чем проблема
Шаблонные документы, как чеки, счета и страховые квоты, имеют множество разных применений в бизнес-сфере. На данный момент обработка таких документов по большей части основывается на ручном труде. При этом существующие автоматизированные системы строятся на эвристиках, которые неустойчивы к ошибкам и расхождениям в формате документов. Исследователи предлагают нейросетевой подход для извлечения информации из шаблонных документов.
Как работает модель
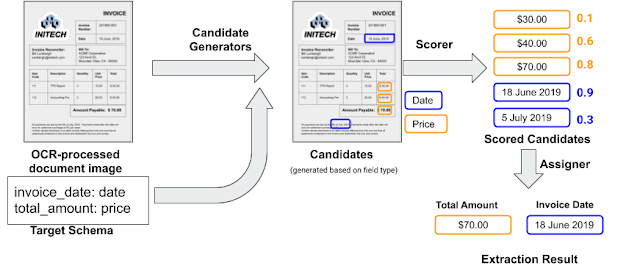
Предложенный подход позволяет разработчикам обучить и задеплоить систему по извлечению данных из документов определенного типа. Модель принимает на вход целевую схему, в которой содержится список полей для извлечения и их типы, и маленький набор размеченных документов.
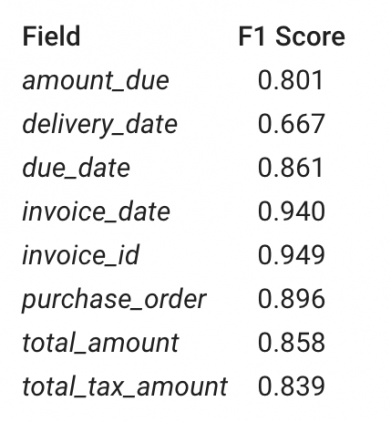
Модель извлекает данные следующих типов: даты, числа, цифро-буквенные коды, число со знаком валюты, телефонные номера и ссылки. Входной документ сначала проходит через сервис по распознаванию знаков (OCR). На этом этапе документ из формата PDF или изображения переводится в текстовый формат. Полученный текст прогоняется через генератор кандидатов, который отбирает потенциально нужные части текста. Кандидаты затем ранжируются с помощью нейросеть.
Оценка работы модели
Для обучения и проверки исследователи использовали датасет со счетами разных форматов. Тестировали систему на документах того формата, который модель ранее не видела.